Polyglot aneb webovým kodérem pod obojí

Když se občas na přednáškách ptám, jakou verzi HTML posluchači používají, jsem vždy překvapen tím, že naprostá většina se hlásí k XHTML. Při bližším ohledání stránek tvůrců v XHTML však vyjde najevo, že káží víno a pijí špinavou vodu. Svůj validní XHTML kód podsouvají prohlížeči se špatným MIME typem text/html a nutí jej používat parser HTML. HTML5 přináší některé změny syntaxe, které konečně umožňují tuto praktiku dělat tak, abychom se za ni nemuseli stydět.
Nálepky:
Pro začátek si zase připomeneme pár historických faktů. Od počátku webu měly všechny prohlížeče k dispozici parser, který uměl načítat kód HTML a uměl se vypořádat i s běžnými syntaktickými chybami jako byly neukončené či překřížené elementy, neukončené hodnoty atributů atd. Dále v článku mu budeme říkat parser HTML.
S nástupem XHTML se do prohlížečů přidal ještě parser XML. Jakým parserem se stránka bude načítat, řídil MIME typ zasílaný do prohlížeče. Stránky označené pomocí text/html se zpracovávaly pomocí parseru HTML a stránky označené pomocí jednoho z MIME typů application/xhtml+xml, application/xml nebo text/xml se pak načítaly pomocí parseru XML.
Pro zájemce o XHTML vše vypadá jednoduše – napíší kód v XHTML, zajistí jeho odeslání se správným MIME typem a mohou být spokojení. Bohužel to není pravda – dosud stále majoritní prohlížeč Internet Explorer je schopný takovou stránku zobrazit až od 14. března 2011 (ano dva tisíce jedenáct, není to překlep) – data uvedení IE verze 9. Starší verze Internetu Exploreru místo zobrazení stránky zaslané jako application/xhtml+xml nabídly její uložení na disk. Věru nic praktického pro brouzdání po webu.
Jak se tento závažný nedostatek Internet Exploreru v posledních deseti letech řešil? Pragmatici nepřešli na XHTML, ale používali stále dál osvědčené HTML. Konec konců XHTML nepřineslo žádnou novou zajímavou funkcionalitu, kvůli které by stálo za to opustit HTML. Nicméně příchod XHTML byl spojen s několika nereálnými očekáváními a používání XHTML se stalo jistou módou. O praktické fungování XHTML v Internetu Exploreru (a v dalších starších prohlížečích, které nebyly aktualizovány o podporu XHTML) se zasloužila podobnost syntaxí HTML a XHTML.
XHTML dokument je totiž možné načíst pomocí parseru HTML. Spoléhá se přitom na to, že parser HTML umí sám opravit mnohé chyby v kódu. Když například v XHTML dokumentu použijeme <br/>, parser HTML lomítko vyhodnotí jako neznámý atribut a ignoruje jej. Je to poměrně brutální řešení, protože stránka zapsaná XHTML neodpovídá syntaxi HTML a není tak jisté, že všechny prohlížeče pochopí kód stejně a navíc tak, jak jsme chtěli.
Stalo se proto běžnou praxí, že XHTML stránky se odesílají do prohlížeče se špatným MIME typem text/html, aby fungovaly ve všech prohlížečích. V době, kdy to vypadalo, že IE přijde s podporou XHTML dříve než v roce 2011, některé weby dokonce posílaly různým prohlížečům různé MIME typy – alternativní prohlížeče podporující XHTML dostaly správný typ application/xhtml+xml; IE a neznámé prohlížeče pak dostaly zcela stejný dokument označený jako text/html. Dnes se tento přístup již moc nepoužívá – je to práce navíc a občas to zlobí s proxy servery – skoro všichni tak lžou a posílají XHTML jako text/html.
Zasílání XHTML se špatným MIME typem je v zásadě funkční, ale je potřeba dávat si pozor na některé detaily. Některé syntaktické konstrukce vedou k vytvoření rozdílného objektového modelu (DOM) v prohlížeči, pokud se čtou HTML respektive XML parserem. V praxi se to může projevit lehce odlišným zobrazením nebo chybami při běhu skriptu. Jeden jednoduchý příklad za všechny. Prázdný element <br/> lze v XHTML zapsat i jako:
<br></br>
ukázat DOM
Při načítání pomocí parseru XML se vytvoří jeden element br . Při načítání pomocí parseru HTML se však vytvoří dva elementy br . Součástí specifikace XHTML je příloha C, která na podobné problémy upozorňuje.
