
Návrh databáze – NoSQL vs SQL

SQL, nebo NoSQL? V tomto článku není cílem řešit, jestli mají pravdu zastánci relačních databází nebo zastánci NoSQL, ale podívat se konkrétně na to, jak by vypadal takový školní databázový návrh pro key-value databázi, a jak moc je odlišný od návrhu pro klasickou SQL databázi.
Seriál: Nerelační databáze (11 dílů)
- CouchDB – tak trochu jiná databáze (1. část) 24. 8. 2009
- CouchDB – tak trochu jiná databáze (2. část) 31. 8. 2009
- CouchDB – tak trochu jiná databáze (3. část) 7. 9. 2009
- MySQL v roli neschémové databáze 6. 1. 2010
- Základy Amazon SimpleDB 30. 3. 2010
- Návrh databáze – NoSQL vs SQL 31. 3. 2010
- Amazon SimpleDB prakticky v PHP 15. 4. 2010
- Vyskúšajme si Tokyo Cabinet 4. 5. 2010
- Redis: key-value databáze v paměti i na disku 7. 10. 2010
- Přechod z MySQL na CouchDB, část první 17. 2. 2011
- Přechod z MySQL na CouchDB: Druhý díl 24. 2. 2011
Minule se zde na Zdrojáku rozhořela debata pod tímto článkem. V diskuzi padlo dost argumentů proti SQL i pro SQL. V tomto článku se podíváme na to, jak by vypadal takový databázový návrh pro key-value databázi, a jak moc je odlišný od návrhu pro klasickou sql databázi. Také si shrneme výhody a nevýhody těchto řešení.
Zadání
Mějme takové klasické zadání, na kterém si studenti ve škole trénují návrh SQL databází. V zadání nebudeme zabíhat příliš do detailů a nebudeme ho rozebírat více než je třeba.
Zadání je následující: Chceme vytvořit systém, který bude vypisovat program kin. Program může být týdenní nebo měsíční. V programu je uveden název kina ve kterém se hraje a adresa kina. Dále program bude obsahovat seznam filmů, což znamená, že u každého filmu bude jméno filmu, krátký popis, režisér filmu a také rok vzniku filmu. Dále bude možno vyhledávat, které kino hraje konkrétní film.
Analýza
Pokud půjdeme na věc klasicky, jak nás to naučili ve školních škamnách, tak okamžitě rozpoznáme entity Kino a Film s tím, že entita Kino má atributy adresa a název. Entita Film pak rok, režisér, jméno filmu, popis. Tyto entity pak mají vztah m:n, protože Kino může hrát (třeba i nehrát, to zadání neříká) libovolný počet filmů, a stejně tak film může být hrán v libovolném počtu kin. E-R diagram pak bude vypadat následovně:
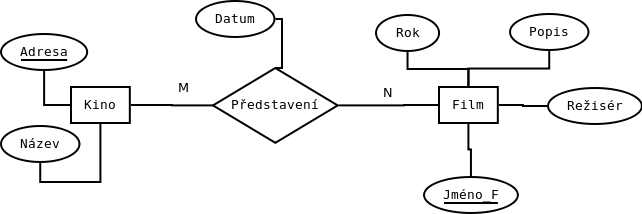
Z tohoto diagramu by v SQL vznikly 3 tabulky. Tabulka Kino pro záznam informací o kinech, tabulka Film pro záznam informací o filmech a tabulka Představení, která by říkala, který film se hraje ve kterém kině a kdy. Hotovo. Nyní napsat SQL dotazy a nějak ta data prezentovat a máme vystaráno. Víceméně si vystačíme s dvěma dotazy – první vypíše program a druhý vyhledá kino podle názvu filmu.
Nyní se podíváme co udělat s tím samým případem, když máme k dispozici pouze key-value databázi. Nevím o žádné speciální metodice, podle které bych to navrhl, takže se přidržím předchozího návrhu, a ten denormalizuji. Do databáze uložím data tak, jak by vypadal výsledek provedeného SQL dotazu z předchozího příkladu. Jedná se tedy o data, která přímo vidí uživatel. Při výběru a výpisu dat nebude prováděna jiná operace než jejich formátování do výsledné podoby (například HTML stránka apod).
