Vyskúšajme si Tokyo Cabinet

Názvy nástrojů z řady Tokyo jsou programátorům v Ruby jistě povědomé, ať již jde o Tokyo Cabinet či Tokyo Tyrant. V článku vám blíže představí koncepty i oba nástroje sám autor Mikio Hirabajaši. (Článek vznikl jako překlad z japonského originálu a vychází s autorovým svolením.)
Seriál: Nerelační databáze (11 dílů)
- CouchDB – tak trochu jiná databáze (1. část) 24. 8. 2009
- CouchDB – tak trochu jiná databáze (2. část) 31. 8. 2009
- CouchDB – tak trochu jiná databáze (3. část) 7. 9. 2009
- MySQL v roli neschémové databáze 6. 1. 2010
- Základy Amazon SimpleDB 30. 3. 2010
- Návrh databáze – NoSQL vs SQL 31. 3. 2010
- Amazon SimpleDB prakticky v PHP 15. 4. 2010
- Vyskúšajme si Tokyo Cabinet 4. 5. 2010
- Redis: key-value databáze v paměti i na disku 7. 10. 2010
- Přechod z MySQL na CouchDB, část první 17. 2. 2011
- Přechod z MySQL na CouchDB: Druhý díl 24. 2. 2011
Nálepky:
Čo je to DBM?
V jazykoch ako Perl, Ruby, PHP, ale určite aj v mnohých iných, je možné vytvárať asociatívne polia alebo hash-e. Pomocou nich môžeme zaznamenať vzťah medzi kľúčom a hodnotou, alebo efektívne vyhľadať hodnotu priradenú kľúču. Ak ste programátor, pravdepodobne takúto funkcionalitu využívate denne.
Štandardné asociatívne polia v skriptovacích jazykoch ukladajú dáta iba do pamäte. Znamená to, že ak proces skončí, dáta sa zmažú. Zároveň nie je možné pracovať s dátami, ktoré sú väčšie ako je obsah pamäte. Riešením oboch problémov je DBM (DataBase Manager). V DBM sú asociatívne polia realizované v rámci súboru, čím je možné predísť strate dát po ukončení procesu. Navyše je dáta možné ukladať bez ohľadu na veľkosť pamäte, pokiaľ nám to samozrejme dovolí kapacita disku.
Databáza DBM bola vyvinutá Kenom Thompsonom, otcom UNIXu, a jej interfejs je dostupný pre jazyk C.
typedef struct { char *dptr; int dsize; } datum; // Štruktúra pre dáta
int dbminit (char *name); // Otvor databázu
int store (datum key, datum content); // Ulož ľubovolný záznam
datum fetch (datum key); // Získaj ľubovolný záznam
datum delete (datum key); // Vymaž ľubovolný záznam
datum firstkey (); // Získaj prvý kľúč
datum nextkey (datum key); //Získaj nasledujúci kľúč
int dbmclose (); // Zavri databázu
Úložiská typu kľuč–hodnota (key–value) sa do väčšej pozornosti dostali len nedávno, no ako sme mohli vidieť, tento model vznikol už pred 30 rokmi. Pravda je, že DBM mal obmedzenie v počte databáz, ktoré je možné otvoriť v rámci jedného procesu, a taktiež problémy s neúmerným rastom databázového súboru pri väčšom množstve záznamov. To však nebránilo tomu, aby sa jeho jednoduchý interfejs používal na správu databáz.
Produkty ako NDBM, GDBM, SDBM, TDB, QDBM, BerkeleyDB a CDB v tomto ohľade imitujú DBM . Tokyo Cabinet (ďalej len TC) je tiež jeden z nasledovníkov tohto modelu.
Vlastnosti Tokyo Cabinet
Databáza Tokyo Cabinet je vyvinutá na základe štúdie „Moderná implementácia DBM“. Pod „modernosťou“ máme na mysli využite prostriedkov, ktoré sprístupnil pokrok v oblasti hardvéru. Menovite práca s veľkým množstvom dát a paralelné spracovanie. Konkrétne môžeme hovoriť o nasledujúcich vlastnostiach:
- Efektívne narábanie s priestorom.
