Kompletní průvodce po CouchDB – II

Druhá kapitola Kompletního průvodce je věnována problematice konzistence dat, CAP teorému a principu, nazývanému „Eventual Consistency“ – přeložitelnému nejlépe jako „výsledná shoda“. Podíváme se podrobněji na to, jak CouchDB pracuje s verzemi dokumentů a jak řeší jejich konflikty. Relax.
Seriál: Kompletní průvodce po CouchDB (6 dílů)
- Kompletní průvodce po CouchDB – I 11. 4. 2011
- Kompletní průvodce po CouchDB – II 18. 4. 2011
- Kompletní průvodce po CouchDB – III 26. 4. 2011
- Kompletní průvodce po CouchDB – IV 2. 5. 2011
- Kompletní průvodce po CouchDB – V – Návrhové dokumenty 30. 5. 2011
- Kompletní průvodce po CouchDB – VI – Využití pohledů 27. 6. 2011
Výsledná shoda
V předchozí kapitole jsme si ukazovali, jak flexibilita CouchDB dovoluje rozvíjet data v závislosti na tom, jak se rozvíjí a roste celá naše aplikace. V této kapitole si ukážeme, jak nízkoúrovňový přístup k CouchDB zjednodušuje návrh aplikací a pomáhá vytvářet přirozeně škálovatelné distribuované systémy.
(Pozn. překl.: „Výsledná shoda“ není ideální překlad „Eventual Consistency“, ovšem zavedený český překlad jsem nenašel; je to kompromis, který vyjadřuje smysl originálního výrazu. Doslovný překlad by zněl „Nakonec shoda“, ale s takovým překladem nelze pracovat ve větě apod. „Výsledná shoda“ popisuje, co se s daty děje – „nakonec je výsledkem shoda“.)
Tento text je součástí překladu knihy CouchDB: The Definitive Guide. Stejně jako autoři originálu oceníme věcné připomínky a pomoc s textem, za které předem děkujeme.
Práce s jádrem
Distribuovaný systém je takový systém, který pracuje spolehlivě nad rozsáhlou sítí. Zvláštností síťových výpočetních systémů je, že síťová spojení mohou čas od času „zmizet“. Existuje řada strategií, jak se s takovou situací vypořádat. CouchDB na rozdíl od mnohých dalších přijímá princip „výsledné shody“ namísto upřednostňování naprosté shody před dostupností, jako je tomu u RDBMS či Paxosu. Tyto systémy sdílí obavy ze situace, že uživatelé, přistupující v jednu chvíli simultánně k určitému záznamu, dostanou rozdílná data. Jejich přístup se liší v tom, jaké aspekty z trojice shoda, dostupnost, odolnost upřednostňují.
Vytváření distribuovaných systémů je magie. Mnohé z překážek a pastí, kterým budete čelit, nejsou zrovna samozřejmé. Nemáme na všechny z nich řešení a CouchDB není panacea, ale když budete pracovat spolu s návrhem CouchDB, nikoli proti němu, tak vás cesta nejmenšího odporu dovede k přirozeně škálovatelným aplikacím.
Samosebou, budování distribuovaných systémů je jen začátek. Web s databází, která je dostupná jen polovinu času, je naprosto bezcenný. Naneštěstí vede tradiční přístup relačních databází ke konzistentnosti dat k tomu, že programátoři velmi snadno sklouznou k závislosti na globálním stavu, globálním časování a dalších věcech, aniž by si vůbec uvědomili, že to dělají. Předtím, než se podíváme na to, jak CouchDB podporuje škálování, podíváme se na omezení, která distribuované systémy kladou. Až si ukážeme problémy, které vzniknou ve chvíli, kdy se určitá část vaší aplikace nemůže spolehnout na to, že je neustále v kontaktu se zbytkem aplikace, ukáže se intuitivnost a použitelnost způsobu, jakým tuto situaci řeší CouchDB.
CAP teorém
CAP teorém popisuje několik odlišných přístupů k rozmístění aplikační logiky v systému. Přístup CouchDB je založen na replikaci, která šíří změny do jednotlivých uzlů. To je zásadně odlišný přístup v porovnání např. s relačními databázemi, které pracují s jinými prioritami v oblasti konzistentnosti, dostupnosti a odolnosti proti rozdělení.
