
Grafová terminologie a dostupné technologie

Tento seriál vás seznámí s grafovou databází Neo4j. V první řadě si představíme databázový systém spolu s jeho vlastnostmi, poté si popíšeme základní grafové pojmy a moderní termíny pro interpretaci grafů a také základy pro optimalizaci databázové části serveru.
Seriál: Grafová databáze Neo4j (4 díly)
- Grafová terminologie a dostupné technologie 21. 10. 2013
- Přehled grafových databází 8. 11. 2013
- Modelování dat v Neo4j – Metodika a obousměrné hrany 8. 1. 2014
- Webové rozhraní Neo4j 7. 3. 2014
Nálepky:
NoSQL
Termín NoSQL vznikl jako pojmenování pro rodinu nerelačních datových úložišť, kde se velmi dlouho říkalo, že SQL (Structured Query Language) nepotřebujeme a nebudeme ho používat. Další konotací je NOSQL = Not Only SQL, kde se naopak nepojednává o alternativě, ale o dostupnosti dalších možností.
Na první pohled je rozdílem dotazovací jazyk, jak nám již prozradila rozprava nad názvem. Nadále oproti relačním databázím umožňují s příchodem nových trendů efektivněji zpracovávat data, jejichž vlastnosti neodpovídají tradičnímu relačnímu modelu.
Právě ACID neboli atomicita, konzistence, izolovanost a trvalost jsou hlavními principy relačního databázového modelu, avšak pro NoSQL systémy nejsou závazné, neboť výkon pro NoSQL databázi je podstatně důležitější než její konzistence. Jinak řečeno, mají jednodušší datový model než relační databáze, aby mohly garantovat škálovatelnost, dostupnost apod. Škálování typicky probíhá na horizontální úrovni v podobě přidání dalších serverů, což mimo jiné přináší výhodu odolnosti vůči chybám.
NoSQL vzniklo kvůli trendům
- vzrůstající objem dat
- rostoucí propojenost dat
- ztráta předvídatelné struktury
- současná architektura aplikací (aplikace mají více databází jako Cloud)
Graf
Obecný graf jako datová struktura nemá začátek ani konec. Je definován v podobě dvojice množin vrcholů (Vertices) a hran (Edges). Rozlišujeme grafy orientované a neorientované. Orientaci rozpoznáváme pomocí hran, které nám v grafu určují směr z daného vrcholu do dalšího.
- Vertices – neprázdná množina vrcholů (disjunktní s množinou Edges)
- Edges – množina hran (disjunktní s množinou Vertices)
Vrchol (Vertex)
Vrchol (někdy také uzel) je část grafové struktury, která nám zastupuje objekty nebo jejich referenci.
Hrana (Edge)
Hrana (někdy také vztah) znázorňuje konexe mezi jednotlivými vrcholy.
Základní typy hran
- neorientovaná hrana – neuspořádaná dvojice vrcholů, která nemá určený směr průchodu a hranou lze procházet oběma směry
- orientovaná hrana – uspořádaná dvojice vrcholů, která má určený směr průchodu a hranou lze procházet pouze vyznačeným směrem
- násobné hrany – více hran spojujících stejné vrcholy
- smyčka – hrana vedoucí z vrcholu do téhož vrcholu, tedy do sebe samotné

Příklad orientovaného grafu
Strom
Stromem se nazývají souvislé grafy, které neobsahují kružnice. Po odebrání jedné z hran je porušena souvislost a přidáním vzniká kružnice. Hierarchickou strukturou je v teorii grafů přirovnáván k acyklickému grafu s jedním kořenem.
Kořen
Kořen stromu je nejvyšší uzel, který nemá žádného rodiče a je v grafu ojedinělý.
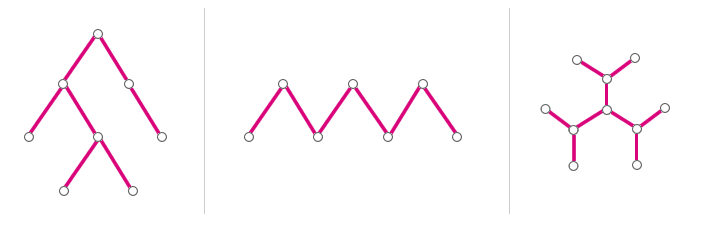
Příklady grafových stromů
Grafová databáze
Grafové databáze jsou jednou z kategorií NoSQL, jak již bylo představeno v úvodu kapitoly. Z obecné definice lze označit za grafovou databázi jakýkoliv systém, který poskytuje tzv. bezindexovou sousednost, neboli každý vrchol obsahuje přímé odkazy na své sousedy a tím nám odpadá nutnost používání indexů.