Hlavičky záznamov sú malé. Z toho vyplýva aj malá veľkosť súboru - Časová efektívnosť
Vďaka optimalizovaným algoritmom a vhodnému využívaniu pamäte pracuje rýchlo - Vysoká miera paralelizácie
S jednou databázou je možné manipulovať vo viacerých vláknach súčasne - Podpora 64 bitov
Teoreticky je možné narábať s databázou o maximálnej veľkosti 8 exabajtov
Na rozdiel od DBM, databáza Tokyo Cabinet neposkytuje len interfejs pre jazyk C, ale aj binding-y pre mnoho ďalších jazykov. Programátori preto môžu TC používať v jazykoch ako Perl, Ruby, Java, Lua, Python, PHP, Erlang, Haskell a Go bez najmenších problémov.
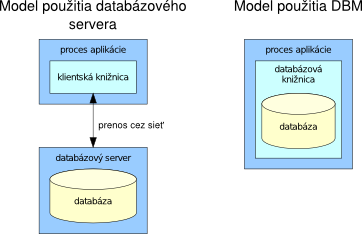
Typickou črtou potomkov z rodiny DBM databáz je, že sa v podobe knižnice dynamicky linkujú k procesu aplikácie. Nesprostredkujú prenos dát k databázovému serveru prostredníctvom siete, ale aplikácia sama prostredníctvom nich upravuje databázový súbor. Toto je dôvod, prečo je databáza TC neobyčajne rýchla. V prípade, že vstup/výstup zo súboru je uložený v cache operačného systému, je za jednu sekundu možné vykonať zápis 2,5 miliónov krát a čítanie až 3 milióny krát. Ak ste nikdy nepoužili iný druh databázy ako relačnú, budete pri prvom kontakte s rýchlosťou TC možno prekvapení.
Jednoduché použitie
Databáza TC je dostupná pre unixové systémy ako Linux, FreeBSD a Mac OS X. Inštalácia je rovnaká ako u ostatných opensourcových produktoch – stačí rozbaliť balík so zdrojovým kódom a skompilovať. Balík so zdrojovým kódom si prosím stiahnite z oficiálnej stránky (http://1978th.net/tokyocabinet/)
$tar zxvf tokyocabinet-1.4.40.tar.gz $ cd tokyocabinet-1.4.40 $ ./configure $ make $ sudo make install
V balíku sa okrem knižnice nachádzajú aj nástroje pre použitie v príkazovom riadku. V nasledujúcom príklade sa pomocou nich pokúsime zostaviť malý slovník. Ako vstupné dáta si prosím pripravte súbor vo formáte TSV (Tab-Separated Value) s nasledujúcim obsahom.
panda パンダ orel タカ lev ライオン tygr トラ opice サル hroch カバ
Ak ste tento súbor uložili ako animal.tsv, pomocou nasledujúceho príkazu vytvoríte slovníkovú databázu. Výsledkom bude súbor dict.tch
$ tchmgr importtsv dict.tch animal.txt
Vyskúšajme si teda vyhľadať slovo pomocou našej databázy. Ako prvý parameter uvádzame príkaz, druhý je meno databázy a tretí označuje kľúč, ktorého hodnotu budeme hľadať.
$ tchmgr get dict.tch lev ライオン
tchmgr pozná okrem príkazu get príkazy put – vytvorenie záznamu, out – vymazanie záznamu, list – výpis prehľadu kľúčov a mnoho ďalších príkazov, pomocou ktorých môžeme na databáze vykonávať bežné operácie.
Pravdu povediac, toto sú hlavné operácie, ktoré s DBM môžeme prevádzať. Možno si myslíte, že takáto jednoduchá databáza sa nedá prakticky využiť. Avšak väčšina zložitých vyhľadávacích algoritmov pozostáva práve z takých jednoduchých operácií, aké môžeme vidieť u DBM. Voľba rýchlej DBM preto môže okrem zefektívnenia rôznych systémov predstavovať aj mocný nástroj.
Použitie v skriptovacom jazyku
V mnohých programovacích jazykoch je databázu TC možné použiť temer identicky ako asociatívne polia. V jazyku Ruby ju môžeme použiť nasledovne.
