
Jak na přelkepy 2: standardizace pomocí fonetických algoritmů

Ve finále Ligy mistrů hrál i Bastian Schweinsteiger, Franck Ribéry, Anatoliy Tymoshchuk, José Bosingwa, Florent Malouda. Zvládnete to přečíst? A zvládnete to i stejně napsat? Já ne.
Nálepky:
A další otázka. Bývalý lybijský vůdce* se jmenoval?
- Muammar Kaddáfí
- Moammar Gadhafi
- Muammar Qaddafi
- Muammar Gaddafi
Všechno, závisí, na který zápis jména právě narazíte – označuje tu samou osobu.
Redaktorka ABC News našla 112 způsobů zapsání tohoto jména (a to brala do úvahy jenom vybrané zdroje).
Pokud budete chtít hledat toto jméno v textu, elegantním řešením může být (pro část Kaddáfí bez diakritiky) použití regulárního výrazu b[KG]h?add?af?fi$b.
Podívejme se na to ale jinak. Uvažujme podobnosti v databáze krátkých textových řetězců (například příjmení).
* – Problém se zápisem jména není jenom u libyjských politiků. Taky není jednoznačné, zda je ministr zahraničních věcí Karel nebo německy Karl a bývalý ministr dopravy není Gustáv, ale Gustav (to jsou jenom příklady z posledních 2 vlád).
Ekvivalence díky standardizaci
Pro potřeby vyhledávání (například proti existujícímu seznamu osob nebo množině nejčastějších slov) můžeme použít i standardizaci. Za standardizaci pro potřebu tohoto článku budu považovat nahrazení textu (řekneme jméno osoby) nějakým výrazem – reprezentantem, který vznikl z textu pro potřeby další analýzy. Standardizací může být například odstranění diakritiky, úprava na velká písmena, odstranění nealfanumerických znaků a samohlásek, vyhození titulů, nahrazení dvou stejných znaků následujících za sebou stejným znakem a podobně. Řekneme, že podobnost 2 slov na základě standardizace znamená, že tato dvě slova mají stejného reprezentanta.Tato podobnost má výhodu, že je nejen reflexivní a symetrická, ale i tranzitivní (tým se liší od Levenstheina i od Jaro-Winkler z minulého článku). Podobnost na základě standardizace je tedy ekvivalence. Díky tomu může být reprezentant v naší DB indexován a tak se samotné vyhledávání výrazně zrychlí (ale časově náročnější budou DML SQL příkazy).
Fonetické algoritmy
V tomto pohledu je však i použití fonetických algoritmů standardizací. Fonetické algoritmy vycházejí z různých přepisů zvukové podoby jednotlivých slov a hledají k slovu nejlepšího reprezentanta.
Podívejme se na slovo Kaddáfi z výše uvedeného seznamu pomocí nejznámějších fonetických algoritmů (bez diakritiky). V tabulce jsem použil implementaci z VB pro Excel. Stejná barva vyjadřuje stejného reprezentanta.
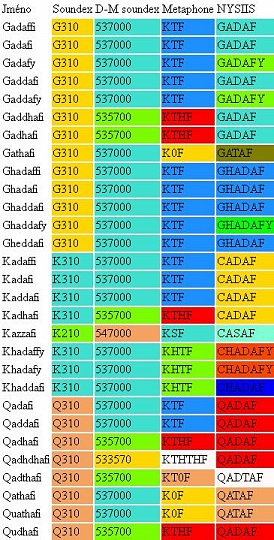
Tabulku najdete i v textové podobě.
Soundex (rok 1918) je nejznámější a byl vyvinut pro potřeby opětovné analýzy výsledků sčítání lidu v USA (fonetické algoritmy se na tento typ úkolů skvěle hodí – máte mnoho záznamů od lidí původem z různých častí světa a přepis jejich jmen do latinky není jednoznačný, navíc děláte analýzu až po získání všech dat).
Jak funguje soundex:
- Zachová se první písmeno a ze zbytku se vyhodí písmena a, e, i, o, u, y, h, w.
- Druhé a další písmeno se nahradí číslicí dle schématu.
