Stránkování vám může snížit procento okamžitých odchodů

Zdá se, že pro většinu lidí, věnujících se zlepšování přístupnosti, spolu procento okamžitých odchodů a stránkování obsahu nijak nesouvisí. V článku vám autor předvede, jak technická změna provedení stránkování může snížit procento okamžitých odchodů na vašem webu.
Článek si neklade za cíl jakkoliv polemizovat se skvělým článkem o smysluplném stránkování z pera Davida Grudla. Není zaměřen na grafické provedení stránkování, ale věnuje se převážně technickému provedení a dopadům zvolené metody na případné chování návštěvníků.
Definice problému a idea
Před cca půl rokem se autor tohoto článku u jednoho ze svých webů informačního charakteru věnoval studování statistik z Google Analytics a všiml si zajímavého jevu: Na stránky vypisujících články – seznam článků – často přicházeli lidé z vyhledávačů na slova, které se na stránce vůbec nevyskytovaly.
Zkrátka návštěvník hledal informaci například o “připojení hadice na pračku”, ale na stránce “/kutilove/2/”, kam z vyhledávače přišel, se informace nevyskytovala. Článek o zapojování pračky totiž mezitím “zestárl” a přesunul se ze strany 2 na stranu 4. Naštvaný návštěvník tedy logicky stránku zavírá a odchází.
Ideální by bylo, aby stránkování (a přidružené URL) bylo neměnné, trvalé v čase. Aby výpis článků na nějaké adrese byl po zaindexování Googlem už navždy, a návštěvníci tak vždy nalezli to, co hledají, přešli na článek a zbytečně neodcházeli.
Teoretické seznámení s experimentem
Na základě objeveného problému se autor rozhodl pro experiment, ve kterém nahradil stávající stránkování jiným funkčním modelem, který zajistí neměnnost obsahu pro stránkovací výpisy v čase. Princip řešení je zhruba takovýto: do www adresy neuvádět stranu, ale číslo článku, “od kterého dál” se má obsah načíst.
Pro názornou ukázku předpokládejme například články v kategorii kutilové s ID: 45, 40, 37, 33, 31, 30, 15, 14, 13, 2, a stránkování po třech článcích.
V původním systému byste získali něco takového:
- /kutilove/ : 45, 40, 37
- /kutilove/2/ : 33, 31, 30
- /kutilove/3/ : 15, 14, 13
- /kutilove/4/ : 2
Je zřejmé, že když redaktor napíše nový článek a zařadí jej do sekce kutilové, tak články 37,30 a 13 již nenajdete na starých adresách.
V novém systému nahradil autor klasické uvedení čísla stránky v URL vypisováním posledního použitého id. Výše předpokládaný model by tedy vypadal nějak takto:
- /kutilove/ : 45, 40, 37
- /kutilove/od37/ : 33, 31, 30
- /kutilove/od30/ : 15, 14, 13
- /kutilove/od13/ : 2
Když díky čilé práci redaktorově přibude nový článek, budou nové adresy archivů sice vypadat takto:
- /kutilove/ : 50, 45, 40
- /kutilove/od40/ : 37, 33, 31
- /kutilove/od31/ : 30, 15, 14
- /kutilove/od14/ : 13, 2
Ale Googlem zaindexované adresy /kutilove/od37/ , /kutilove/od30/ , /kutilove/od13/ budou i nadále obsahovat stejný obsah a plně uspokojovat touhy návštěvníků – ti najdou to, co hledají. Navíc: adresy, které Google získal po přidání článku s id 50, již budou také nadále platné – navždy.