# štandardný hash
hash = Hash::new # vytvoríme objekt hash
hash["foo"] = "bar" # priradíme hodnotu
printf("%sn", hash["foo"]) # vypíšeme záznam
#
#
# hash pomocou TC iba v pamäti
require 'tokyocabinet'
db = TokyoCabinet::ADB::new # vytvoríme objekt databázy
db.open("*") # spojíme ju s TC v pamäti
db["foo"] = "bar" # priradíme hodnotu
printf("%sn", db["foo"]) # vypíšeme záznam
db.close # zavrieme databázu
V príklade vyššie používame abstraktnú formu databázy TC. Pomocou mena, ktoré predáme metóde open môžeme voliť medzi 6 podporovanými druhmi databáz.
| Názov | Spôsob volania |
|---|---|
| Tabuľka hashov v pamäti | „*“ |
| Binárny strom v pamäti | „+“ |
| Tabuľka hashov v súbore | názov súboru a prípona „.tch“ |
| B+strom v súbore | názov súboru a prípona „.tcb“ |
| Dlhé pole s fixnou dĺžkou v súbore | názov súboru a prípona „.tcf“ |
| Tabuľka v súbore | názov súboru a prípona „.tct“ |
Databáza v pamäti
Možno si budete myslieť, že existencia databázy čisto v pamäti je neopodstatnená, keď skriptovacie jazyky sami poskytujú rovnakú funkcionalitu v podobe asociatívnych polí. Avšak TC je oproti nim zväčša šetrnejšia na pamäť a rýchlejšia (viz. http://alpha.mixi.co.jp/blog/?p=791).
Databáza v súbore
Súborová databáza je vhodná na permanentné ukladanie dát, teda tradične použitie DBM. V prípade, že hľadáme záznam podľa konkrétneho kľúča, postačí nám hash tabuľka. Ak hľadáme v doméne kľúčov alebo podľa zhody na začiatku, je vhodné použiť databázu typu B+strom. V prípade, že sú kľúče po sebe nasledujúce číselné hodnoty, efektívne bude, ak použijeme dlhé pole s fixnou dĺžkou. Ak záznam nie je tvorený jednoduchým párom kľúč–hodnota, môžeme použiť tabuľku.
Tokyo-Tyrant
Avšak aj užitočná a rýchla databáza ako TC má svoje neduhy. Kvôli konzistencii dát k databáze nemôže pristupovať viac ako jeden proces v jednom čase. Prvý proces otvára databázu v režime zápisu, a preto druhý proces prirodzene musí čakať, kým prvý proces skončí. Ako sme spomenuli, databáza TC je prispôsobená modelu viacerých vlákien, no nie pre viacero procesov.
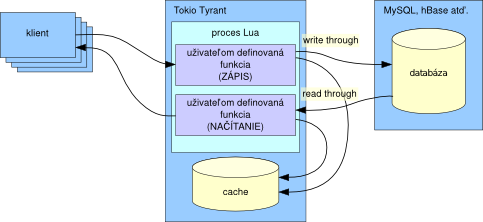
V prípade multiprocesových serverov, ako je napr. Apache, nakoniec potrebujeme nejakým spôsobom databázu medzi procesmi zdielať. A práve preto som vyvinul server Tokyo-Tyrant (ďalej len TT). Server je implementovaný ako jeden proces s exkluzívnym prístupom k jednej TC databáze, ktorý dokáže vyhovieť požiadavkám viacerých klientov súčasne.
Mohli by sme povedať, že TT je RPC vrstva nad TC. V skutočnosti je TT klientská API temer identická s API TC. Preto je prispôsobenie programov pôvodne napísaných pre TC veľmi jednoduché. Ako dôkaz si prosím pozrite nasledujúci príklad kódu v Ruby. Jediné, čo sa v kóde líši, je názov triedy a parameter predávaný metóde open. Zvyšok je identický s predošlou ukážkou.
require 'tokyotyrant'
db = TokyoTyrant::RDB::new # vytvoríme objekt databázy
db.open("localhost", 1978) # spojíme ju s adresou servera
db["foo"] = "bar" # priradíme hodnotu
printf("%sn", db["foo"]) # vypíšeme záznam
db.close # zavrieme databázu
TT natívne podporuje aj protokol memcached, takže ak chceme presunúť systém, ktorý pôvodne využíval memcached na TT, stačí zmeniť adresu servera.