- b, f, p, v ⇒ 1
- c, g, j, k, q, s, x, z ⇒ 2
- d, t ⇒ 3
- l ⇒ 4
- m, n ⇒ 5
- r ⇒ 6
- Dvě stejná čísla za sebou se nahradí jednou číslicí.
- Pokud je výraz delší než 4 znaky, ořízne se zleva na 4 znaky.
- Pokud je výraz kratší než 4 znaky, doplní se zprava na 4 znaky číslicí 0.
Vidíme, že pokud je špatně zapsáno první písmeno nebo narazíme na prohození souhlásek nebo na jejich přidání nebo odebrání (pokud ovlivní výsledek), tak nám soundex nepomůže.
D-M soundex (1985), taky židovský index neboli východoevropský index, je novější a vytváří k slovu číselné reprezentanty (pozor, může jich být i víc – takže opatrně s tou ekvivalencí). Do úvahy bere i písmena s diakritikou, a to z polské nebo rumunské abecedy.
Metaphon (1990) vychází z anglické výslovnosti. Existuje i verze Double metaphone (2000), který se snaží kromě jiné vzít do úvahy i slova slovanského původu. Stejného autora má i Metaphone 3 (2009).
NYSIIS (1970) je algoritmus vyvinutý v rámci New York State Identification and Intelligence System. Je o 2,7 % lepší než soundex. Detaily v přehledné online verzi.
Existují i další fonetické algoritmy jako caverphone, MRA,…
Použití fonetických algoritmů (v češtině)
Fonetické algoritmy se hodí, pokud nevíme, jak máme slovo napsat, pokud známe jeho zvukovou podobu. Naopak se nehodí, pokud uděláme ve slově „obyčejný“ překlep (tedy pokud nejde o překlep „správným“ způsobem). Zvláště se fonetické algoritmy hodí ke standardizaci údajů získaných přes zaznamenávání hlasu, což je stále aktuálnější (uměl vás váš mobil poslechnout před 10 lety?).
Na druhou stranu fonetické algoritmy jednotlivá slova často výrazně upraví, a tak můžou vrátit stejné reprezentanty pro výrazně odlišná slova. Například soundex vrátí pro slova Novák a Neubyfekeqoax stejnou hodnotu – N120.
Soundex funguje i pro některé typické chyby v češtině jako i/y nebo s/z. Nicméně použití fonetických algoritmů pro libovolné české slovo je díky blízkosti psané a mluvené formy v češtině málo přínosné (oproti angličtině).
Existují ale skupiny slov, u kterých to v češtině má smysl, a to například u jména a příjmení (s německým, ukrajinským nebo vietnamským původem), odborné výrazy a obecně slova přijímaná z jiných jazyků. Tam se fonetické algoritmy hodí. Například Levensteinh, Levenstajn, Levenshtein, Levensten i Levhenstein mají soundex L152.
Peter Brejčák
Vystudoval matematickou statistiku na MFF UK, Pracuje jako matematik pro vyhledávač hotelů trivago



Použití příkladu jména Muammar Kaddafi sice vypadá jako vhodný příklad, ale stejně jako tomu bylo u Ussamy bin Ládina – dává smysl jen v „anglofonních“ zemích. Rozpis přes soundex je sice fajn, ale jeho jméno se takhle nevyslovuje. To, co uvádíte jako fonetický přepis, je ve skutečnosti zkomolenina vyprodukovaná lidmi, kteří originál neumí vyslovit.
Nic si z toho nedělejte. Arabštinu jsem se učil rok a ačkoliv jsem se naučil obstojně psát, tak vyslovit to jméno správně také neumím. Na to tam těch chrochtacích a neznělých hlásek mají příliš. Pak to jméno slyšíte od araba tak, jak se správně vyslovuje, a vůbec vás nenapadne, že to je právě ono. On ani ten Korán vlastně není korán, protože „o“ nemají a „rá“ nevysloví spojeně. Prostě se arabštině v příkladech vyhněte. A čínštině také. Obecně čemukoliv, co ani neumíte správně vyslovit, natož napsat.
Já si naopak myslím, že slova, která se (obecně často) neumí správně vyslovit či zapsat jsou z praktického pohledu skvělou oblastí pro překlepy. Můžeme slovíčkařit, co je to ještě „překlep“ a kdy tomu už říkat nějak jinak, ale z pohledu algoritmů a programování, na tom nesejde.