CAP teorém, viz obr. 1, pracuje se třemi základními vlastnostmi:
- Consistency (konzistentnost, shoda)
- Všichni uživatelé databáze vidí ta samá data, i v případě protichůdných updatů.
- Availability (dostupnost)
- Vždy je možné získat nějakou verzi dat.
- Partition tolerance (odolnost proti rozdělení)
- Databáze je schopna korektně fungovat, i když je přerušena komunikace mezi jednotlivými servery.
Najednou si můžete vybrat pouze dvě.
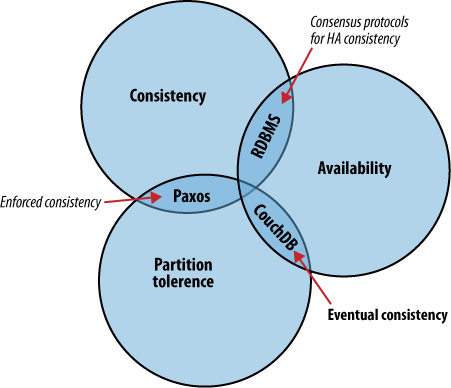
Obr. 1. CAP teorém
Když systém naroste za hranici, kdy jeden databázový stroj není schopen obsloužit všechny požadavky, je nejjednodušší řešení přidat další stroj. Když je přidáme, musíme se zamyslet nad tím, jak mezi ně rozdělíme data. Budeme mít několik databází, které budou sdílet stejná data? Umístíme na každý stroj jinou sadu dat? Nebo vyhradíme některé stroje pro zápis a jiné pro čtení?
Nezávisle na tom, jaký způsob vybereme, vždy narazíme na problém vzájemné synchronizace strojů. Jestliže zapíšete data do jednoho uzlu, jak se přesvědčíte, že se stejná data dostanou i do dalších uzlů? Takové přesuny zaberou řádově milisekundy. I s poměrně malou sadou serverů se problém synchronizace může stát extrémně složitým.
Když je naprosto nezbytné, aby všichni klienti viděli v jednu chvíli stejná data, budou muset uživatelé každého uzlu čekat na to, až bude změna rozšířena na ostatní uzly a zpětně potvrzená; do té doby nesmí zapisovat ani číst. V takové situaci je shoda dat na úkor dostupnosti. Ale jsou situace, kdy je dostupnost důležitější:
Každý uzel v systému by měl být schopen rozhodování čistě na základě svého lokálního stavu. Jakmile chcete něco udělat při velké zátěži, při výskytu chyb, a musíte čekat na potvrzení změn, jste ztracení. Pokud se soustředíte na škálovatelnost, bude jakýkoli postup, který vyžaduje potvrzování, vaším slabým místem. Berte to jako fakt.
—Werner Vogels, Amazon CTO and Vice President
Pokud je prioritou dostupnost, můžeme nechat uživatele zapisovat do uzlu a nečekat na potvrzení změn. Pokud má databáze postup, jak tyto operace rozšířit do ostatních uzlů a uvést do souladu, dostáváme se k určitému druhu „výsledné shody“, kde obětujeme okamžitou shodu dat na úkor dostupnosti. Je překvapivé, v jak velkém množství aplikací je tento přístup přijatelný.
Na rozdíl od tradičních relačních databází, kde každá změna podléhá kontrole konzistentnosti dat v celé databázi, nabízí CouchDB možnost tvořit aplikace, pro které není bezprostřední shoda dat klíčová, ale namísto toho potřebují velký výkon a snadnou distribuci dat.
Lokální shoda
Než se pokusíme vysvětlit, jak CouchDB pracuje v clusteru, je důležité ukázat si, jak uvnitř pracuje samostatný uzel CouchDB. API nabízí sice pohodlný, ale tenký wrapper okolo jádra databáze. Pokud pochopíme princip práce tohoto jádra, bude nám pochopitelnější i API, které ho obaluje.
Klíč k vašim datům
Srdcem CouchDB je B-tree úložiště. B-tree je utříděná datová struktura, která umožňuje hledání, vkládání a mazání dat v logaritmickém čase. Obrázek 2 ukazuje, jak CouchDB používá B-tree pro všechna vnitřní data, dokumenty a pohledy. Jakmile pochopíme jedno, pochopíme vše.