Začneme tím, jak bude vypadat uložený program kin. V zadání jsou dvě možnosti jak vypsat program: týdenní a měsíční. Jestli se jedná o týdenní či měsíční bude rozlišovat klíč. Každý záznam bude obsahovat Kino a jeho atributy a pak program, tedy seznam filmů s časem, kdy se hrají. V JSON notaci by zjednodušený měsíční program kin mohl vypadat následovně:
| klíč | hodnota |
| 01/2010 | [{Kino:{Adresa:Václavák,Nazev:Kino Václavák}},{Program}] |
Obdobný případ je výpis týdenních programů kin. Jinak bude vypadat klíč (týdnů je více než měsíců), ale hodnota bude mít formát stejný.
Ještě nám zbývá dodělat výpis seznamu kin, které hrají konkrétní film. To bude trochu oříšek. Máme dvě možnosti, jak se k tomu postavit. Jedna z nich je, že to budeme vyhledávat přímo buď v týdenních nebo měsíčních záznamech, a druhá možnost je, že si toto dáme stranou, film bude fungovat jako klíč a pod tímto klíčem bude uložen seznam všech kin, které kdy ten film uvedly. To by mohlo vypadat následovně:
| klíč | hodnota |
| 7 statečných | [{Adresa:Václavák,Nazev:Kino Václavák,Datum:02/01/2010 15:00}] |
Úprava schématu
Tak by to vypadalo, pokud by se zadání neměnilo a schéma, které jsme dostali na začátku, by bylo stejné po celou dobu používání aplikace. Reálně to tak není a vždy dochází k nějaké úpravě schématu. Každá úprava bude vyžadovat menší či větší programátorský zásah do aplikace, a to jak u NoSQL, tak i u klasické relační databáze. U relačního schématu musíme také provést změny databáze, které mohou být netriviálního charakteru. U NoSQL to není nutnou podmínkou. Ukážeme si proč.
Začneme zlehka, řekněme, že se nám sešlo více filmů, které mají více než jednoho režiséra. Takže je potřeba rozšířit naše schéma o tabulku režisér, a tu přes klíč připojit k filmům. Což znamená poměrně radikální přestavbu databáze, která může i chvilku trvat v závislosti na počtu řádek v databázi. A to došlo pouze k relativně malé změně, že potřebujeme více režisérů. Z hlediska NoSQL je to jedno, tak se do databáze uloží více režisérů a aplikace se upraví, aby s tím počítala. Hotovo.
Tady jistě někdo namítne, že od toho se dělá analýza a to byla chyba při návrhu. Ano, u tohoto příkladu se dá diskutovat, že to byla chyba při návrhu. Jenže co má dělat takový SaaS poskytovatel? SaaS aplikace se vyznačují tím, že jedna instance aplikace obsluhuje více zákazníků. Často se stane, že zákazník chce nějakou malou změnu (z pohledu zákazníka, u poskytovatele to může vyvolat menší paniku). Poskytovatel nemůže jen tak měnit schéma, nehledě na to, že požadavky zákazníků si často protiřečí. Takže musí myslet na nějakou možnost přizpůsobení. Což se děje různým způsobem, buď přímo použitím NoSQL databáze nebo návrhem SQL schématu tak, aby se s touto možností vyrovnal. (Dobrý příklad je třeba open source wiki – XWiki)
Výhody a nevýhody
V případě key-value je vidět, že budeme čelit velké redundanci dat a udržování integrity dat bude úkol pro aplikaci. Jakákoliv oprava dat bude znamenat prohledat všechny záznamy, kde se daná data nacházejí. Což bude netriviální operace. Na druhou stranu bude výpis dat velmi rychlý, stejně tak zápis. Máme také možnost snadno přidat další atributy k filmům či kinům. Tyto atributy mohou být třeba jen dočasné. Tyto dočasné atributy bude muset umět obsloužit aplikace a vlastně bude i nositelem jejich popisu. V závislosti na zvolené databázi (Redis,TokyoCabinet, Project Voldemort apod.) dostaneme i dobře škálovatelné řešení.