V mixi (japonská sociálna sieť – pozn. prekl.), kde som zamestnaný, využívame práve podporu memcached protokolu v TT. Server TT je možné rozšíriť o skripty napísane v jazyku Lua a pomocou nich vykonávať ľubovolnú databázovú operáciu na strane servera. Úložiská kľúč-hodnota nepodporujú taký mocný jazyk ako SQL, no práve vďaka rozšíreniu pomocou skriptov je možné popísať databázové operácie na strane servera omnoho flexibilnejšie. TT je tak možné použiť ako transparentný cacheovací server alebo pri paralelnom spracovaní v modele MapReduce.
Záver
Databáza TC je moderná implementácia modelu DBM. Je to realizácia asociatívneho poľa v podobe úložiska kľúč–hodnota na úrovni súborového systému. Napriek tomu, že disponuje iba jednoduchými funkciami, je oproti relačným databázam neporovnateľne rýchlejšia. Databázový server TT je možné použiť ako RPC vrstvu nad TC, čo sa najviac zíde pri multiprocesových web serveroch. V tomto článku sme si predstavili iba malú časť funkcionality TC a TT. Podrobnejšie informácie sú uvedené v špecifikácii (http://1978th.net/tokyocabinet/spex-en.html), preto vám ju vrelo odporúčame. V sérii Tokyo produktov ďalej existuje vyhľadávač Tokyo Dystopia a CMS Tokyo Promenade (všetky produkty sú licencované pod LGPL), ktoré sú vyvíjané s rovnakým zápalom. Kontaktujte prosím autora, ak máte nejaké požiadavky alebo otázky.
Poznámka k překladu
Tento článok je založený na koncepte pred redakčnou úpravou, ktorým autor Mikio Hirabajaši prispel do japonského časopisu Software Design. Článok vyšiel ako súčasť špeciálneho vydania „Prednášky o úložiskách kľúč–hodnota pre zvedavých“ (v originále 「ほんとうに知りたいあなたのための key-value ストア講座」) Koncept pochádza z oficiálneho blogu autora a jeho japonský originál sa nachádza na http://1978th.net/tech/promenade.cgi?id=72.
Článok bol pre prekladateľa zaujímavý kvôli terminológii používanej v japonskom IT odvetví. Z článku je možné vidieť, že odborné termíny sú v japončine tvorené viacerými spôsobmi. Podľa druhu ich môžeme rozdeliť na termíny japonského (resp. sinojaponského) pôvodu, anglického pôvodu (fonetické výpožičky) a ich vzájomné kombinácie. V japončine sa na označenie asociatívnych polí (ang. associative arrays) používa termín 連想並列 [rensóheirecu], ktorý je tvorený sinojaponskými znakovými zloženinami. No na označenie termínu key v spojení key-value autor používa cudzie slovo – anglikanizmus キー [kí]. Ako výraz korešpondujúci anglickému value zase používa natívne japonské slovo 値 [atai]. V ojedinelých prípadoch, ako je anglický termín B+ tree, autor používa výraz B+木, ktorý je kombináciou písmena B z latinky, znamienka + a čínskeho logogramu pre strom 木.
Pri preklade som sa snažil dodržať pôvodnú štruktúru konceptu. No kvôli odlišnému slovosledu bolo nutné zmeniť poradie niektorých viet, poprípade rozdeliť niektoré vety na kratšie úseky. Počas tohto procesu mohlo dôjsť k malým významovým posunom, za čo sa vopred ospravedlňujem.
Prekladateľ nie je odborník na databázy a rád uvíta pripomienky v diskusii.
Kamil Mišúth
Student odboru ‚Japonský jazyk a medzikultúrna komunikácia‘ na
‚Katedre východoázijských štúdií‘ FiF UK v Bratislave. Zaujímá sa o open source a lingvistiku.