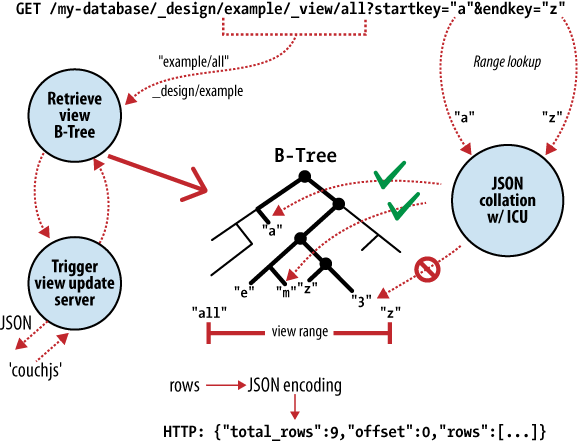
Obr. 2. Anatomie požadavku s view
CouchDB používá MapReduce algoritmus k výpočtu výsledku pohledu. MapReduce využívá dvě funkce, „map“ a „reduce“, které jsou aplikované na jednotlivé dokumenty samostatně. Jakmile jsme schopni tyto operace provádět izolovaně, znamená to, že je můžeme vykonávat paralelně a postupně. Ještě důležitější je, že výsledek těchto operací, který je opět ve tvaru klíč/hodnota, může CouchDB uložit do B-tree úložiště a indexovat podle klíče.Vyhledávání klíčů, nebo rozsahu klíčů, je s B-tree extrémně efektivní operace, popsaná pomocí zápisu s velkým O jako O(log N), resp. O(log N + K).
V CouchDB přistupujeme k dokumentům a výsledkům pohledů pomocí klíče nebo rozsahu klíčů. Tento přístup je přímo namapován na operace, které umí použité B-tree úložiště.Právě toto přímé mapování je důvodem, proč jsme hovořili o API jako o tenkém wrapperu okolo jádra databáze.
Samotná schopnost přistupovat k výsledkům přes klíče je velmi důležité omezení, které umožňuje obrovské zvýšení výkonu. Kromě růstu rychlosti můžeme data rozprostírat přes několik serverů, aniž bychom ovlivnili schopnost jednoho každého uzlu vrátit požadovaná data. BigTable, Hadoop, SimpleDB a memcached omezují vyhledávání v datech pomocí klíčů přesně z těchto důvodů.
Žádné zamykání
Tabulka v relační databázi je jednoduchá datová struktura. Pokud chcete modifikovat tabulku, řekněme změnit data v jednom řádku, musí se databázový stroj ujistit, že nikdo jiný nechce změnit tentýž řádek a že z něj po dobu, co se bude provádět změna, nebude nikdo číst. Běžný způsob řešení je takzvané zamykání. Pokud chce víc klientů najednou přistoupit k tabulce, zamkne první klient tabulku pro sebe, dokud změny neproběhnou, a ostatní musí čekat. Jakmile je první požadavek vyřízený, dostane výhradní přístup další klient a zbytek čeká, a tak dál. Takové postupné provádění požadavků, i když přišly najednou, představuje velké plýtvání procesorovým výkonem. Při velké zátěži dokáže relační databáze strávit víc času rozhodováním, kdo může co udělat a v jakém pořadí, než skutečnou prací.
CouchDB používá k ošetření souběžných přístupů místo zamykání takzvanou Multi-Version Concurrency Control (MVCC). Obrázek 3 ilustruje rozdíl mezi MVCC a klasickým zamykáním. MVCC umožňuje běžet CouchDB neustále na plný výkon, i při vysoké zátěži. Schopnost obsloužit souběžné požadavky najednou pomáhá vyždímat výkon procesoru do poslední kapky.
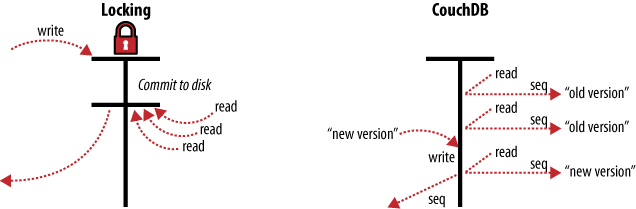
Obr. 3. MVCC nezamyká
Dokumenty jsou v CouchDB verzované, stejně jako by byly verzované v běžném systému pro správu verzí (Subversion, Git, …) Pokud chcete udělat nějakou změnu do dokumentu, vytvoří se nová verze tohoto dokumentu a přepíše tu starou. V tu chvíli máte dvě verze téhož dokumentu, jednu novou a jednu starou.