V případě relačního modelu máme známé výhody: Data jsou snadno udržovatelná, dobře se udržuje i datová integrita. Data také budou zabírat méně místa na disku, protože nejsou redundantní. Změna výpisu může znamenat pouze změnu SQL dotazu, nebude třeba přegenerovat celou databázi. Máme také k dispozici více materiálu o tom, jak klasickou SQL databázi navrhovat a udržovat v chodu. Na druhou stranu, pokud se vyskytnou speciální atributy, bude to znamenat změnu schématu, což u více záznamů není operace na pár vteřin. Ukládání dat bude pomalejší (ACID, dokud nejsou data uložena ve všech tabulkách, nelze zapisovat další).
Oba modely je možné zkombinovat a dostat tak výhody obou. Tj data budeme mít uložena pěkně relačně, takže se nám bude dobře udržovat integrita dat, a pro výpis dat budeme používat key-value databázi. Což třeba dělá Facebook (data jsou uložena v relační databázi, ale většina je cachována pomocí memcached) nebo LinkedIn, které stojí za Project Voldemort.
NoSQL nejen na straně serveru
Mohlo by se zdát, že podobné principy jsou záležitostí pouze pro server, jenže blízká budoucnost vás vyvede z omylu. Lokální úložiště, jak je definuje HTML 5, jsou přesně typem NoSQL. A vzhledem k jejich možnostem a směřování vývoje k poměrně rozsáhlým webovým aplikacím je jisté, že velká část dat se bude u klienta uchovávat. Byť třeba jen proto, že mu zrovna vypadlo připojení k internetu. Proto je dobré se již teď zabývat tím, jak data ukládat a jak v nich lehce vyhledávat.
Jan Kodera
Jan Kodera je technickým ředitelem ve startupu Abakowiki. Patří mezi největší propagátory moderních IT, jako je SaaS či cloud computing.



libovolny atribut pripojim ke schematu pomoci proste prijoinovane atributove tabulky (klasika foreign key – attrname – attrvalue – alternativne attrtype) a problem solved. Na tomdle stoji kazdy druhy inventory system.
K tomu predzvykane selecty v materialized views a nevidim nejak nic, co by me melo na NoSQL uchvatit. A kdyz pripoctu vlastnosti treba Oraclu v generovani XML primo selectem, prohledavani stromu (connect by) a dostavame se uz uplne jinam…
Hlavním smyslem NoSQL není poskytnout jinou funkcionalitu oproti standardním databázím. Naopak – NoSQL toho umějí méně, nejsou ACID compliant, ale právě díky tomu mohou dosahovat výrazně lepších hodnot v oblastech výkonu, škálovatelnosti a dostupnosti.
Zajímavým fakt však je, že většina NoSQL databází není škálovatelná. Nebo alespoň né lépe jak MySQL. Doporučuju přečíst: http://jamesgolick.com/2010/3/29/most-nosql-dbs-are-not-scalable.html
No teda, to je ale pomatené. Jednak je třeba dovysvětlit co je to „škálování“ v dalším článku, uf. Druhak, typicky zmíněný CouchDB je díky robustní replikaci velmi dobře <del>vertikálně</del> horizontálně škálovatelný. On je dokonce _navržený_ tak, aby právě takto škálovatelný byl. Clusterování CouchDB je triviální jakbysmet: http://ephemera.karmi.cz/post/247255194/simple-couchdb-multi-master-clustering-via-nginx
Nějak by to chtělo „even more substantiation“ :)
Prosím redakci opravit „vertikálně škálovatelný“ na „horizontálně škálovatelný“, samozřejmě. Vertikálně se dá škálovat i kalkulačka.
Horizontálně lze škálovat i takový Redis: http://code.google.com/p/redis/wiki/TwitterAlikeExample#Making_it_horizontally_scalable.
Šlo by napsat pro laiky napsat co to je horizontálním a vertikální škálování?
Ve zkratce, vertikální škálování děláte přesně ve chvíli, kdy do serveru koupíte lepší procesor, paměť nebo disk.
