
DOM – načteme to do paměti

Rozhraní DOM (Document Object Model) je standardní rozhraní pro práci s dokumenty XML definované konsorciem W3C. Rozhraní definuje způsob, jakým se dokument XML mapuje na hierarchii objektů v paměti. V dnešním pokračování seriálu o XML a PHP si ukážeme, jak lze s tímto rozhraním pracovat v jazyce PHP5.
Seriál: Přehled podpory XML v PHP5 (6 dílů)
- Přehled podpory XML v PHP5 5. 10. 2009
- PHP a XML: SAX – čteme pěkně popořádku 12. 10. 2009
- XMLReader – když se zamotáme do SAX 19. 10. 2009
- DOM – načteme to do paměti 26. 10. 2009
- XPath – rychle to najdeme 2. 11. 2009
- XSLT – jazyk budoucnosti 9. 11. 2009
Nálepky:
Rozhraní DOM (Document Object Model) je standardní rozhraní pro práci s dokumenty XML definované konsorciem W3C. Rozhraní definuje způsob, jakým se dokument XML mapuje na hierarchii objektů v paměti. Každé části dokumentu, jako je element, atribut, textový uzel a podobně, odpovídá v paměti jeden objekt. Pomocí metod a vlastností dostupných na každém objektu můžeme zjišťovat druh uzlu, jaký ve stromu dokumentu XML zastupují, jejich název, obsah, seznam objektů reprezentujících dětské uzly, objekt zastupující rodiče uzlu atd.
Dokument je v paměti reprezentován jako objekt, který je instancí třídy DOMDocument. Pomocí metody load() je možné vytvořit DOM reprezentaci dokumentu XML uloženého v souboru:
$doc = new DomDocument();
$doc->load("dokument.xml");
Metoda load() přečte celý dokument XML a v paměti z něj vytvoří stromovou reprezentaci. Jednotlivé uzly jsou reprezentovány objekty, jak ukazuje obrázek 6 – „DOM strom pro ukázkový dokument“. Elementům odpovídají instance třídy DOMElement, atributům instance třídy DOMAttr a textovým uzlům pak instance třídy DOMText. U každého uzlu můžeme zjišťovat mnoho údajů, nejtypičtějšími je název uzlu a jeho hodnota. Tyto údaje jsou zachyceny i na obrázku – prostřední údaj každého uzlu je jméno uzlu a dolní údaj znázorňuje hodnotu uzlu.
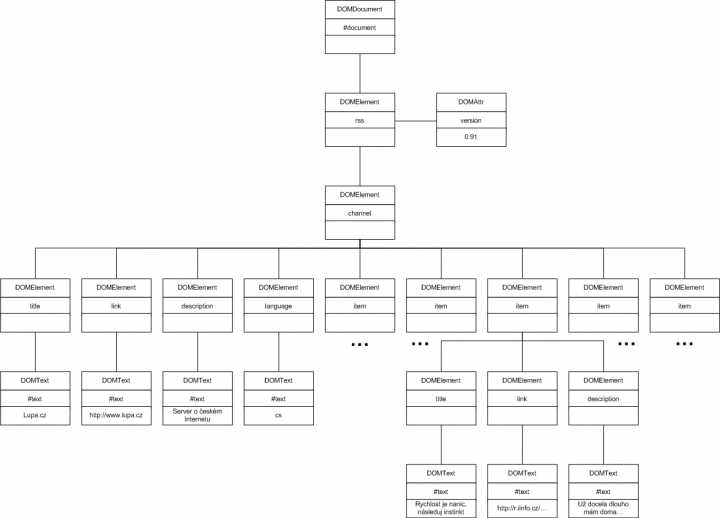
Protože všechny třídy použité při vytváření DOM stromu mají společného předka třídu DOMNode, mají mnoho společných metod a vlastností. Jednak se jedná o vlastnosti, které dovolují zjistit jméno uzlu (nodeName) či jeho hodnotu (nodeValue). Další vlastnosti umožňují pohyb po stromu dokumentu. Vlastnost childNodes vrací seznam dětských uzlů a naopak parentNode vrací rodiče.
Používat tyto vlastnosti pro výběr určitých částí dokumentu je však většinou velmi pracné. Obvykle je mnohem pohodlnější pro výběr částí dokumentu využít dotazovací jazyk XPath, jak si ukážeme dále. Budeme-li však chtít zůstat u standardních nástrojů, které nabízí rozhraní DOM, může se nám hodit metoda getElementsByTagName(), která vrací seznam uzlů odpovídající elementům s daným názvem. Použití této metody ilustruje i následující příklad, který využívá rozhraní DOM pro zobrazení jednoduchého dokumentu RSS.