Posílání XHTML s MIME typem text/html při dodržení několika pravidel funguje, nicméně bychom z takového přístupu neměli mít dobrý pocit. Prohlížeč nutíme načítat nevalidní HTML a nemáme 100% jistotu, že prohlížeč bude správně interpretovat náš kód.
Východiskem z této nemilé situace je HTML5. Jak jsme si již řekli v minulém článku, HTML5 velice precizně definuje chování parseru HTML, takže se předchází rozdílné interpretaci chybného kódu různými prohlížeči. Navíc byla syntaxe HTML rozšířena tak, aby více odpovídala XML. Jednou z nejviditelnějších změn je povolení lomítka na konci prázdného elementu. Následující kód je tak nyní zcela validní i při použití HTML syntaxe (všimněte si zejména elementů meta a br):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Pokusná stránka</title>
</head>
<body>
<h1>Test<br/>1</h1>
</body>
</html>
ukázat DOM
Navíc vzniká separátní specifikace Polyglot Markup: HTML-Compatible XHTML Documents, jejímž cílem je definovat společnou podmnožinu syntaxe HTML a XML, která zajistí vytvoření stejného DOM při čtení parserem HTML i XML. Díky změnám v syntaxi HTML5 tak polyglot dokument může být zároveň validní HTML dokument a well-formed XML dokument. Konečně tak máme k dispozici postup, jak XHTML5 publikovat s MIME typem text/html a přitom mít výsledek funkční i formálně korektní.
V následují části textu se podíváme na jednotlivá pravidla, která je potřeba dodržet, aby náš dokument byl ten správný polyglot.
Na první pohled je samozřejmě polyglot dokument bližší XHTML5, protože to má striktnější syntaxi než HTML. Pravidla pro polyglot dokumenty tak v podstatě definují podmnožinu syntaktických konstruktů XHTML5 (resp. XML), které lze používat.
Prolog a kódování
Polyglot dokument nesmí obsahovat deklaraci XML:
<?xml version="1.0" encoding="utf-8"?>
Je to dáno tím, že parsery HTML tento konstrukt neznají. Dokument XML bez této deklarace však může používat jen kódování UTF-8 nebo UTF-16. V prostředí internetové komunikace má UTF-16 svoje problémy, takže polyglot dokument musí být vždy uložen v kódování UTF-8. Použité kódování musíme pro parser HTML identifikovat pomocí odpovídajícího elementu meta :
<meta charset="utf-8"/>
V ideálním případě bychom měli kódování indikovat navíc ještě zapsáním speciálního znaku BOM (Byte Order Mark) na začátek souboru.
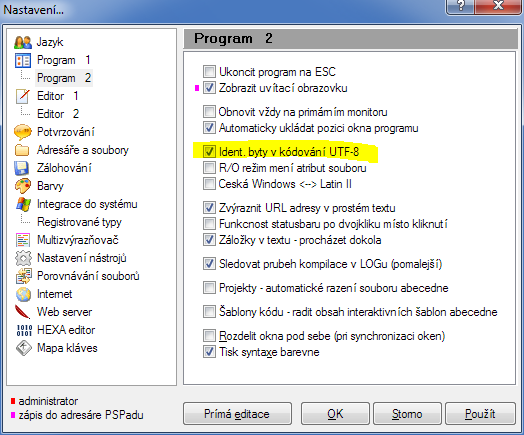
Nastavení kódování UTF-8+BOM v oblíbeném editoru PSPad
Samotný výběr kódování je jednoduchý, stačí v menu vybrat Formát → UTF-8. Aby PSPad zapisoval na začátek souborů v kódování UTF-8 i BOM, musíme aktivovat speciální parametr. Otevřeme dialog pro nastavení programu pomocí Nastavení → Nastavení programu… a v sekci Program 2 zaškrtneme volbu Ident. byty v kódování UTF-8.