Naopak horizontální škálování provádíte ve chvíli, kdy aplikaci rozběhnete na dalším serveru či serverech.
Rozdíl v přístupu je zásadní. Vertikální škálování se nedá dělat donekonečna a s postupem času jeho efektivita upadá. Na druhou stranu horizontální škálování je mnohem efektivnější a teoreticky se dá dělat donekonečna (nutno brát s rezervou). Problém je, že zatímco vertikální škálování aplikace podporuje vždy, horizontální škálování má své specifické problémy, na které se musí myslet při návrhu.
A co takovej berkeleyDB :P ktery vnitrne pouziva[l] i mysql
Autor Tokyo-cabinet a Tokyo-Tyrant na svojom blogu zverejnil podklad pre clanok „Prednaska o ulozisti typu kluc-hodnota pre Vas, ktorych to naozaj zaujima“, kde vysvetluje ako pouzivaju TC a TT v mixi.co.jp (japonska socialna siet). Hlavnou vyhodou je neporovnatelne rychlejsie vyhladavanie oproti klasickym databazovym serverom a znizenie nakladov na hardware. TT rozumie memcached protokolu a preto je prechod z memcached na TT jednoduchy. TT/TC pouzivaju na ukladanie informacii o sedeniach, pri fulltextovom vyhladavani a mapovani vztahov medzi uzivatelmi. 1 server s TT sa dokaze vysporiadat s viac ako 150 00 000 000 navstevami za mesiac.
http://1978th.net/tech/promenade.cgi?id=72
Mozem prelozit ak to niekoho velmi zaujima.
Tak, zajímalo, i na Zdrojáku bych takový překlad rád viděl, ale nejsem s to z těch znaků poznat, zda to licence umožňuje :)
Napisem mu e-mail a spytam sa ho, ci to nebude problem.
Díky, to by bylo perfektní.
Pozdravujem,
mam potvrdenie, ze to mozem prelozit. Kontaktoval som ta cez ICQ, snad ho pouzivas. Ak nie, mozeme detaily dohodnut cez e-mail?
Pekny den.
Úplne najhoršie je, keď niekto (hlavne menej skúsený) urobí návrh s tým, že „počul som o nosql, skúsim to.“ Z toho vznikne taký bordel, že by ste neverili vlastnému monitoru ani očiam. To už vážne radšej ukladať plain text na disk.
Zdravím,
podotýkám, že se nepokouším o FLAME.
Je více než jasné, že při vývoji software a to hlavně databázových aplikací je někdy nutno volit mezi rychlostí, stabilitou, bezpečností.
Software by tu měl být od toho aby řešil nějaký problém, a právě na základě zadání se provádí volba platformy. Problém je ten, že mnoho mnohdy webových „programátorů“ prostě nezná jiné databáze než je například MySQL a to ještě ne tak dobře jak by měli, takže špatný výkon aplikace není na straně volby RELAČNÍ databáze ale z valné většiny mizerně vytvořeným datovým modelem a následně mizerné dotazy pomocí kterých dolují data.
Pokud budu páchat skladovou evidenci pro malý podnik – přesun materiálu mezi sklady, manipulace se zbožím, přesuny peněz apod, nevyhnu se nutnosti použití transakcí (a hlavně předchozí pečlivé analýze) a databázové platformy která toto umožňuje, s MS SQL praktické zkušenosti nemám tak sáhnu po PosgreSQL nebo Oracle.
Pakliže se bude jednat o tupý redakční systém kde mě tak nepálí (nadsázka) zda se uloží nebo neuloží data, protože uživatel snadno svůj komentář nebo článek napíše znova, když se něco nezdaří. Tudíž nebráním se použít NoSQL databázi, nicméně budu programovat s pocitem, že to dělám jako Pankáč jen abych se něčím lišil (prosím nenapadám autora článku).
Například by mě zajímalo kolik z vývojářů zkoumá prováděcí plány?
Kolik z vývojářů vůbec ví co jsou prováděcí plány?