Nativně ukládají grafové struktury, přičemž se eliminují všechny nepříjemné problémy s pokusy uložit graf (strom) do relační databáze, která je pro tyto účely nepřirozená, poněvadž se neobejde bez výpočetně drahých operací JOIN. Nadále jsou ideální pro mapování na objektovou strukturu aplikací bez rigidního modelu, což zaručuje volnost schéma libovolně rozvíjet. Naopak v porovnání relační databáze velmi dobře pracují s tabulárními daty, nad kterými jsou prováděny agregační a často se opakující úlohy.
Díky progresivitě sociálních projektů, kde nám velmi záleží na propojenosti mezi daty a následného data miningu, se stávají budoucností úložišť. Vesměs jsou vhodným řešením pro grafové úlohy, jako například hledání nejkratších cest či hledání komunit v sociální síti.
Traverzování
Traverzování neboli průchod nám umožňuje navštívit všechny vrcholy grafu. Celý proces si můžeme představit jako systematické putování grafem po jednotlivých vrcholech a hranách. Způsob, jakým je průchod realizován, určují zvolené algoritmy, jakými jsou například průchod do hloubky či do šířky .
Sociogram
V internetovém kontextu se jedná o social graph, což je grafické znázornění sociálních vztahů. Podle využití můžeme znázorňovat vztahy na základě různých kriterií, mezi ně lze zařadit sympatie, případně i antipatie nebo také vztahy vlivu, komunikace aj. Zpracování vlastností sociogramu bude jednou z částí výsledné grafové databáze, kde půjde o přátelství mezi uživateli.
Interest graph
Hlavní rozdíl oproti sociogramu spočívá v tom, že není požadovaná známost mezi uživateli, ale důležité je, jestli spolu sdílí nějaké zájmy. Výsledkem práce získáme graf, který bude obohacen o prvky zmíněného Interest graphu v podobě navštívených akcí nebo like stránek.
Cache
Cache je označení pro vyrovnávací paměť, se kterou se v informatice můžeme setkat na mnoha místech, ať už jde o funkci webového prohlížeče, který využívá cache pro dočasné ukládání načtených stránek a jejich částí, tak i v problematice databází. Vždy s každou přijatou odpovědí dochází k rozhodnutí, zda budou data uložena, či nikoliv. Snažíme se tím předejít situacím, ve kterých by se pracovalo zastaralými nebo jinak nevhodnými daty. Zprovoznění cache spolu s její rozhodovací politikou omezí do značné míry komunikaci mezi klientem a serverem, což v důsledku posílí výkonu serveru.
Log
Log soubor zaznamenává informace o chování běhu programu. Typicky se jedná o obyčejný textový soubor s příponou .log. Úroveň obsáhlosti, tzv. jak a kolik detailních informací se bude ukládat, je povětšinou možné nastavit či úplně vypnout.
Pokračování příště
V dalším dílu uvedeme přehled grafových databází.
Zdroje
- HOLÝ, J. (2012). Grafové databáze a neo4j .
- BACHMAN, M. (2013). Introduction to Neo4j (Czech).
- MAŠEK, J. (2012). Aplikace pro zpracování a ukládání sociálních vztahů (Diplomová práce). Fakulta informačních technologií ČVUT v Praze.
- HORDĚJČUK, V. (n.d.). Teorie grafů.
- LTD, W. I. S. I. P. (2012). Data Structures.
- ADAMCHIK, V. (2005). Graph Theory. Carnegie Mellon University.
- JIROVSKÝ, L. (n.d.). Stromy.
- ENCYCLOPEDIA. Graph database.
- TECHNOLOGY, N. (2013). Intro to Neo4j .
- WITTMAN, T. (n.d.). Lecture 18: Tree Traversals. UCLA Department of Mathematics.
- ENCYCLOPEDIA. Social graph.
- ENCYCLOPEDIA. Sociogram.
- ENCYCLOPEDIA. Interest Graph.
- BANKA, F. (2008). Cache v prohlížečích.
- JIROVSKÝ, L. (2013). Orientované grafy.
- JIROVSKÝ, L. (2013). Stromy.
Článek původně vyšel na webu neo4j.cz.
Jaroslav Ramba
Lidé se bojí monster a monstra se bojí Jaroslava Ramby. On je muž mála slov, ale když jde o činy, v jeho oboru se mu nikdo nevyrovná!



Dobry zacatek, definice jsou potreba, tesim se na pokracovani.
Díky za pochvalu. Věřím, že další se také budou líbit…:)
Na neo4j jsem se chtěl zrovna podívat, nedávno jsem si stáhl jejich knihu, takže se těším na pokračování!