Poznámka
Pokud PSPad používáte i pro editování skriptů PHP v kódování UTF-8, dejte si pozor na to, abyste volbu před prací s PHP zase vypnuli. PHP si bez speciální konfigurace se znakem BOM moc nerozumí.
Na začátku dokumentu musíme uvést deklaraci typu dokumentu ve tvaru:
<!DOCTYPE html>
Deklarace slouží k tomu, aby se při použití parseru HTML přepnul prohlížeč do striktního zobrazovacího režimu, kdy interpretuje kaskádové styly v souladu s doporučeními W3C. Důležité je zachovat správnou velikost písmen u řetězců DOCTYPE a html – XML na rozdíl od HTML je na tomto místě citlivé na velikost písmen.
Naše dosavadní znalosti můžeme shrnout do jednoduché kostry polyglot dokumentu:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8"/>
<title>Pokusná „polyglot“ stránka</title>
</head>
<body>
<p>Příliš žluťoučký kůň úpěl ďábelské ódy</p>
</body>
</html>
ukázat DOM
Jmenné prostory
Polyglot dokument na rozdíl od plnokrevného XHTML může používat pouze jmenný prostor pro HTML, SVG a MathML. Ten navíc musí být deklarován vždy pouze na elementu html (resp. svg či math) jako výchozí jmenný prostor. V praxi tak musíme deklaraci jmenného prostoru uvádět pouze na elementu html .
<html xmlns="http://www.w3.org/1999/xhtml">
Zápis elementů a atributů
Zatímco v HTML lze názvy elementů a atributů zapisovat libovolně malými i velkými písmeny, případně jejich kombinací, v polyglot dokumentu je nutné vždy používat pouze malá písmena. Takže zatímco v HTML je možné psát následující kód
<P claSS=note>Text</p>
ukázat DOM
V polyglot dokumentu se musíme držet více při zemi
<p class="note">Text</p>
ukázat DOM
Zároveň vidíme, že hodnotu atributů je vždy nutné uzavírat do uvozovek (případně apostrofů).
Syntaxe pro zápis prázdných elementů ( <element/>) musí být používána výhradně pro následující prázdné elementy: area , base , br , col , command , embed , hr , img , input , keygen , link , meta , param , source . Tyto elementy zároveň nesmí být nikdy zapsány jako dvojice počátečního a koncového tagu. Nepřípustné jsou tak například zápisy
<br></br> <hr></hr>
ukázat DOM
Korektní zápis je
<br/> <hr/>
ukázat DOM
Pokud máme v dokumentu prázdný jakýkoliv jiný element, musí se naopak zapisovat pomocí počátečního i koncového tagu, tedy místo <p/> musíme vždy použít <p></p>.
Při použití parseru HTML se do DOMu automaticky doplňující chybějící elementytbody a colgroup . Proto je potřeba vždy řádky tabulkytr obalit odpovídajícím elementem tbody .
U atributů obsahujících logickou hodnotu, se neuvádí jen jméno atributu jako v HTML, ale jako hodnota atributu se uvede jeho jméno. Takže například místo
<input type=checkbox checked>
ukázat DOM
Bude polyglot dokument obsahovat
<input type="checkbox" checked="checked"/>
ukázat DOM
Určení jazyka
Jazyk dokumentu musíme vždy určovat pomocí obou dvou atributů lang a xml:lang najednou, navíc musí vždy obsahovat shodnou hodnotu.
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" lang="cs" xml:lang="cs">
<head>
<meta charset="utf-8"/>
<title>Pokusná „polyglot“ stránka</title>
</head>
<body>
<p>Příliš žluťoučký kůň úpěl ďábelské ódy</p>
</body>
</html>
ukázat DOM
Entity
Polyglot dokument může používat jen pět předdefinovaných entit XML – <, &, >, ' a ". Další desítky entit známé z HTML nejsou k dispozici. Speciální znaky tak musíme zapisovat buď přímo, pomocí „chytré“ klávesnice nebo aplikace typu „Mapa znaků“, případně se na znak odvolat jeho číselným kódem Unicode. Tak například znak © dostupný v HTML pomocí entity © můžeme zapsat následujícími třemi způsoby
© © ©
Bílé znaky
Mezi jazyky HTML a XML existují drobné odlišnosti v chápaní bílých znaků (mezery, tabelátory, konce řádků) a to je potřeba v polyglot dokumentu zohlednit. Obsah elementů textarea a pre musí začínat hned za počátečním tagem bez vloženého konce řádky, jinak se na výstupu objeví prázdný řádek navíc.