Znám spoustu „programátorů“ a i přes fakt že si vydělávají slušné peníze nemají z oblasti databází téměř žádné znalosti ačkoli s nimi pracují…
Relační databáze jsou tu spoustu let, jsou v krvi, jsou osvědčené a hlavně v jejich strukturách je obrovské množství dat (OLAP, apod.).
Já osobně vidím NoSQL databázi jen jako krásné spestření volného odpoledne když je moje žena v práci a psovi se nechce jít ven. Jiný význam v tom opravdu nevidím.
Úhel pohledu se asi změní s velikostí projektu. Představte si, že píšete třebas twitter, FB nebo google. To jsou oblasti, kam se škálovat SQL databáze asi nedá (a třebas ACID nikoho moc nepálí). A naopak třebas pidiprojekty, kde je dat pomalu jen na jednu A4 textu možná ocení spíše nějakou podobu perzistentích prvotřídních objektů… NoSQL není univerzální spása, ale obdobně není univerzální řešení ani SQL.
Bral bych SQL jako střední cestu, prošlapanou a známou. Ale na některá místa se dá zamířit jen trnitými, neprobádanými stezkami.
Nechtěl jsem, aby z mého příspěvku nějakým způsobem vyzařovalo to že 100% stojím za Relační databází. Ale je to obdobně jako s demokracií. Uznávám ji proto že zatím o něčem lepším nevím a nemám schopnosti na to abych to vymyslel.
Je samozřejmě možné jak psal autor článku nějakým způsobem obě cesty kombinovat. Myslím že to o tom už bylo psáno MySQL v roli neschémové databáze.
Dle mého názoru může být takovýto počin šikovný, ale jsou tu ale.
Určitě musí mít projekt pořádnou dokumentaci, přijde nový člověk do projektu a může ho z neschémové databáze trefit šlak (pouze domněnka pakliže není vedena pořádná dokumentace ).
V případě relační databáze je orientace v projektu daleko snazší. Osobně jsem nastupoval do rozjetého vlaku (60 tabulek 220 pohledů v aplikaci) a neměl jsem s orientací v projektu žádný problém. Do styku s velkými aplikacemi jsem opravdu nepřišel, tabulky které byli v rámci projektu na testovací databázi obsahovali do deseti milionů záznamů byli i výjimky jako nějaké archívní tabulky tam mohl být počet záznamů daleko vyšší. Jednalo se o projekty O2, provozní databázi jsem nikdy neviděl. Nicméně na rychlost si nikdy nikdo nestěžoval.
Já bych to řekl tak, že pokud použiju nějakou technologii musím vědět proč tuhle a ne jinou. NoSQL je dnes hodně moderní, a proto bude používaná i tam kde se úplně nehodí viz. http://en.wikipedia.org/wiki/Hype_cycle
Nemusite menit uhel pohledu na zaklade velikosti projektu. To co vetsinou je nutne menit je zpusob jak SQL DB pouzivate.
Napriklad web aplikace kde kazda stranka je 10 SELECTu do DB a 99% dotazu vraci opakovane to same je blbe napsana… pak dava vetsi smysl pouzivat SQL DB jako uloziste konzistetnich dat a nad tim mit nejakou vrstvu udrzujici data v nejake predpripravene podobe (fragmenty stranek apod.)
Jinak nemyslim, ze vetsina programatoru resi veci jako je napsani FB nebo Google… a vetsina si ani nedokaze predstavit co u takoveho objemu dat je nutne resit.
Nesouhlasím. Kešovat má smysl data, jejichž získání zdržuje. Pokud se dotazy vyhodnocují tak rychle, že to uživatel ani nepostřehne, tak 10 dotazů nevadí, i když pořád vrací ta stejná data.
Ono se nakonec nějaké to kešování ke slovu stejně dostane (ať už na úrovni databáze nebo třeba disku), jen se tím nemusí komplikovat aplikace.
V praxi to potom může dopadnout tak, že získání dat z primárního úložiště (zde databáze) je zhruba stejně rychlé jako z keše. V takovém případě představuje keš naopak zbytečnou režii a komplikaci.