Pozn.red.: Za úvahu by stálo vyzkoušet postup, při němž se články nesdružují od nejnovějších, ale od nejstarších – tím by se předešlo změnám adres jednotlivých stránek, a situace by vypadala takto:
- /kutilove/ : 45
- /kutilove/od40/ : 40, 37, 33
- /kutilove/od31/ : 31, 30, 15
- /kutilove/od14/ : 14, 13, 2
a po přidání článku s ID 50 se situace, díky sdružování od konce, nijak nezmění:
- /kutilove/ : 50, 45
- /kutilove/od40/ : 40, 37, 33
- /kutilove/od31/ : 31, 30, 15
- /kutilove/od14/ : 14, 13, 2
Technická realizace experimentu
Zavedení experimentu do praxe však vyžaduje jisté podmínky a úsilí programátorů.
Podmínky:
Prakticky jedinou podmínkou, nutnou pro život, je vzestupné řazení ID článků. Novější články prostě musí mít vyšší ID než články starší. Pokud například bude chtít redaktor recyklovat starý článek a znovu jej například po roce vydat, musí za něj redakční systém rovněž změnit id na nejnovější.
Nároky navíc na programátory:
Tento princip řazení článků bude od programátora vyžadovat dotaz do databáze navíc. “Postaru” jste si jedním dotazem načetli nejen všechny články, které odpovídaly klauzuli LIMIT, ale pomocí SQL_CALC_FOUND_ROWS jste rovnou viděli i celkový počet stran a zároveň jste z URL adresy věděli, která strana je vlastně aktivní. To v novém systému padá – údaje si musíte pomocí několik dotazů a výpočtů předpřipravit sami.
Algoritmus musí být schopen rozpoznat z id článku v url adrese správnou aktivní stranu ve stránkování, na které se nachází (zjistit počet článků nad ním, a dle toho vypočítat aktivní stranu), díky tomu je schopen spočítat odpovídající údaje do SQL dotazu (LIMIT X, Y). V dotazu si rovněž vytáhne správná data a pomoci SQL_CALC_FOUND_ROWS i celkový počet článků.
Staré adresy je vhodné přesměrovat do nového systému. Zde existují dvě možnosti:
Buďto budete spoléhat na to, že Google nové adresy přijme rychle a staré adresy budete přepočítávat vždy k online datům (tedy i k novým článkům), nebo si někam musíte zakonzervovat počet článků v jednotlivých kategoriích a udělat přesměrování tzv. natvrdo – předhazovat vždy adresy, které v době, kdy jste zavedli nové stránkování, byly platné.
Rovněž je možností staré stránkování zachovat, a jen jej na webu nepoužívat – lze asi předpokládat, že adresy Google později v čase sám zapomene. (Autor nemá odzkoušeno)
Graf: důkaz místo slibů
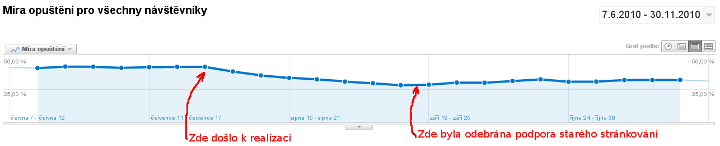
Výše zmíněný experiment byl zrealizován v průběhu července 2010 a zde je graf toho, jak se zmíněný pokus projevil na míře opuštění – jedná se pouze o stránky s výpisem článků, efekt je tedy dobře viditelný a nad očekávání dobrý.
V září byla odebrána zpětná podpora starého stránkování – ta se nakonec projevila mírně negativně.
Autor původně plánoval zveřejnit graf ukazující frekvenci procházení stránek, bohužel tento graf již nelze získat; zdá se, že nástroj Webmaster Tools ukazuje hodnotu frekvence procházení pouze 3 měsíce dozadu. Z paměti však může říci, že podstatné na grafu bylo to, že efekt se nijak neprojevil – robot od Google procházel web se stejnou frekvencí jako před experimentem.
Závěr
Je jasné, že míra opuštění a výsledný efekt se bude lišit web od webu, každý webový portál je jedinečný. I frekvence procházení webu roboty od Google, Bing či Seznamu se bude lišit. Přesto si autor troufá tvrdit, že efekt by měl být spíše pozitivního charakteru – protože návštěvníci na stránce naleznou to, co ve vyhledávači hledali – neodejdou a překliknou na článek.