| Špatný zápis | Správný zápis | Alternativní správný zápis |
|---|---|---|
<pre> var x = 10; window.alert(x); </pre> |
<pre>var x = 10; window.alert(x); </pre> |
<pre>var x = 10; window.alert(x);</pre> |
Pokud z nějakého důvodu potřebujeme do atributu zapsat znak tabelátoru nebo konce řádku, nemůžeme jej zapsat přímo, ale musíme jej zapsat pomocí odkazu na číselnou entitu.
Skripty a styly
V XHTML a tím pádem ani v polyglot dokumentech se nesmí používat javascriptové volání document.write(). Lze to obejít použitím vlastnosti innerHTML. Pozor však na to, že obsah elementuscript nesmí obsahovat znaky < a &.
Důsledkem toho všeho je, že některé „javascriptové kousky“ si musíme v polyglot dokumentech odpustit. Nelze používat document.write():
<script>
// nelze použít v polyglot dokumentu
document.write("<p style='color: blue'>Ahoj</p>");
</script>
Tento skript však nelze obejít ani pomocí innerHTML, protože uvnitř elementu script se nesmí používat < a &:
<div id="kontejner"></div>
<script>
// nelze použít v polyglot dokumentu
document.getElementById('kontejner').innerHTML = "<p style='color: blue'>Ahoj</p>";
</script>
Podobné případy můžeme obejít pouze ruční konstrukcí DOMu z jednotlivých uzlů, například:
<div id="kontejner"></div>
<script>
var p = document.createElementNS("http://www.w3.org/1999/xhtml", "p");
p.setAttribute("style", "color: blue");
var t = document.createTextNode("Ahoj");
p.appendChild(t);
document.getElementById('kontejner').appendChild(p);
</script>
Abychom se všem výše uvedeným problémům vyhnuli, je nejlepší veškeré skripty umístit externě do samostatných souborů a do stránky je načítat pomocí
<script src="URL skriptu"> </script>
Ze stejných důvodů je jistější i kaskádové styly připojovat jako externí pomocí element link .
Má cenu vytvářet polyglot dokumenty?
Asi vás zklamu, ale většinou ne. Jediný případ je ten, kdy stránky musí jít zpracovat pomocí existujících nástrojů založených na XML. Máte třeba přísný firemní CMS vyžadující použití XHTML, ale zároveň chcete jít s dobou HTML5, pak může mít polyglot dokument své opodstatnění.
Argumentem pro polyglot dokument bývá, že jej lze snadno načítat jako XML a dále zpracovávat. To je pravda, ale upřímně neděje se to tak často. Pokud někdo takové věci potřebuje dělat, může využít některou z existujících implementací parseru HTML5, které dokument HTML vrací jako kdyby to byl XHTML dokument a lze ji předřadit před další řetězec automatického zpracování založeného na XML.
Parsery HTML5 vracející výstup jako XML
- The Validator.nu HTML Parser pro Javu
- html5lib pro Python a PHP
Největším uživatelem polyglot dokumentů tak budou patrně ti webmasteři, kteří stále věří XHTML nebo po nich XHTML vyžaduje zákazník. S pravidly pro polyglot dokumenty lze konečně vytvářet stránky, které fungují v prohlížečích a zároveň vyhovují aktuálním specifikacím.



Nesouhlasím s autorem v tom, že „v ideálním případě byste měli přidat BOM“. Pro mě je to binární smetí, které řada editorů zobrazí, které dokáže rozhodit PHP interpretr (neptejte se mě jak, uložil jsem si do paměti jen, že to zlobí, ale nenamáhal jsem se zapamatovat si jak to zlobí) a hlavně je to při UTF-8 zbytečné a nedoporučené. Dále viz http://en.wikipedia.org/wiki/Byte_order_mark.