Jaká to je výhoda proti zamykání? Představte si množinu požadavků, co chtějí přistupovat k dokumentu. První požadavek čte dokument. Zatímco je zpracováván, přijde další požadavek, který ten dokument změní. Protože tím vytvoří novou verzi dokumentu, může to udělat hned, nemusí čekat, až první požadavek skončí.
Když pak přijde třetí požadavek na čtení téhož dokumentu, CouchDB ho nasměruje na novou verzi, která byla právě vytvořená. Po celou tu dobu může první požadavek stále číst starou verzi. Požadavek na čtení tak vždy uvidí tu poslední verzi, která je v daném okamžiku dostupná.
Ověřování
Coby vývojáři aplikací musíme promyslet, jaký typ vstupu přijmeme a jaký bychom měli odmítnout. Vyjadřovací schopnosti tradičních relačních databází nejsou schopné popsat mnohé z těchto kontrol, které by pracovaly nad komplexními daty. CouchDB nabízí možnosti, jak zkontrolovat dokument přímo v databázi.
CouchDB kontroluje dokumenty pomocí JavaScriptových funkcí, podobných těm pro MapReduce. Při každé změně dokumentu předá CouchDB kopii staré verze a kopii nové verze validační funkci, spolu s některými dalšími informacemi, jako jsou detaily o uživateli, který změnu provedl. Validační funkce má možnost změnu schválit nebo zamítnout.
Pokud budeme pracovat přímo s jádrem databáze a necháme tuto práci na CouchDB, ušetříme tím spoustu prostředků, které bychom jinak věnovali serializaci dat ze SQL, jejich transformaci na domain object a volání kontroly nad těmito objekty.
Distribuovaná shoda
Udržování datové konzistentnosti v jednom databázovém uzlu je snadné pro většinu databází. Opravdové problémy začnou ve chvíli, kdy chcete udržet shodná data přes několik uzlů. Když klient zapíše do databáze A, jak se ujistíme, že je zápis konzistentní se servery B, C nebo D? U relačních databází je to velmi komplexní problém, kterému jsou věnovány celé knihy. Můžete použít multi-master, master/slave, partitioning, sharding, write-through cache a řadu dalších technik.
Inkrementální replikace
Operace, které CouchDB dělá, jsou prováděné v kontextu jednotlivého dokumentu. Pokud použijete dva databázové uzly, nemusíte se starat o to, jestli jsou schopné neustále udržovat kontakt a komunikovat spolu. CouchDB dosáhne výsledné shody dat mezi těmito uzly pomocí inkrementální (postupné) replikace, což je proces, při němž jsou změny dokumentů pravidelně kopírovány mezi servery. Výsledkem je cluster, známý jako shared nothing, v němž je každý jednotlivý uzel nezávislý a soběstačný, takže není žádné „centrální“ zranitelné místo nebo situace.
Potřebujete zvýšit výkon databázového clusteru s CouchDB? Prostě přihoďte server.
Obrázek 4 ukazuje, jak díky inkrementální replikaci můžeme synchronizovat data mezi dvěma libovolnými databázemi, jak chceme a kdy chceme. Po replikaci je každá databáze schopná pracovat samostatně.
Můžeme tuto schopnost použít pro synchronizaci databázových serverů uvnitř clusteru stejně jako pro synchronizaci mezi datovými centry pomocí CRONu, nebo konečně můžete využít replikaci pro synchronizaci dat s notebookem, když se chystáte pracovat offline na cestách. Každá databáze může být použitá obvyklým způsobem a veškeré změny se synchronizují později.
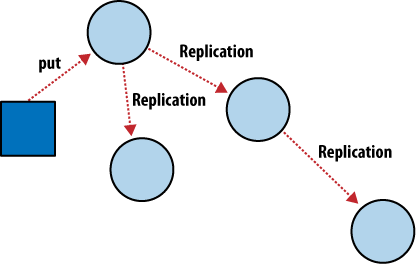
Obr 4. Inkrementální replikace mezi uzly
Co se stane, když změníte jeden a ten samý dokument ve dvou různých databázích a chcete je synchronizovat? Replikační systém v CouchDB nabízí postup, kterým automaticky takové konflikty detekuje a řeší.Když CouchDB zjistí, že se dokument změnil v obou databázích, označí je jako konfliktní verze, stejně jako v normálních verzovacích systémech.