Nemáte při takovémto stránkování problém s duplicitním obsahem?
Stránka /kutilove/od37/ a /kutilove/od40/ obsahuje ze 2/3 (při více článcích na stránku, i víc) stejný obsah. Děkuji.
Nehledě na to, že pokud stránkování pak bude zmatené. Pokud vyhledávač zaindexuje toto:
/kutilove/ : 45, 40, 37
/kutilove/od37/ : 33, 31, 30
/kutilove/od30/ : 15, 14, 13
/kutilove/od13/ : 2
Jaké potom bude stránkování, když aktuální je
/kutilove/ : 50, 45, 40
/kutilove/od40/ : 37, 33, 31
/kutilove/od31/ : 30, 15, 14
/kutilove/od14/ : 13, 2
Tzn. že v odkazech na stránkování není odkaz na /kutilove/od37/
Dobrý den,
– myslím že zmíněná věc není problém, ale vlastnost
– v experimentu jsem toto neřešil, pokud bych se chtěl této vlastnosti chtěl zbavit, udělal bych to pravděpodobně tak, že první strana by obsahovala obsahu více. Vysvětlím:
Pokud bychom chtěli stránkovat po 10 a měli 43 článků, tak všechny strany kromě první by obsahovaly 10 článků a první strana 13 článků (tím by se dodrželo to že Google budeme nabízet časově neměnné odkazy)
(první strana by měla proměnlivě 10-19 článků)
Toto jsem vymyslel teď jako reakci na Váš poznatek, je pravděpodobné, že to lze vymyslet lépe, nebo je lepší to vůbec neřešit. Osobně jsem toto ale neřešil a původní řešení mě stačilo. Cílem bylo snížit procento okamžitých odchodů a to se povedlo.
Dobrý den,
– problémy typu snížení návštěvnosti, nebo pozice vybraných klíčových slov jsem v tomto experimentu nezaznamenal.
– domnívám se, že algoritmus Google má s tímto problémy i ted, v ponděli zaindexuje na straně 1 články ABC, za pár dní, třeba ve čtvrtek se články ABC již nachází na straně 2. Postaru je tam tedy stejný problém, jako v tomto experimentu.
Ahoj Petre. Pekny clanek, diky za nej. Je velmi inspirativni. :-)
To by melo uplne stacit ne? Neni vubec nutne sahat na cisla clanku a resit problemy co se stane kdyz ciselna rada neni souvisla.
Nesmíte pak ale mazat články nebo měnit jejich pořadí…
Ale muzu, dobri roboti se vraceji a dokud se tak nestane, tak se presune jenom urcite procento clanku. A navic v opravdu stare historii se tak casto nemaze.
Podle mne jakékoli sekvenční číslování v trvalých adresách nemá šanci na úspěch, protože ta čísla pro uživatele nic neznamenají – je to technická věc sloužící jen implementaci.
Když si vezmu klasický příklad – články nebo aktuality. Můžu je začít číslovat od jedničky, takže nejnovější články budou v archivu na stránce s nejvyšším číslem. Jenže pak je problém, co na konci. Mám stránky třeba po deseti článcích, ale mám 51 článků. Takže když vlezu do archivu, zobrazí se mi na první stránce (s nejvyšším číslem) jen 1 článek, teprve když půjdu dál, budou se zobrazovat po deseti. Ta první stránka archivu je ale pro uživatele dost matoucí. Nebo můžu na aktuální stránce zobrazovat články od počtu 1 do 10, a teprve když přidám jedenáctý, přesune se 10 článků do archivu a na aktuální stránce zůstane 1. To je o něco lepší, ale většinou chci na aktuální stránce články nějak vybrané (mladší než týden, posledních 10 apod.) a řídit to tím, aby mi vyšlo stránkování archivu, to není zrovna přívětivé. V článku je popsána další varianta tohoto způsobu, jenom se místo sekvenčního číslování používají čísla článků, takže jsou v té sekvenci mezery (nebo duplicity) – to je podle mne ještě víc matoucí.