Bylo by dobré odlišit obecné použití BOM od použití v polyglot dokumentech. Použití BOM (a konec konců celý polyglot dokument) není výmysl autora článku, ale nepěkná situace, která kumuluje různé chyby a okolnosti posledních 15 let, a snaží se z nich vybruslit. Pro podrobnosti můžete zapátrat v originální specifikaci HTML5 a Polyglot.
Kromě svých problémů má BOM i své výhody:
– umožňuje správně určit kódování editorům, které nic nevědí o HTML5 a nerozumí <meta charset=“…“/> a nepoužívají UTF-8 jako default – například Notepad
– umožňuje vytvořit HTML5 dokument bez <meta charset=“…“/> – z historických důvodů a kvůli zpětné kompatibilitě s HTML4/HTTP je výchozí kódování v HTML5 US-ASCII a nikoliv UTF-8
O problémech PHP a BOM viz strana 18 v http://www.kosek.cz/knihy/phpxml/php5xml-unicode.pdf
Když jsem začínal s PHP, BOM pro mě byl největší problém. Teda problém bylo to, zjistit, že ty znaky na konci souborů při include dělá BOM.
BOM je bordel, bez něj má UTF-8 všechny dobré vlastnosti ASCII kromě pevného počtu bajtů na znak. Autor myšlenky přenést tento bordel z UTF-16 i na UTF-8 by zasloužil nějaký pikantní trest.
Pokud se používá BOM v UTF-8, kde mimochodem nemá co dělat, tak už nefunguje správně ani konkatenace řetězců/souborů, natož nějaký INCLUDE.
BOM by měl být všude a povinně, jinak musí každý to kódování většit. Na meta charset ani HTTP hlavičku se obecně spolehnout nedá, cca 10% webů kódování uvedené nemá, nebo ho má špatně, s překlepem atd.
To je ale přece chyba těch webů! A jestliže je někdo líný/neschopný posílat správnou HTTP hlavičku (nebo to zbastlit aspoň přes tu HTML meta značku), tak těžko od něj čekat, že bude do souborů vkládat BOM.
Kromě toho BOM patří k těm horším řešením jak dát najevo použité kódování – protože musím soubor nejprve (částečně) načíst a až pak se dozvím, v jakém je kódování – ne jako když ho znám předem (z hlaviček, rozšířených atributů atd.) a můžu si jednoduše otevřít proud dat včetně správného dekódování.
Navíc Pavlix má pravdu v tom, že BOM komplikuje spojování souborů pomocí příkazu
catnebo obecně spojování „slepením“ dvou posloupností bajtů – v podstatě takový soubor nelze považovat za prostý text, ale za určitý speciální formát.„v podstatě takový soubor nelze považovat za prostý text, ale za určitý speciální formát.“
Franto, ty mi snad čteš myšlenky.
„BOM by měl být všude a povinně“
Tak snad nedostaneš infarkt, když ti řeknu, že unixové/linuxové editory samy od sebe BOM nedávají nikdy, a že tím pádem má většina linuxáků na disku hromadu souborů (včetně těch s html), které BOM neobsahují.
Jinak implikací povinného BOM na začátku souboru je při includech BOM i uprostřed výsledných souborů, a existují prohlížeče, které ti rozbijou layout, pokud tam BOM máš, a je to naprosto v pořádku, protože tam nemá co dělat.
PHP s BOM se rozbíjí taky (nevím, jestli už je na to nějaká náhrada), stejně libovolné skripty na linuxu (první znaky nejsou #!, ale BOM#!, taky nevím, jestli se to už nějak obchází).
Přitom nastavit Content-Type včetně kódování je tak jednoduché.
Proč je nutné pro HTML parser uvádět kódování uvnitř dokumentu, když se posílá i v HTTP hlavičkách?
Samozřejmě, když ho pošlete v HTTP hlavičkách, tak v dokumentu být uvedené nemusí. Jenže průměrný čtenář zdrojáku…
… pravděpodobně bude stránky otevírat i z lokální disku, kde žádné hlavičky nejsou
… má některé stránky na hostingu, kde nemůže ovlivnit jaké parametry se přidávají do hlavičky Content-type
Ale samozřejmě, v článku jsou jistá praktická zjednodušení.
ok, tak to chápu.