Není to takový problém, jak se to může na první pohled zdát. Když jsou dvě verze jednoho dokumentu v konfliktu, je vítězná verze uložená jako aktuální, ovšem ta, která prohrála, není zahozená, jak byste očekávali. CouchDB ji uloží do historie verzí jako „předchozí“, takže se k ní dokážete dostat, když je potřeba. Toto se děje automaticky a konzistentně, takže obě databáze rozhodnou naprosto totožně.
Na vás je pak vyřešit konflikt takovým způsobem, který dává v aplikaci smysl. Můžete nechat dokumenty tak jak jsou, vrátit se k předchozí verzi, nebo se pokusit konfliktní verze sloučit a uložit výsledek.
Případová studie
Kamarád a spolupracovník Greg Borenstein napsal malou knihovnu, která převádí playlisty ze Songbirdu do JSON a rozhodl se ukládat je v CouchDB, jako takovou zálohu. Výsledný software používá MVCC a revize dokumentu k tomu, aby se ujistila, že playlisty Songbirdu jsou správně zaarchivovány a distribuovány mezi počítači.
Songbird je free přehrávač médií s integrovaným prohlížečem, založený na platformě XULRunner od Mozilly. Je k dispozici pro Windows, Mac OS X, Solaris i Linux.
Prozkoumejme fungování této aplikace, nejprve z pohledu člověka, co si zálohuje seznamy z jednoho počítače, a pak z hlediska možné synchronizace mezi počítači. Uvidíme jak revize dokumentů mění něco, co by mohlo být protivným problémem, na něco, co prostě funguje.
Když použijeme tuto aplikaci poprvé, nakrmíme ji svými seznamy písniček a spustíme zálohování. Každý playlist je převeden na JSON a předán CouchDB databázi. Jak ukazuje obrázek 5, databáze vrátí zpět ID a číslo revize pro každý playlist, uložený do databáze.
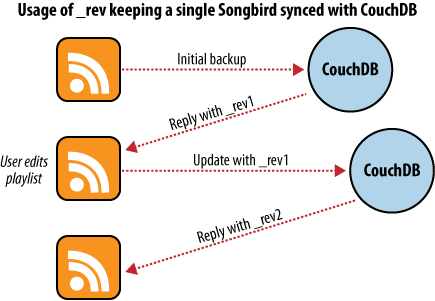
Obrázek 5. Zálohování do jedné databáze
Po několika dnech si uvědomíme, že jsme udělali nějaké změny, a chceme je opět zazálohovat. Předáme playlisty zálohovací aplikaci, ta si vyzvedne poslední verzi dokumentu z CouchDB a obdrží číslo revize. Když aplikace dokončí změny a posílá je serveru, požaduje CouchDB, aby toto číslo revize bylo součástí požadavku.
CouchDB totiž kontroluje, jestli číslo revize, předané v požadavku, odpovídá aktuální verzi, uložené v databázi. Protože CouchDB mění číslo revize při každé změně, naznačuje případný nesoulad těchto dvou čísel revizí (tedy aktuálního záznamu a požadavku), že někdo mezi převzetím záznamu a jeho posláním zpět udělal s dokumentem nějakou změnu. Změnit dokument poté, co ho někdo jiný upravil, aniž bychom se nejprve podívali na to, jaké změny udělal, je obvykle hloupý nápad.
Mechanismus, který nutí klienty dělat změny vždy do aktuální revize dokumentů je jádrem „optimistic concurrency“ v CouchDB.
Máme navíc notebook, který chceme synchronizovat se stolním PC. Když máme všechny seznamy písniček z desktopu zazálohované, můžeme na notebooku spustit „obnovení ze zálohy“. Je to první přístup, takže po této operaci bude na notebooku identická kopie seznamů.