Příklad 5. Čtení XML pomocí rozhraní DOM – dom.php
<!DOCTYPE HTML PUBLIC '-//W3C//DTD HTML 4.01//EN'>
<html lang="cs">
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<title>Přehled zpráv</title>
</head>
<body>
<?php
// vytvoření objektu pro dokument XML
$doc = new DomDocument();
// načtení dokumentu do paměti do DOM stromu
$doc->load("../data/luparss.xml");
?>
<h1>Přehled aktuálních zpráv ze serveru
<a href="<?php echo htmlspecialchars($doc->getElementsByTagName("link")->item(0)->textContent, ENT_QUOTES)?>"><?php echo htmlspecialchars($doc->getElementsByTagName("title")->item(0)->textContent)?></a>
</h1>
<dl>
<?php
// výběr všech elementů, které se jmenují item
$polozky = $doc->getElementsByTagName("item");
// postupné zpracování elementů item
foreach($polozky as $polozka)
{
echo "<dt><a href='" . htmlspecialchars($polozka->getElementsByTagName("link")->item(0)->textContent, ENT_QUOTES) . "'>" . htmlspecialchars(($polozka->getElementsByTagName("title")->item(0)->textContent)) . "</a></dt>n";
echo "<dd>" . htmlspecialchars(($polozka->getElementsByTagName("description")->item(0)->textContent)) . "</dd>n";
}
?>
</dl>
</body>
</html>
Chcete se naučit o PHP víc?
Akademie Root.cz pořádá školení Kurz programování v PHP5. Jednodenní kurz programování v PHP 5 je určen všem webovým vývojářům, kteří se chtějí do hloubky seznámit a sžít s programovacím jazykem PHP ve verzi 5. První část kurzu je zaměřena na nový objektový model se všemi jeho vlastnostmi, ošetření chyb pomocí výjimek a efektivní využití těchto konceptů. Druhá část je zaměřena na nové knihovny PHP 5, především pro práci s databázemi, XML a objekty. Pozornost je věnována i zajištění kompatibility s PHP 4, přechodu z této verze a výhledu na PHP 6. Máte zájem o jiné školení? Napište nám!
Celý skript pracuje na velmi jednoduchém principu. Nejprve do proměnné $doc načte DOM strom celého dokumentu. Následně je potřeba vypsat obsah elementů link a title. Nejjednodušší způsob, jak tyto elementy vybrat, je použít metodu getElementsByTagName(). Ta nám vrátí seznam elementů s daným jménem. Nás zajímá pouze první takový element, na který se můžeme odkázat pomocí zápisu:
$doc->getElementsByTagName("link")->item(0)
Výraz přitom vrací objekt z DOM stromu, instanci třídy DOMElement. Můžeme na ní tedy volat libovolné metody nebo pracovat s libovolnými vlastnostmi, které tato třída nabízí. My potřebujeme znát textový obsah elementu. Ten jde získat tak, že projdeme všechny na něj navěšené textové uzly a spojíme je do jedné hodnoty. Tento postup by však byl velmi pracný, a proto rozhraní DOM nabízí jednodušší postup. Na libovolném uzlu stromu můžeme číst vlastnost textContent, která vrací textovou hodnotu daného uzlu. Zápis
$doc->getElementsByTagName("link")->item(0)->textContent
tak vrací text, který je uzavřený v prvním elementu link vyskytujícím se v dokumentu.
V další části skript vypisuje všechny položky. Pro výběr položek opět využijeme metodu getElementsByTagName() a její výsledek si uložíme do proměnné.
$polozky = $doc->getElementsByTagName("item");
Výsledný seznam uzlů je instance třídy DOMNodeList. Tato třída definuje vlastnost length vracející počet uzlů v seznamu a metodu item(), která vrací uzel na dané pozici v seznamu. Tato vlastnost a metoda jsou dostačující pro napsání kódu, který projde v seznamu jeden uzel po druhém. V praxi se však využívá toho, že třída DOMNodeList implementuje rozhraní iterátoru a jde ji zpracovat klasickým příkazem foreach.
foreach($polozky as $polozka)
{
…
}
Cyklus se provede pro každý element item, jemu odpovídající uzel DOM stromu bude uvnitř těla cyklu dostupný v proměnné $polozka. Toho využíváme i pro čtení podelementů položky, jako jsou link, title a description. Zavoláme-li totiž metodu getElementsByTagName() na jiném uzlu než kořenovém, prohledává jen potomky daného uzlu, a ne celý DOM strom. Využijeme ji proto pro pohodlné zjištění názvu a popisu položky a odkazu na zdroj, který popisuje.
Průchod stromem DOM za využití základních metod není zrovna pohodlný. V mnoha aplikacích je proto pohodlnější využít k výběru potřebných uzlů stromu nějaký prostředek vyšší úrovně. Takovým prostředkem je i dotazovací jazyk XPath, na jehož použití v PHP se příště podíváme.
Více informací o knize naleznete na stránkách nadavatelství Grada a na stránkách autora.



Zmínil bych existenci funkce
simplexml_import_dom, která dokáže načístDOMNodedo struktury SimpleXML. Za hlavní výhodu DOMu považuji to, že dokáže načíst i nevalidní HTML dokument, což jiné XML extenze nezvládnou. API DOMu je totiž velmi krkolomné.<reklama>A tohle všechno je právě popsáno v knížce</reklama>
BTW, proč se najdenou v Opeře přestaly zobrazovat komentáře?
připadně se dá nevalidní dokument před načtením opravit pomocí Tidy, pokud je dostupné
Pár poznámek k tomu, jak se DOM extenze chová dle různých nastavení: http://phpfashion.com/…rni-poznamky (v různých verzích PHP se to možná liší)
<reklama>A tohle všechno je právě popsáno v knížce</reklama>
A navíc, mě se XML katalogy podařilo rozchodit. ;-)