BTW: je škoda, že se víc nepoužívají rozšířené atributy souborů – např. wget a curl do nich umí ukládat MIME typ a kódování (případně další věci) z HTTP hlaviček. Ono je obecně dobré vědět, jaký formát načítám a v jakém je kódování, ještě než si ten soubor (proud dat) otevřu a prokoušu se k nějakým meta značkám uvnitř.
Ono by vůbec stálo za to, kdyby se pár lidí chytilo za hlavu a přestali by používat různé iso-8859, windows/msdos/ibm a jiná kódování a shodli by se na to, že se budou používat pouze kódování, která kódují celý Unicode.
A v druhém kroku by bylo dobré, kdyby v naší osmibitové (bajt = 8 bitů) éře používali pouze osmibitovou variantu, tedy UTF-8, protože UTF-16 proti němu má jen samé nevýhody a UTF-32 se asi neuchytí kvůli plýtvání místem.
To není zrovna reálné. A taky bychom se tím vlastně vrátili do doby, kdy se tiše předpokládalo „jediné správné kódování“ – tzn. 90. léta a věčné problémy s „češtinou“ – kdy někdo předpokládal cp1250 a o jiných kódováních neměl ani tušení a ten soubor byl jako na potvoru v ISO-8859-2.
Že by se všichni dohodli na jednom kódování se nedá čekat – např. v některých malých zařízeních nebo nízkoúrovňových programech fakt nemusím chtít řešit vícebajtová kódování. Jinde zase dají přednost UTF-16 před UTF-8 atd. Prostě říct: „budeme všichni používat UTF-8“ by IMHO vedlo akorát k bordelu a chybám, protože stejně někdo bude používat jiné kódování – takhle je možné říct, jaké kódování se používá a podle toho se zařídit.
Existují dobré způsoby, jak tuhle informaci sdělit: HTTP hlavičky, e-mailové hlavičky, rozšířené atributy souborů… horší ale použitelné způsoby: XML deklarace a v horším případě meta značky uvnitř HTML (tam už musíme načíst soubor a pak se nějak „za chodu“ přepnout do správného kódování nebo soubor načíst znovu). Ale úplně nejhorší je předpokládat nějaké implicitní kódování aniž by o tom byla nějaká jasná dohoda (ta u některých formátů je a pak není potřeba kódování explicitně uvádět, ale obecně taková dohoda napříč formáty nikdy nebude).
No já osobně nevidím problém v UTF-8 jako jediném správném kódování, když je alespoň detekovatelné (téměř nepotkáš dokument, který by byl jako utf-8 špatně interpretován).
Já nemám nic proti tomu, když někde na světě ještě existují stará kódování. UTF-16 je relativně náchylné na chyby a chybné předpoklady (jako třeba domnělá pevná bitová šířka znaků). Ve výsledku mi ale jako užitečná kódování vycházejí pouze UTF-8 a UTF-32 (pokud jo nutně potřebuju pevnou šířku znaku).
Jó to kdybychom tu měli pořádný standard, který by všichni hráči respektovali..To bychom pak nemuseli řešit takovéhle krávoviny. Někde jsem četl, že standardizační autorita vydá standard teprve poté až jsou k dispozici dvě nezávislé implementace, WTF??
Kéž by. Vydávat standardy, které nikdy nikdo neimplementuje je nesmysl. Mimochodem W3C doporučení sama W3C za standardy neoznačuje.
WTF?
