
CouchDB – tak trochu jiná databáze (3. část)

Dnes nás čeká poslední část miniseriálu o CouchDB, tak trochu jiné databázi. V této části se dozvíte, jak na replikaci, co dělat, když vám databáze zabírá moc místa, a o tom, jak pomocí pohledů dát datům strukturu.
Seriál: Nerelační databáze (11 dílů)
- CouchDB – tak trochu jiná databáze (1. část) 24. 8. 2009
- CouchDB – tak trochu jiná databáze (2. část) 31. 8. 2009
- CouchDB – tak trochu jiná databáze (3. část) 7. 9. 2009
- MySQL v roli neschémové databáze 6. 1. 2010
- Základy Amazon SimpleDB 30. 3. 2010
- Návrh databáze – NoSQL vs SQL 31. 3. 2010
- Amazon SimpleDB prakticky v PHP 15. 4. 2010
- Vyskúšajme si Tokyo Cabinet 4. 5. 2010
- Redis: key-value databáze v paměti i na disku 7. 10. 2010
- Přechod z MySQL na CouchDB, část první 17. 2. 2011
- Přechod z MySQL na CouchDB: Druhý díl 24. 2. 2011
Nálepky:
Replikace
Replikace je způsob, jak mezi dvěma databázemi (databází je v tomto případě myšlena konkrétní přihrádka, nikoli celý server) synchronizovat data. Určí se dvě databáze – zdrojová a cílová – a všechna data, co v cílové chybí, jsou do ní ze zdrojové překopírována. Je při tom využíváno ID dokumentů a jejich revizí. Zdrojová databáze může být lokální nebo vzdálená a stejně tak může být i cílová lokální nebo vzdálenou. Podmínkou je, že obě databáze musí existovat (i když nemusí obsahovat ani jeden dokument).
Řekněme, že chceme vytvořit repliku databáze s alby (a předpokládejme, že tam nějaká alba jsou). Replika bude lokální, takže pro ni vytvoříme databázi:
$ curl -X PUT http://localhost:5984/alba-replika/
{"ok":true} A poté spustíme samotnou replikaci (při opravdovém spuštění uvidíte místo tří teček údaje, týkající se replikace – kdy začala, skončila apod.):
$ curl -X POST -d '{"source":"alba","target":"alba-replika"}' http://localhost:5984/_replicate
{"ok":true,...} Replikace je jeden z důvodů, proč CouchDB nemůže sloužit jako verzovací systém – při replikacích se kopírují jen ta nejčerstvější data.
Vzdálená databáze se od lokální liší tím, že určíme, na jakém serveru se nachází – http://jiny-server:5984/jina-databaze/.
Stlačování (compaction)
MVCC (Multiversion Concurrency Control) má výhodu v tom, že nejsou potřeba žádné zámky, takže klienti nemusí na nic čekat. Ale jelikož se pokaždé vytváří úplně nová kopie dokumentu (a dokument může být docela velký), CouchDB si ukousne hezký kousek místa na disku. Vzhledem k tomu, že místo je levné, tak to většinou není až takový problém. Ale zase není neomezené. A proto je tu stlačování, při kterém se zahodí všechny nepotřebné (staré) revize a tím se uvolní místo.
Pokud byste měli velkou databázi alb, a ta se hodně měnila, starých revizí se zbavíte pomocí:
$ curl -X POST http://localhost:5984/alba/_compact
{"ok":true} Pohledy (views)
Pohledy jsou asi tou nejzáludnější věcí, na kterou u CouchDB narazíte, a tohle bude jen takové lehké nakousnutí. Pohledy jsou způsobem, jak dát nestrukturovaným datům uloženým v dokumentech strukturu.