Poté, co na notebooku vytvoříme seznam s argentinským tangem (koupili jsme si několik nových skladeb), bychom změny rádi uložili. Zálohovací aplikace vezme změny z notebooku a promítne je do dokumentu v CouchDB, přičemž vznikne nová revize. Pár dní nato si při práci na stolním PC vzpomeneme, že jsme dělali nějakou změnu, a chceme si zkopírovat nový seznam na PC. Zálohovací aplikace zkopíruje nový dokument s novou verzí na lokální CouchDB. Obě databáze tak mají teď stejná data („výsledná shoda“).
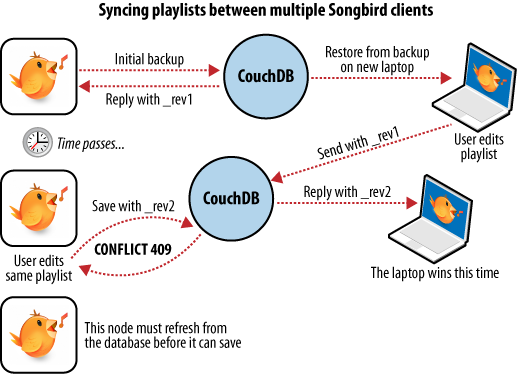
Obr. 6. Synchronizace mezi dvěma databázemi
Takovéto updaty mohou fungovat pouze v případě, že používají aktuální dokumenty, což zajišťuje právě sledování revizí dokumentů v CouchDB. Pokud uděláme změnu do dokumentu ve chvíli, kdy s ním pracuje někdo jiný, nebude to takto jednoduché.
Udělali jsme zase nějaké změny na notebooku a zapomněli je synchronizovat. Pak uděláme změny na stolním PC, zazálohujeme a chceme je synchronizovat na notebooku. Na obrázku 7 je vidět, co se v takovém případě stane: změny ze stolního PC jsou udělány na starší revizi dokumentu, než je ta v notebooku, a CouchDB hlásí konflikt revizí.
Řešení této chyby je z aplikačního hlediska prosté. Můžeme stáhnout konfliktní dokument a promítnout do něj lokální změny, nebo můžeme uložit lokální změnu jako nový playlist.
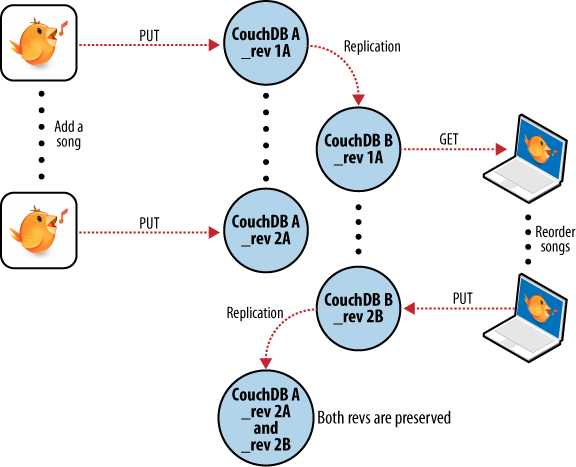
Obrázek 7. Synchronizační konflikt mezi dvěma databázemi
Souhrn
Návrh CouchDB si intenzivně vypůjčuje rysy webové architektury a kombinuje je s poučením z provozování obrovských distribuovaných systémů na této architektuře. Jakmile pochopíme důvody, proč tato architektura pracuje tak jak pracuje, a naučíme se určovat, které části aplikace mohou být snadno distribuované a které ne, pomůže nám to při vytváření distribuovaných a škálovatelných aplikací, ať už s CouchDB či bez ní.
Ukázali jsme si hlavní problémy okolo modelu konzistentnosti dat v CouchDB a připomněli některé výhody, které získáme, když budeme pracovat v souladu s duchem databáze, nikoli proti němu. Ale dosti teorie – v příští kapitole to celé nahodíme a podíváme se, zač je toho loket!
Martin Malý
Začal programovat v roce 1984 s programovatelnou kalkulačkou. Pokračoval k BASICu, assembleru Z80, Forthu, Pascalu, Céčku, dalším assemblerům, před časem v PHP a teď by rád neprogramoval a radši se věnoval starým počítačům.



Kdyz to prekladate, tak byste meli prelozit i ty obrazky.
Cast o zamykani tabulek u relacnich databazi je ponekud manipulativni. Verzovani pouzivaji jiz davno i relacni databaze a zadne zamykani celych tabulek se nekona, viz MVCC u PostgreSQL.