Tys asi moc nepochopil, o čem ten článek je, co :)
Děkuji za připomínku, ale řešíme jiný problém. Vám jde o správný zápis. To v článku neřeším. Pro programátora je vstupem mnoho textových zápisů v latince a nemůže se vyhnout slovům arabského původu. Uvedené algoritmy pomáhají ve vyhledávání jiných zápisů stejného slova. Neřeším, co je správné a lepší, ale hledám podobnosti. A proto je naopak takové použití vhodné (jak uvádí Martin Hassman).
Uvedený příklad je z praxe a přiznám se, že nevím, jaký je jednoznačný a správný přepis jména a zda vůbec existuje. Neřeším to.
Rozumím, řešíte jiný problém. Já jen upozorňuji, že jako příklad jste si vybral něco, kde jsou ty problémy ve skutečnosti dva. Jeden jsou různé zápisy a druhý je ten, že přepis arabštiny prostě není zvládnutý. Soundex je příkladem naprosto nevhodného algoritmu, protože nerespektuje tvorbu slov v arabštině. Oni pouhým zdvojením souhlásky (d vs dd), záměnou délky samohlásky nebo záměnou znělé hlásky za neznělou tvoří jiné slovo s diametrálně jiným významem. Jako kdyby v češtině „svatba“ znamenana svatbu a „svadba“ potápění. Nehledě na to, že plno těhle nuancí se do zápisu v latince ani nedostane. Takže právě to „jiný zápis stejného slova“ je pro arabštinu zatím neřešitelný problém už jen proto, že neexistuje ani kvalitní přepis arabštiny do latinky. Vyhnul bych se jí obloukem a třebas čínštině hned dvěma oblouky.
Se tomu vyhněte třeba dvěma oblouky, ale jsou lidi co to holt musí udělat :)
Chcete říct, že Arabové nemají standardizovaný přepis do latinky? Zrovna vámi vybraná čínština ho má. Má jich několik, některé jsou lepší a některé jsou posvěcené čínskou vládou. Takže čínštinu bych za vyřešenou viděl (teď neřeším rozdílnou výslovnost ideografů, ale přepis fonetiky).
A jak se má takováto perverznost správně přečíst, když angličtina nemá fonetický pravopis, hm? Nebo naopak zapsat do angličtiny neanglické slovo, chci-li, aby ho přečetli co nejsprávněji? Na vyslovení ruských jmen rezignují i anglofónní, když to vidějí v psané podobě. Kombinace „shch“ je pro anglicky mluvícího už od pohledu nevyslovitelná, „chuk“ může jeden vyslovit jako „čuk“ a jiný zase jako „čak“, „tymo“ zas jeden vysloví jako „tymo“ a druhý „tajmo“. Neboli nejen že to nedokáže správně přečíst/zapsat autor, pan Peter Breychak (nebo Breychuk?), jak přiznává, ale oni to nedokážou ani samotní uživatelé těch jazyků. Navíc to není nic nového pod sluncem, stačí si vzpomenout na nejednoznačnosti psaných podob jmen v našich zemích v dobách česko-německé bilinguality.
Jen pro úplnost, v českých textech nemá místo jiná psaná podoba, než dle ČSN o transliteraci a transkripci azbuky do české latinky, tj. Anatolij Tymoščuk. S tím našinec problém mít nebude a vysloví to přesně stejně, jako nositel toho jména.
A ještě pro zajímavost, českou transliteraci azbuky používají i anglofónní lingvisté, neboť pochopili, že ta anglická je nepoužitelná.
Souhlas, správný zápis není jednoduchý a jednoznačný (a je off topic). Navíc uvedený fotbalista je Ukrajinec a pak je dle Transliterace azbuky podle ČSN ISO 9 – http://www.osu.cz/ffi/ksl/index.php?kategorie=34479&id=4667 Timoščuk a nikoliv Tymoščuk. A v pasu má asi Tymoshchuk.
v pase má: Анатолій Олександрович Тимощук
to sice ano, ale např. v ruských pasech se uvádí se i přepis do latinky. Předpokládám, že to platí i pro jiná „obrázková“ písma
Dobrej název :)