Abychom měli nějaká data, se kterými se bude dát pracovat, vytvořme si takový menší adresář osob:
$ curl -X PUT http://localhost:5984/adresar/
{"ok":true}
$ curl -X PUT -d '{"jmeno":"Pavel"}' http://localhost:5984/adresar/4835de71c4900920222793a70f5ffd9f
{"ok":true,"id":"4835de71c4900920222793a70f5ffd9f","rev":"1-77c126bcd8ca8702f3f7d9aa6e9f0fae"}
$ curl -X PUT -d '{"jmeno":"Pepa"}' http://localhost:5984/adresar/f9767dc49c498129ab71b33dccee06d0
{"ok":true,"id":"f9767dc49c498129ab71b33dccee06d0","rev":"1-edd7e3f5f0e91940c7f633052170ef21"}
$ curl -X PUT -d '{"jmeno":"Vašek"}' http://localhost:5984/adresar/38d6642e9f4f80790e41351e80067285
{"ok":true,"id":"38d6642e9f4f80790e41351e80067285","rev":"1-595c448e9755c9b1183839d6a9c73d08"}
$ curl -X PUT -d '{"jmeno":"Honza"}' http://localhost:5984/adresar/7695e6a0dc219ec16c311e4eaa19483d
{"ok":true,"id":"7695e6a0dc219ec16c311e4eaa19483d","rev":"1-e98255a638f0f7874fe24e37c11e54a4"}
$ curl -X PUT -d '{"jmeno":"Marek"}' http://localhost:5984/adresar/5747a709954fe6ae95bac69ed7090af1
{"ok":true,"id":"5747a709954fe6ae95bac69ed7090af1","rev":"1-9efd5be58372c54b03eb5da604a77018"} Teď se už dostaneme k Futonu, tedy ke grafickému rozhraní CouchDB. Otevřte si adresu http://localhost:5984/_utils/. Měli byste vidět něco jako:
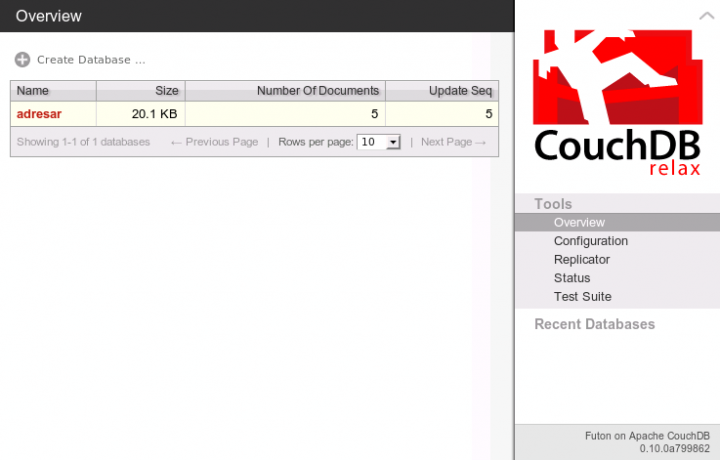
Nás zajímá databáze adresar, takže na ni klikneme:
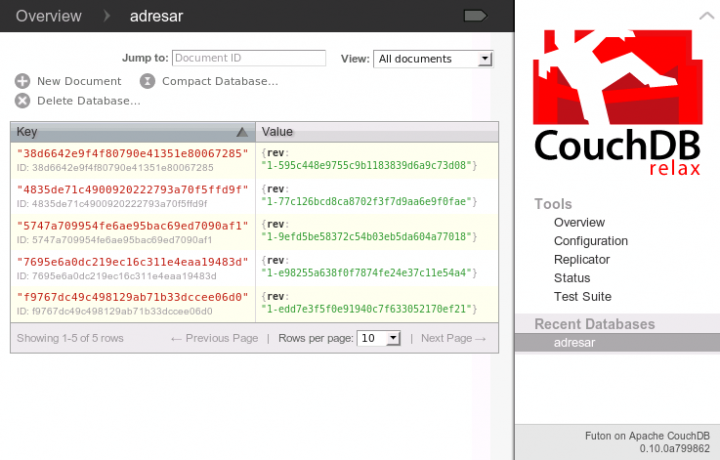
Jsou tu jednotlivé dokumenty. Pokud byste na některý z nich klikli, dostanete se na stránku, kde můžete dokument upravovat, přidávat a mazat přílohy atp. Ale nás zajímají pohledy, takže změníme zobrazení na dočasné pohledy:
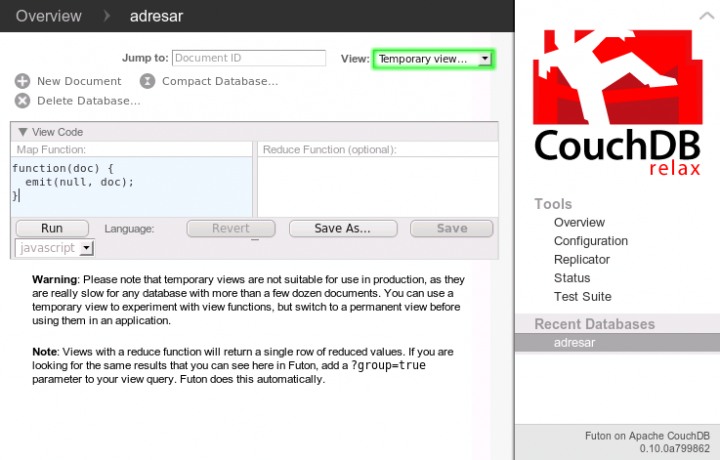
Jak Futon správně varuje, dočasné pohledy by se neměly používat v produkčním nasazení, jelikož se při každém zavolání pohledu musí celý přepočítat. Na chvilku si s tím však vystačíme.