Přitom ale podle mne není důvod mít v archivu na každé stránce stejný počet článků, zároveň pro uživatele je informace „strana č. 43 z archivu“ k ničemu. Nejlogičtější mi tedy připadá členit archiv podle data – např.
/archiv/2010/prosinecnebo/archiv/2010/Q4apod. Stránkovač pak místopředchozí | 1 | 2 | ... | dalšíbude zobrazovatstarší | leden 2010 | únor 2010 | ... | novější.Pro případy, které nemají takovéhle logické dělení (např. položky v kategorii e-shopu) pak podle mne nemá ani smysl mít trvalé URL pro nějakou stránku kategorie a řešil bych to spíš parametrem URL.
Dobrý den,
o trvalém úspěchu nebo neúspěchu se přít nebudu, u mě byl požadavek snížit procento odchozích lidí, které Google přivedl na stránku, které už byla díky novým článků zcela jiná. To se povedlo. Že toto šlo řešit i jinak je pochopitelné.
Například řešení s roky a měsíci je zajímavé. Tam ale nastává problém s příliš mnoho články v měsíci, například idnes.cz by takto mělo v měsíce tisíce, ne-li desetitisíce článků.
Řešení s dopočtem článků na první straně jsem tady před chvilkou zmiňoval v nějakém komentáři výše – také by to mohlo jít.
opakuji, nebazíruji na jediném správném řešení, jen chci upozornit na to, že existují způsoby jak snížit procento okamžitých odchodů z výpisu článků.
Dělení podle času se samozřejmě musí přizpůsobit frekvenci vydávání článků. Blog s dvaceti zápisky ročně bude stránkovat po čtvrtletích, iDnes může stránkovat třeba po hodinách :-) Teoreticky je možné ve stránkovači použít i proměnlivé dělení, měly by pak ale fungovat všechny typy URL.
Krasny den,
Ja bych si pokladal otazku proc google nedovedl uzivatele primo na clanek.
Proc ho dovede na vypis clanku ? To co uzivatel hleda neni ve vypisu clanku ale v clanku samotnem. Pak mam unikatni URL a neni co resit.
Ale je fakt ze staticka URL ve vypisu je velmi dobry napad. Ale priklanim se k nazoru ze by stacilo cislovat od konce. nejstarsi clanky budou mit v url /1/ a nejmladsi napr: /20/ Uzivatele URL nezajima a pojmenovat si odkaz muzu jak chci.
Honza Vrana
Dobrý den,
ano, je ideální když Google, Seznam a spol odkáží přímo do článku, bohužel všichni víme, že se to tak často neděje.
Vzniklou situaci jsem tedy řešil takto, možných řešení je pochopitelně více.
Jenže to je to o co tu jde. Chceme uživatele přivést k obsahu, tedy článku a ne jeho seznamu. Je to hned z několika důvodů:
1) Vytváříme duplicitní obsah – článek je jak v seznamu tak v detailu, což nám uškodí ve vyhledávači.
2) Uživatel nemusí být ochoten hledat v dlouhém seznamu to, co chtěl a uteče tak jako tak.
3) Výsledek vyhledávání vedoucí na seznam článku bývá často zavádějící, neboť když například hledám více klíčových slov, často se mi stane, že se dostanu na seznam článků a přestože se všechna slova na stránce vyskytují, jsou rozptýlena po všech článcích a nenajdu jeden konkrétní článek, který je obsahuje všechny. Jsem pak otráven a jdu pryč (což dělám často, hned když vidím seznam článků).
4) Kazí mi to reálnou výpověď statistik. Zlepší se mi sice bounce rate, jelikož uživatel často přejde na konkrétní článek, ale již se nedozvím, zda ho zaujal a zůstal na webu nebo z něj hned utekl, takže zlepšení je jen optické. Stejně tak mi to zbytečně „vylepšuje“ počet navštívených stránek.