Po tom letním seriálu mi to vrací důvěru ve zdroják…
zaujimalo by ma na ktore casti neo4j sa budu dalsie clanky sustredit?
cypher, gremlin, rest api, java api?
mozme ocakavat nejake best practices pri modelovani? nejake tipy na optimalizaciu?
dufam, ze dalsi clanky pojdu pekne do hlbky
ps: skoda, ze sa z neo4j stava mainstream… :)
Nechci moc prozrazovat, ale můžete se těšit na REST API, Cypher, „best practices“ pro modelování a třeba i ty tipy na optimalizaci. Záleží i na vás čtenářích, které témata by se mohla do seriálu zahrnout…
O čem by jste se chtěli v seriálu dozvědět?
mna napriklad zaujimaju veci ako co najoptimalnejsie vytiahnut vsetky nody urciteho type(ci cez referencny node, z indexu, cez label, cez cypher), ako najlepsie natiahnut node aj so vsetkymi naviazanymi nodami, priklad user, ktory ma nejake settings, prava atd, kazde je dalsi node a spolu tvoria jednu entitu. je lepsi cypher alebo iterovanie cez relationships?
potom ukazky zlozitejsich modelov, cypher queries. kedy je lepsie nejake vlastnosti vytihanut do zvlast nodu
a nakoniec ako vytvorit nejaky recommendation engine alebo nejaku predikciu spravania na zaklade historickych dat :D
Cypher dotazy si určitě ukážeme – putování přes hrany a následné vyhodnocení… Budu se snažit, abych v dalších dílech udělal průnik tvých požadavků s obsahem seriálu :)
Super napad na celou serii clanku! :-) Pokusim se Jardovi trochu pomoct a dat neco dohromady. Na nektere otazky by mohl odpovedet serial, ktery jsem nedavno zacal anglicky na http://www.graphaware.com/blog.
Jinak v nekolika vetach: nody urciteho typu nejlepe vytahnout pres labels, ale az v Neo4j 2.0. V predchozich verzich je asi nejlepsi udelat si nodu reprezentujici ten typ a TYPE_OF relationship k nemu.
Cypher vs. Java: ani jedno neni lepsi nebo horsi, zalezi na pouziti. Java API je porad o mnoho rychlejsi nez Cypher, to se bude pomalu menit, ale bude to nejakou chvili trvat. Ve 2.0 to porad plati. Java je imperativni: rikas, jak chces graf prochazet. Cypher je deklarativni: rikas, co chces a databaze muze dotaz optimalizovat podle toho, co o Tvem grafu vi.
Recommendations jsou zajimave tema, hodne se tim zabyvaji kluci z http://www.reco4j.org/
Jasne ze Java bude rychlejsia. Možno by este stalo za to ukázat ako si spravit plugin do neo4j.
ja inak používam neo4j s php, takže som odkázány na rest api
Michal s pluginy (service) má zkušenosti, takže bychom něco dohromady dát mohli…
Zarazil jsem se už nad několika definicema. Ale myšlenka „[grafy] …jsou vhodným řešením pro grafové úlohy“ je na mě asi moc hluboká. Není to spíš obráceně – grafy (grafové struktury) dávají vznik novým úlohám – např. najít nejkratší cestu, nejmenší kostru…
Věta se neodkazuje na grafy, ale na grafové databáze – nadpis sekce
Co to je kružnice, výška uzlu, cyklus, acyklický graf
Naprosto souhlasím, že je dobré znám další definice grafů. Kdyby byl zájem, poskytnu zdroje pro prohloubení obecných grafových znalostí.
Zmínil jsem definice, s kterými se v dalších článcích budeme setkávat. Pokud použiji nějaký nový termín, tak ho hned i zadefinuji.
IMHO ty NoSQL pindy na začátku si mohl autor odpustit. Jednak je NoSQL fenomén, který by vydal na samostatný seriál, a tudíž těch pár odstavců nutně zjednodušuje, podle mne až nepřiměřeně, jednak konkrétně Neo4J je plně ACID compliant a umí i XA transakce :-)
A nejen to http://docs.neo4j.org/chunked/milestone/introduction-highlights.html :)
autorův medailonek „muž mála slov“ mě v souvislosti s obsáhlým úvodem pobavil, ale začíná to zajímavě, těším se na pokračování.
Jen prosím pozor na nepřesnosti – „nepříjemné problémy s pokusy uložit graf (strom) do relační databáze, která je pro tyto účely nepřirozená, poněvadž se neobejde bez výpočetně drahých operací JOIN“
Ano, práce se stromy není v relační DB zrovna elegantní, ale existují metody jako traverzování kolem stromu, nebo genealogické stromy (genealogický identifikátor), které jsou poměrně použitelné. Strašení čtenářů JOINem zde není na místě.
Díky moc za skvělý komentář. Máš pravdu, že nadstavby pro relační databáze existují a mohou v mnoha případech pomoci. Ovšem pokud data rostou, bude vše stále rychle fungovat? Vyvíjí se kupředu? Jakou mají podporu? Jak se s nimi pracuje?
Píše se to o mně na csfd od doby, co jsem natočil Rambo: Do pekla a zpět… :)