Jeden pohled bychom tam měli mít připravený (jako na obrázku), takže ho spustíme pomocí tlačítka Run. Pokud znáte styl zpracování dat pomocí MapReduce, asi je vám jasné, proč to dopadlo, jak to dopadlo. Funkce map je volána pro každý dokument v databázi a emit() vypustí pod daným klíčem daná data. V tomto případě je vždy klíčem null a data jsou celý dokument. Ale pomocí různých podmínek můžete vypustit všelijaká data pod rozličnými klíči. Také se nemusíte omezovat jen na jedno volání emit() uvnitř map funkce – můžete emit() zavolat milionkrát a nemusíte ho také zavolat vůbec.
Kdybychom chtěli získat všechny dokumenty z databáze, funkce map by mohla vypadat následovně:
function(doc) {
emit(doc._id, {"rev" : doc._rev});
} Jako klíč je ID dokumentu a data jsou jeho revize. Popravdě řečeno takový pohled pro vás CouchDB připravuje automaticky a máte ho k dispozici na /<databáze>/_all_docs. Pro databázi adresar by to tedy byla adresa http://localhost:5984/…ar/_all_docs. Pokud byste rovnou chtěli získat i data dokumentů, přidejte query parametr ?include_docs=true – http://localhost:5984/…ar/_all_docs?….
Ale chtělo by to taky nějaký užitečný pohled. Jako map funkci zadejte tedy:
function(doc) {
emit(doc.jmeno, null);
} Co z toho bude? Spustíte-li pohled pomocí Run, uvidíte, že jsme na místě klíčů dostali jména v adresáři a na místě hodnot null – přesně to, co vypustí funkce emit(). Bystřejší už vidí, že řádky jsou seřazeny abecedně podle klíče.
Pohled si uložíme. Klikněte tedy na Save As…. Pokud se chcete držet článku, jako Design document zadejte adresar a jako View name podle-jmena. Máte stálý (permanentní) pohled a na ten se jednoduše můžete dotazovat pomocí HTTP metodou GET – http://localhost:5984/…/podle-jmena:
{"total_rows":5,"offset":0,"rows":[
{"id":"7695e6a0dc219ec16c311e4eaa19483d","key":"Honza","value":null},
{"id":"5747a709954fe6ae95bac69ed7090af1","key":"Marek","value":null},
{"id":"4835de71c4900920222793a70f5ffd9f","key":"Pavel","value":null},
{"id":"f9767dc49c498129ab71b33dccee06d0","key":"Pepa","value":null},
{"id":"38d6642e9f4f80790e41351e80067285","key":"Vau0161ek","value":null}
]} Vidíte výstup podobný tomu z _all_docs. Je zde počítadlo total_rows oznamující, kolik řádků očekávat; offset říkající, kolik jich bylo vynecháno; a pole rows, kde jsou již samotná data.