Teda, chapu pocestovani nekterych slov, ale „interfejs“, to snad nemyslite vazne :-)
podla mna to tiez mohol Kamil napisat po slovensky aj krajsie:
„medziksicht“ :-)
Spravnejsie je mozno „rozhranie“, ale podla mna to bolo aj tak celkom zrozumitelne
Urcite by bolo lepsie „rozhranie“ ako „interfejs“, no pri preklade mi to vobec nenapadlo. Divne. Zrejme som sa nechal prilis ovplyvnit japonskym textom, kde autor pouziva [intáfésu]. Avsak slovencina by takuto transkripciu anglickej vyslovnosti mala zvladnut. Je v podobnom duchu ako vikend, biznis, hardver, softver, etc. . Ci to po vyznamovej stranke prispelo k zrozumitelnosti, je nieco ine. Snad to pojde zmenit :D.
V povodom texte vystupovali omnoho zaludnejsie vyrazy ako napr. 命名規約, s ktorymi sa bolo treba popasovat. Ak ste clanku napriek tomu rozumeli → misia splnena.
Editorská poznámka: V textu jsem ponechal „interfejs“ právě proto, že slovenština používá bez problémů i „softvér“ (na rozdíl od češtiny, která preferuje originální tvary „software, interface“ a má pak problémy s flexí).
Článek je napsán ve slovenštině. A ta má jiná pravidla pro přejímání termínů než čeština.
Ano, na tom neco bude, potom se tedy omlouvam :)
domo arigato gozaimashita
どういたしまして[dóitašimašite]。
Rozhodně bude přínosné, když semtam nějaký článek z japonštiny přeložíte. Přece jenom je většině z nás tenhle jazyk vzdálený a oni asi ne všechno budou strkat gaidžinům pod dlouhý frňák, že… Je to jiný svět, asi i počíračově.
Díky i za lingvistickou poznámku.
Ještě tak překladatele z čínštiny…
Zdravim,
chcem sa opytat, ci poznate nejaku DB, ktora vie pri full-text vyhladavni typu %premenna% vyuzit index. Mysql to nevie… viem, ze oracle to vie, no rozmyslam nad nejakym noSQL, kedze mne by uplne stacil system key->value, pricom full-text vyhladavanie by mi stacilo v hodnote key. Cize ak to vie nejaka noSQL tak zbytocne budem kupovat oracle. A musi to fungovat s PHP.
Prosim poradte. dakujem
Vyhledávání typu %proměnná% (LIKE) není full-textové vyhledávání.
Potřebuješ full-textově vyhledávat v klíčích? Pak asi bude něco špatného v návrhu.
Např. PostgreSQL má full-textové vyhledávání a používá indexy (ono vlastně i to mysql, jen nesmíš používat LIKE, ale full-text). Viz např. Pavlův článek na Rootu: Úvaha ohledně zneužívání LIKE v databázích.
dobry den,
clanok som si precital, ale nie je to moj pripad, kedze ja mam prvky atomicke.
predstavte si pripad, ze mate napr. zoznam firiem, kde je 70 milionov zaznamov a potrebujete v nom hladat cez %like%. Ked som robil mensie projekty(do 5 milionov zaznamov) tak sa to robilo tak, ze cela tabulka bola v RAM. no teraz sa to neda, potrebujem DB, ktora to vie a nie je platena, ako oracle.
mysql ani PostgreSQL nevedia pouzit index na %like%. Klasicke full text som v mysql pouzival, ale to mi nepomoze.
dakujem
Zkuste právě TokyoCabinet, pouhým nahlédnutím na stránku projektu zjistíte, že obsahuje další moduly, mimo jiné cituji: „Full-text Search System (Tokyo Dystopia)“ stránka http://1978th.net/tokyocabinet/
Na vyhledávání ve stylu %like% bude asi nejlepší grep, awk nebo perl a data v obyčejném souboru. Běžná databáze zde nepomůže.
Bylo by však možné udělat indexy právě v TC jako rejstřík dvou- tří- čtyř- … znakových skupin a k tomu i rejstřík výskytů slov (fulltext). Mohlo by to být velmi rychlé a snadno realizovatelné. Indexový soubor bude sice větší než datový, ale to nám nevadí.