Nemá tedy podle mě smysl zabývat se statickým stránkováním, ale naopak tím, aby Google, Seznam a spol indexovali a preferovali články a nikoliv jejich seznamy. A není to jejich chyba, že to nedělají.
<meta name=“robots“ content=“noindex, follow“>
Přesně tak, v první řadě bych se snažil dosáhnout toho, aby google posílal návštěvníky rovnou na URL s článkem (výpis vůbec indexovat nemusí, ten je dobrý jen k tomu, aby vyhledávač získal odkazy na články).
Takže otázka do pléna: pomůže noindex+follow k požadovanému chování?
Jiná situace je u výpisů, který jsou samy obsahem – např. výpis komentářů v diskusi, kde už se jednotlivé komentáře nerozklikávají a zajímá nás právě jejich výpis – diskuse. V takovém případě bych stránkoval buď časově (měsíce, dny…) nebo jednoduše čísloval odzadu (nejstarší na straně 1).
A co třeba držet normální číslování a při vstupu na stránky odchytávat lidi, kteří přicházejí z vyhledávačů a vlastně jim zprostředkovat ještě jedno vyhledávání a vzít je tedy na požadovaný obsah. Otázkou je, zda se nejedná od black hat SEO.
Neni lepsi reseni dat na strankovane stranky meta „noindex, follow“? Vyhledavace pak indexuji jen detaily produktu/clanku a lide z vyhledavacu tak pristanou vzdy na spravnem konkretnim clanku… Uspesnost cisly vyjadrit nedokazu, ale na jednom webu to tak mame a navstevnost je dobra a problem popsany v clanku vubec nemame.
Furt mne to nepřesvědčilo, protože to neřeší problém zcela, respektive to vyřeší problém pro většinu stránek, vyjma té hlavní. Když se dle příkladu odkazem dostanu na stránku /kutilove/, kde si Google zaindexoval článek 37 (45,40,37) a já tam už uvidím avizované 50,45,40, tak jsem tam, kde jsem byl.
Za cenu té režie to dle mého nestojí.
Dobrý den,
ano, toto zůstává, v mém projektu vycházím z toho že stránka /kutilove/ je prolinkovaná z hlavní strany a Google jí indexuje prakticky denně. Obecně ale máte pravdu.
Cena režie – příklad, předpokládejte, že k Vám přijde 5 tisíc lidí denně. Cca 20% zlepšení odchodů (ve výpisech článků, globálně cca 10% zlepšení) znamená 1.000 (respektive 500) lidí, kteří jsou spokojeni a dál pokračují na webu. Čtou články, shlížejí reklamy, přihlašují se ke zpravodajům, dělají objednávky na knihy…
Rozhodně jsem přesvědčen, že v mém případě se zadavatelovi ty moje 2 hodiny práce několikanásobně vrátily ;o) A nepochybuje o tom ani zadavatel.
Neslo by vse resit jednoduchym zpusobem, a to ze stranka s prehledem clanku bude mit v hlavicce NOINDEX a FOLLOW, a adresa s celym clankem bude mit INDEX a FOLLOW. Tim by odkaz z google mel smerovat na konkretni clanek a ne na prehled clanku kde se obsah neustale meni
Vždyť se úplně nabízí použít datum. Podle toho jak často aktualizuji (třeba jednou za den), si zvolím rozsah (například týden) a pak mohu stránky vypisovat podle toho.
Odkazy pak budou obsahovat číslo týdne v roce a rok. To dává celkem rozumný počet 7 článků na stránce. Obsah stránky se tak změní pouze v případě, že něco publikuji zpětně nebo přesunu na jiné datum.