Pokud do adresy přidáte query parametr ?skip=4 , čtyři řádky budou přeskočeny a dostanete jenom:
{"total_rows":5,"offset":4,"rows":[
{"id":"38d6642e9f4f80790e41351e80067285","key":"Vau0161ek","value":null}
]} Pomocí parametru descending můžete určit, mají-li se řádky řadit vzestupně ( descending=false, výchozí), či sestupně ( descending=true). Parametry se samozřejmě dají různě kombinovat – ?skip=4&descending=true :
{"total_rows":5,"offset":4,"rows":[
{"id":"7695e6a0dc219ec16c311e4eaa19483d","key":"Honza","value":null}
]} Parametr limit zase určuje, kolik maximálně řádků se smí vrátit (ve výchozím stave bez limitu). Poté můžete ještě určit, jaký konkrétní klíč chcete pomocí key. A startkey a endkey dávají možnost zadat rozsah klíčů. Chcete všechny kontakty od P? Máte je mít:
{"total_rows":5,"offset":2,"rows":[
{"id":"4835de71c4900920222793a70f5ffd9f","key":"Pavel","value":null},
{"id":"f9767dc49c498129ab71b33dccee06d0","key":"Pepa","value":null}
]} Existuje ještě více parametrů, podle kterých můžete z pohledů vybírat řádky, které chcete. A v budoucnu možná ještě další přibudou. Všechny byste je měli najít na wiki.
Mnoho lidí se bojí, že jak CouchDB nemá schéma, jak to není všechno hezky v tabulce, tak nad daty ztratí veškerou kontrolu a všechno budou muset počítat v aplikaci (což se povětšinou nevyplatí). Pohledy CouchDB jsou důkazem, že to pravda není. Tohle bylo navíc jen takové zahřívací kolo – pravá legrace přichází, když se do všeho začnou míchat reduce funkce.
Stálé pohledy jsou předpočítané, resp. se počítají při prvním zavolání, takže žádné propastné prodlevy při dotazech na pohledy nehrozí – opět se (stejně jako u MVCC) obětovává místo ve prospěch rychlosti.
Na závěr
Toto bylo takové malé představení dokumentově orientované databáze CouchDB. Osobně mě někdy relační databáze docela vytáčejí, že něco „nejde“ udělat tak, jak bych si zrovna představoval (ano, jen do mě s tím, že to je jen kvůli tomu, že to neumím), tak se porozhlížím po jiných řešeních ukládání dat. CouchDB mě zaujala.
I když se přímo v dokumentaci píše, že CouchDB není relační databáze, ani náhrada za relační databáze, v článku jsem se srovnání právě s relačními databázemi, vzhledem k rozšířenosti a známosti jejich modelu mezi programátory, nemohl vyhnout. Myslím, že pro některé aplikace je CouchDB důstojnou alternativou relačních databází. Pro některé možná i vhodnějším řešením.
Doufám, že jsem CouchDB neudělal medvědí službu a tento článek vás zaujal alespoň natolik, že se třebas podíváte na její domovské stránky. Hlavní zdrojem inspirace pro příklady použité v článku je připravovaná kniha CouchDB: The Definitive Guide.
Jakub Kulhan
Autor programuje v Javascriptu, PHP, Javě, Golangu… ve všem možném. Ve volném čase probádává nejrůznější zákoutí světa programovacích jazyků a databází a všeho kolem nich.