1/ Reálně (snad někdo s bližším vztahem k W3C potvrdí) se za standard již dá považovat Candidate Recommendation
2/ A ano, do stavu Recommendation se dostane po 2 plných a nezávislých implementacích. Důvodem je to, že návrhy jsou obvykle extrémně komplexní a při nejlepší vůli při teoretickém návrhu může dojít k několika věcem:
a/ v návrhu se může objevit chyba, prostě může, která se projeví až při implementaci a provozu
b/ něco může v návrhu chybět, určitý postup, který není standardizovaný, v návrhu se mohou objevit formulace, které se při implementaci ukáží jako vágní a bude třeba je doplnit
c/ může se ukázat, že návrh obsahuje zbytečnosti, zbytečné předepsané postupy, u kterých se ukáže při implementaci jednodušší cesta
a tím, že W3C vyžaduje 2 nezávislé implementace by tyto problémy měli být eliminované -> návrh je implementovatelný a při implementaci se neobjevili závažné problémy a návrh je implementovatelný různými postupy/nástroji/knihovnami
Veď existuje. HTML.
No vida. Uplne presne takhle to pisu od zacatku… Po predchozim clanku jsem myslel, ze je to nejvetsi hrich, ted mam konecne opet ciste svedomi :).
Takže to shrňme – polyglot je prostě XHTML 1.1 kde je jen jiná deklarace <html a můžu tam používat HTML5 tagy – tak v tom případě to takhle dělám už asi 2 roky. XHTML strict je pro mě hlavně kontrola, že jsem na nic nikde nezapomněl, taková best practice
XHTML 1.1 nemá rozlišení na strict variantu a jiné, ne?
Takže to shrňme – polyglot je prostě XHTML 1.1
Není, XHTML 1.1 může používat veškeré prvky syntaxe XML, polyglot dokument pouze ty, které produkují stejný efekt při čtení parserem HTML.
BTW: Nebylo by lepší, kdyby prohlížeče měly pouze XML parser (klidně každý svůj vlastní) a v případě rozbitých dokumentů by zavolali HTML Tidy (knihovna společná všem prohlížečům)?
To musela být včera hodně divoká party :-D
Dělat to takhle je nesmysl z mnoha důvodů, o některých by šlo i diskutovat. Ale o jednom diskutovat nejde — současné prohlížeče stránku vykreslují inkrementálně ať už se čte pomocí XML nebo HTML parseru — DOM se průběžně konstruuje a následně vykresluje. V případě použití externí knihovny, by se muselo čekat, až ta celý kód zpracuje a pak teprve by s ním šlo něco dělat — znovu naparsovat jako XML a začít renderovat.
A copak by ta knihovna nemohla pracovat inkrementálně? Jako filtr – z jedné strany bude přijímat HTML bordel a z druhé strany z ní půjde well-formed XML/XHTML. Stejně to funguje např. s kompresí nebo šifrováním – z jedné strany proud komprimovaných dat, z druhé nekomprimovaných (a nemusí se čekat na konec souboru, filtrovaná data se posílají průběžně).
Jestli je Tidy víceprůchodové, tak by šlo použít nějaké zjednodušené jednoprůchodové Tidy. Neříkám, že by to tak být mělo nebo nemělo, ale IMO si to rozhodně nezaslouží poznámku o divoké party.
A proč už teda nemít rovnou jen jeden prohlížeč? (Když může být společná jedna knihovna, tak proč ne více?)
Současná specifikace HTML5 přesně popisuje, jak se zotavit z chyb v kódu a všechny hlavní prohlížeče už to mají implementované (některé zatím jen v beta verzích).
Navíc cesta XML -> Tidy -> XML není zpětně kompatibilní se stávajícími stránkami, jak se ošetří třeba document.write?
Kdyby se takhle globalizovalo (jedna knihovna, jeden prohlížeč, atd…), není třeba ošetřovat document.write – jednoduše by se javascript začal vyhodnocovat až po načtení stránky nebo by se při prvním pokusu o manipulaci s DOMem pozastavil do doby, než se celý DOM načte (přičemž onload považujme jako protažení všech bajtů procedurou download->XML->Tidy>XML).
Kéž taková doby nikdy nepřijde.
Takhle jednoduše to nejde, document.write() přímo zapisuje do streamu, který se právě parsuje a vyhodnocuje.
Jestli si chcete zkazit večer, můžete se podívat na odpovídající část specifikace: http://dev.w3.org/html5/spec/Overview.html#dynamic-markup-insertion
Tak by document.write nebylo :))))
Starý známy odporca XHTML sa nezaprie :) rovnako som mu nikdy neprišiel na chuť a prečo ho potom preháňať cez HTML parser aby to fungovalo všade, už úplne stráca zmysel. Pekný článok a dík za knihy s ktorých som čerpal prvé skúsenosti.