Jediný problém pak zůstane hlavní stránka, která ale bude problém vždycky. Pokud navíc uživatele nějakým způsobem šikovně vizuálně upozorníme na způsob řazení, bude mu to dávat větší smysl než nějaká IDčka.
Dobrý den,
ano datum se nabízí, ale nastává ještě horší problém.
I když víte, že přibude jeden článek denně, tak nevíte do jaké rubriky. Například do právní poradny přibude jeden článek za cca týden, do kutilu ob den, atd… tak nastane stav, že každá rubrika má jinou periodu, která je navíc proměnlivá v čase (rubriky o zahradě v zimě prakticky nejsou).
Navíc nastává problém, když si chcete vyfiltrovat články od jednoho redaktora/redaktorky. Nepíší pravidelně, ale s obrovskými časovými skoky – není jak to řešit.
Datum se tedy pro tyto účely – dle mě – nehodí.
To přece nehraje roli… Pokud bereme v potaz jen základní listování, je rubrika bezpredmětná. Listování v kategoriích je pak stejně pod zcela jiným odkazem než to celkové, takže to opět nevadí. Snad jen v případě, že by nám vadilo, že týdny nejdou po sobě ale je mezi nimi mezera (třeba v případě té zimní rubriky).
/tyden/7/2011 a /zima/tyden/7/2011 jsou pro Google jiné stránky.
V případě různě častých aktualizací už to ale problém je, to souhlasím. Dalo by se to řešit ale je to vcelku nepohodlné.
Filtrování podle autora už ale většinou provádí uživatel na základě nějaké interakce, která většinou ani není vyhledávačům přístupná. A ani tam to nevadí. Uživatel se maximálně dozví, že autor napsal tři články v sedmém týdnu roku 2011 a předtím pět článků v prvním týdnu téhož roku a nic víc. Samozřejmě musí celé řešení fungovat tak, aby uživatel přepínal mezi týdny, kdy byl autor aktivní a nemusel se prohrabat zbytkem roku :)
/kutilove: 50, 49, 48
/kutilove/od47: 47, 46, 45
Po čase vložím další články:
/kutilove: 53, 52, 51
/kutilove/od50: 50, 49, 48
/kutilove/od47: 47, 46, 45
Článek s ID 50 je na jiné adrese. (Záměrně jsem použil 3 nové ID, aby bylo stránkování ideální, u řešení, že na první straně bude proměnlivý počet článků tímto trpí také.)
Řešení to šťastné není, nicméně problém je popsaný dobře a článek dává minimálně důvod se nad tímto problémem zamyslet.
To co padlo v diskuzi, o tom, že vyhledávač tě má vést na detail a nikoliv na přehled se zdá na první pohled rozumné, ale v případě, že mám více článků na podobné téma, pak je přece relevantnější ten přehled. Ale tohle je výjimka, většinou by tě měl vyhledávač opravdu vést na samotný detail. Čili úsilí, vynaložené na úpravu stránkování je lepší využít právě na to, aby to byly články, co bude vyhledávač doporučovat.
„… ale v případě, že mám více článků na podobné téma, pak je přece relevantnější ten přehled. …“
Ten přehled mám přímo ve vyhledávači a už tam si vyberu konkrétní článek. Dále pro tento případ, bych odkazy k relevantním článkům dal přímo ke každému jednomu článku.
Dik za clanek,
Ten clanek je daleko uzitecnejsi nez clanek o strankovani od Davida Grudla.
No podle mne jsou oba články přínosné, protože jsem obsahově zcela odlišné. Každý se zaměřuje na zcela jinou část problematiky stránkování.
1) zakázat robotům indexovat stránkování s více články
2) udělat souhrnný seznam článků třeba po létech/měsících. uvítají to i uživatelé
3) neposlušné roboty, kteří přijdou přímo na stránku s více články přesměrovat na seznam článků
roboti si oindexují vše. uživatelé z vyhledávačů nebudou přicházet na „stránky“, ale na konkrétní články
Jednoduche riesenie je zisti keywordy, ktory uzivatel hladal vo vyhladavaci, a ked smeruju na search, tak spravit vlastne vyhladavanie.