v dnešní době rychlých změn to je nejlepší co můžete potkat.
CouchDB je na začátku cesty. Možná je to jen startovací van men šou. Aby něco jako protipól pro ty Notesy vzniklo.
Nový směr?
Nové nápady?
Možná ano a možná ne.
Napriklad pre tych ktory pouzivaju Python je tu uz nejaky ten rok databaza ZODB[1]
S backendom RelStorage[2] sa da jednoducho skalovat a replikovat
jej jedina nevyhoda je ze API je len pre Python, oproti CouchDB, ktora pouziva api HTTP
[1] http://pypi.python.org/…/ZODB3/3.8.3
[2] http://pypi.python.org/…torage/1.2.0
Slyšels někdy o SharePointu?
a uz si v tom nieco aj programoval ? alebo to len klikas ? to je velky rozdiel :)
programovat v SharePointe je masaker
A co Oracle XDB?
Odpovím Ti zcela ve stylu kovanejch lotusáků.
Takový kvíčení mrkváka hodno jest a táhni do hrobu.
Pokud nevíš vo co go, neporovnávej něco co funguje se sračkama.
Jako prgošš odkojený ne jen klasickými jazyky, koukám na ten váš šitopoint a je to hrúza.
Neberu tomu snahu, ale z hlediska uživatele je to děs. Pardon nechci.
Dále.
Musím tak dělat s njákým navišn.
Tak takovou sračku si strčte opravdu do pr…….
vazba na IE, každou chvíli topadne, prgoši nejsou schopný udělat změnu rychle.
KDO TOHLECTO VYMYSLEL – nevím, ale domnívám se, že tomu otevřel vrátka
Až začneš radit, co mám používat, tak si nejdřívě utři mléko na bradě.
To víš, mi starci bychom mohli uklouznout
Zdar
Díky za užitečný seriál o CouchDB. Nedávno jsem narazil na zmínku o podobném projektu nazvaném MongoDB. Takže pokud někoho CouchDB zaujala, koukněte se taky na MongoDB (abyste neměli rozhodování tak snadné ;). Možná by nebylo špatné udělat malé srovnání těchto dvou projektů (zmínka obsahovala názor, že MongoDB má „lepší“ dynamické dotazy).
Ano, rádi bychom v seriálu někdy pokračovali, jednak popisem dalších podobných databází (SimpleDB od Amazonu, MongoDB, BigTable, Cassandra, Voldemort, …), jednak nějakým praktickým tutorialem.
Docela zajímavý průvodce „Proč jsme přešli na MongoDB a ne na …“ vyšel nedávno zde: http://blog.boxedice.com/…-to-mongodb/
take se primlouvam za nejaky pekny srovnavaci, zastresujici clanek, ktery by predstavil rozdily mezi jednotlivymi nerelacnimi databazemi a (hlavne) ukazal moznosti jejich pouziti
na takovy clanek by plynule mohly navazovat dalsi, konkretizujici clanky…
Dik, o dokumentove orientovanych databazich jsem predtim neslysel. Kdyz prihledneme k veku autora, jsou tyto clanky skutecne uzasne ! Prosim pracuj a uc se dal a nikdy neprestan. Urcite budes studovat informatiku (pak se spravi takove detaily jako rozdil mezi map a hashmap a prijdou dalsi krasne veci jako funkcionalni programovani a lambda kalkul). Drzim Ti palce ! PS: mozna by Te zaujaly i objektove orientovane databaze, ktere jsou tez pro nektere druhy aplikaci vhodnejsi nez relacionalni databaze.
Děkuji za moc zajímavé články.
Tomáš
Teď – 24.února 2011 – jsem všechno podle článku postahoval a nainstalil (na Windows XP CZ blahé paměti…). A v š e c h n o funguje – po webu. Během pár minut. Práce s databází je vskutku „střemhlavá“ a globální. Very, very, very easy. Zdá se, že ty počítače začnou k něčemu být :-)