Nekdy proste HTML nestaci. Napr. nejakej ten opengraph protokol apod. Proto pisu XHTML, protoze vetsinou nevim, jestli dokument nejaky XML obsahovat v budoucnu nebude. A kdyz jo, tak staci upravit hlavicku.
A s jakým MIME typem posíláte XHTML+OpenGraph do prohlížeče?
Jestli je to text/html, tak se zcela špatně interpretují jmenné prostory – schválně se podívejte co vám budou vracet vlastnosti localName a namespaceURI pro elementy jako fb:like
Jestli je to application/xhtml+xml, co na to IE8-?
Asi vám to bude připadat jako malichernost, ale já se přiznávám, že mě trochu vytáčí, když někde čtu slovo „tabelátor“. Vytvářím přece tabUlky a ne žádné tabElky! Tabelátor je stroj na snímání děrných štítků. Viz http://cs.wikipedia.org/wiki/Tabulátor
Nojo, tak dlouho jsem se o tom kdysi dávno s někým přel, až jsem to tu napsal špatně.
Nicméně většina slovníků v současnosti obě slova považuje za synonyma. A opírat se v takovýchto případech o Wikipedii jako autoritativní zdroj mi připadá přinejmenším úsměvné.
Používáme striktnější syntaxi než HTML inspirovanou v XHTML (malá písmena, atributy v uvozovkách, uzavírací tagy apod.), ale ne tak striktní jako polyglot. Důvod je prostý: aby měl zdrojový kód nějakou kulturu, dobře se četl, byl přehledný.
Když použiji na webu HTML5 Polyglot, jaký parser se použije v moderních prohlížečích? Je to přece text/html, takže se vybere HTML parser, je to tak?
Záleží na MIME typu, který pošlete:
S nástupem XHTML se do prohlížečů přidal ještě parser XML. Jakým parserem se stránka bude načítat, řídil MIME typ zasílaný do prohlížeče. Stránky označené pomocí text/html se zpracovávaly pomocí parseru HTML a stránky označené pomocí jednoho z MIME typů application/xhtml+xml, application/xml nebo text/xml se pak načítaly pomocí parseru XML.
Aha, už to chápu. Díky! Nedošlo mi, že můžu HTML5 poslat s MIME application/xhtml+xml.
Prostě a jednoduše, nic nového to nepřináší, ale umožňuje to absurdně složité kostrukce. Bomba.
Pominu zásadní faktickou chybu článku co se týče IE a datumu – více než polovina instalovaných IE verzi 9 jentak nepotká, neboť tato jaksi nefunguje pod stále oblíbenými a po těch deseti letech i celkem doladěnými win XP. IE9 navíc rozhodně neumí HTML5 tak, aby to dávalo smysl, tedy podpora jednoho mimetypu situaci rozhodně nezachrání. Alespoň je IE9 natolik rychlý a stabilní, že už uživatele nenutí instalovat jiné mamuty ala ff, chrome či opera.
Čili jakékoliv novější pokusy než html4 stále znamenají, že uživatel stránky vůbec nemusí vidět korektně. Dokud se jedná o stránky zábavné, je to putýnka, ale pokud se v něčem novějším kóduje projekt, kde je hlavní obsah (nedejbože státní web, jehož využití je povinné), je to důkazem nedostatečné přemýšlivosti jeho autorů. No snad tak za 5-10 let bude HTML5 reálně použitelné, ale to bude web dávno přepaný polofunkčními implementacemi HTML6,7,8 a dalšími v mezičase vytvořenými úlety. Browsery budou z důvodu nutnosti podpory desítek nesmyslných formátů zas o neco náročnější a padavější, takže řada lidí bude preventivně používat starě, starší až archeologické verze – FF, resp tehdy ještě Firebird verze 0.7 je asi slušným etalonem toho, jak by měl být browser rychlý a stabilní.
Tedy článek sice hezky kritizuje nekorektní modernistický postup, ale z úplně špatného úhlu.