Takto sa mu ukaze to co chce najst.
O tomto problému jsem psal už před pěti lety. A troufnu si tvrdit, že už tehdy jsem vymyslel lepší řešení, které nevyžaduje řazení článků podle ID a poměrně pracné zjišťování ID záznamů na jednotlivých stránkách. Odkazy jsou tyto:
/kutilove/: 45, 40, 37/kutilove/offset7/: 33, 31, 30/kutilove/offset4/: 15, 14, 13/kutilove/offset1/: 2V knize pak představuji ještě lepší řešení, které netrpí ani problémem duplicitního obsahu (kromě titulní stránky).
/kutilove/: 45, 40, 37/kutilove/page3/: 40, 37, 33/kutilove/page2/: 31, 30, 15/kutilove/page1/: 14, 13, 2Pokud na titulní stránce nejde zobrazovat proměnlivý počet záznamů (což by problém duplicitního obsahu zcela vyřešilo), tak vede z titulní stránky odkaz např. na
page3/#item2. Aby se na tomto odkazu nezobrazil třeba jen jeden článek, tak je vhodné na titulní stránce zobrazovat méně záznamů než na ostatních stránkách (např. na titulní 5, na dalších 10), což obvykle ničemu nevadí.Dobrý večer,
i když jsem už pár dní majitelem Vaší knihy, na toto řešení jsem nenarazil, to mé natolik jiné („zprasené“), že je evidentní, že je z mé hlavy. – díky tedy za Vaše řešení.
Opět ale platí to, co jsem tady v diskusi opakoval několikrát, podstatné je danný problém s odchody nějak zalepit, uvědomit si ho. Technické řešení se pochopitelně liší názor od názoru (nofollow, date, od15, stránkovat pozadu, atd…)
Je to tip 555 – Trvalé odkazy na stránkování.
Jestli to ovšem chápu správně, toto řešení je funkční pouze do doby, než z jakéhokoliv důvodu změním počet článků/záznamů na stránce (změna designu, požadavek zadavatele apod.).
Z tohoto pohledu dává největší smysl již zmiňované řazení podle času, tnz. s jakýmkoliv „neměnným krokem“ (aby vše bylo na jedné stránce), anebo zkrátka tyto stránky neindexovat a raději nový obsah propagovat pomocí sitemap souborů na detail obsahu.
V „časovém“ pojetí si ale moc nedokážu představit stánkování posledních vydaných článků (resp. cokoliv krom úvodní sránky by mělo směřovat do „archivu“, čímž bude užiavtel očekávající pokračování obsahu zmaten, protože logicky uvidí to co už na úvodní stránce jednou viděl). Rozdrobení kroku na jednotlivé články (jediný dále nedělitelný krok) je samozřejmě nesmysl.
Přemýšlím, jak zajistit stabilní URL pro nejnovější články.
Nebylo by vhodné ještě doplnit redirect první stránky z /kutilove/: 45, 40, 37 na dopočtený „/kutilove/page4/“, který by se v čase měnil z „45, 40, 37“ na „46, 45, 40“ a naposledy na „47, 46, 45“?
(Pak by se začlo používat „/kutilove/page5/“ s výchozím obsahem „47, 46, 45“)
Tj. poslední stránka by vždy měla „plný počet článků dle stránkování“ a první a druhá stránka by obsahovaly překryvy.
Slibuji si od toho, že každý článek by měl od samého začátku stejnou adresu i ve výpisu.
„neměnnost obsahu pro stránkovací výpisy v čase.“
to je zakladna mantra, ktoru si kazdy programator strankovacieho algoritmu musi opakovat do zblbnutia ;-)
venoval som sa tomu istemu pred casom
http://spravodaj.madaj.net/view.php/2010/06-strankovanie-poloziek-priebezne-pribudajuceho-zoznamu