Oh… tise jsem predpokladal, ze se lide se pousti do optimalizaci pokud vedi ze maji problem :-)
Nikoliv, drtivá většina lidí se na základě článků jako je tento pouští do „preventivních optimalizací“. To je ten paradox, že pro znalého člověka je ten článek jen zbytečným opakováním a pro neznalého člověka je to lístek do pekla.
Jenze kdyz jsou v cache v databazi zbytecna data, nevejdou se tam nakecovat potrebna data.
…Pokud budu páchat skladovou evidenci pro malý podnik – přesun materiálu mezi sklady, manipulace se zbožím, přesuny peněz apod, nevyhnu se nutnosti použití transakcí …
tento blud je dnes a denne vyvracen existenci statisicu takovych systemu, ktere transakce nepouzivaji a presto funguji, aniz by uzivatele pozorovali nejake problemy. To, co se vypravi v knizkach nemusi byt vzdycka pravda. V knihach stalo take 1000 let, ze zeme je placata.
Dost možná ano.
Ale co když bez věcí jako je explicitní zamykání záznamů(pokud je to nutné), uložených procedur(ulehčují mi život) a transakcí(jsou li nutné) to prostě nějak neumím.
Abych dokázal s technologií dělat musím jí věřit. A zatím se nenašlo nic co by mou víru v tok jak věci dělat nabouralo.
Navíc znám lidi co znám z praxe, věkový profil od 25 do 50 by zřejmě volili stejnou cestu jako já.
A je tu ještě jedna věc. Možnost zavedení nějaké novinky je spojená s testováním, s nutností 100% podpory pro danou platformu (musím mít koho za to pokárat když to nejede).
Ze života když nepůjde na hodinu facebook, co se stane… lidi půjdou na lide.cz nebo jinam.
Když nepůjde hodinu výrobní hala, nebo SW na řízení letového provozu, je to velký malér.
Jak už jsem psal v jiném příspěvku, neříkám že je to nejlepší způsob, ale jen nevím o lepší a jinému nevěřím.
ok, samozrejme jako konkretni osoba mate pravdu, ze je rozumne delat to co ma clovek osahane.
Ja chtel jen obecne upozornit na ty transakce. V tom je ten zakopany pes, prinos no-sql je zejmena v tom, ze se vubec prolomilo to tabu, ze nekdy ‚treba‘ nejsou transakce tak dulezite. Soucasny stav je takovy, ze i Vy akceptujete, ze pro facebook to neni zivotne dulezite. Ale pro skladovy system to pro Vas jeste zivotne dulezite je. Ja jen rikam, i u skladoveho systemu to jde bez transakci. Lepe receno, podivejme se dukladne, kde je to skutecne nezbytne.
Skladovy system bez transakci?
To jako vyskladnim polozku ve skladu A, spadne konexe do RDBMS, naskladneni do skladu B se uz neprovede a co pak?
To jako polozka zmizi ze sveta?
Zrovna vcera jsem stravil manday (tedy ztrata 25000Kc pro firmu) reinstalaci SW, kteremu se rozpadl DB backend prave proto, ze se NECO v transakci hlidane aplikacni logikou zapsalo a NECO vytimeoutovalo.
U Pakistancu takove praseciny chapu, ze i v Cesku se najdou podobni matlalove, to je veru smutne…
Pripomina mi to, kdyz jsem u jednoho Ugandskeho operatora nasel v CRM 10000 ve vzduchu visicich SIMek prave z duvodu rozpadlych transakci.
V Africe to chapu.
Do evropy tenhle pristup nepatri.
Hmm, bohuzel stejne bezne je to, ze se nejaky request/dulezita data jdouci do IS ztrati uplne (zmizi ze sveta) prave diky tomu, ze se nepodarila dokoncit cela transakce (napr. spadne na nejake ptakovine, ktera kdyby nebyla v transakci, tak opravdu dulezita data v DB budou). Ale to museli asi delat nejaci matlalove z Afriky, ne kabrnaci jako vy.
Abych se priznal, nerozumim.
Ucelem transakci jest prave, aby se dana datova operace provedla bud korektne cela anebo vubec a pak navratila hezky vse do puvodniho stavu rollbackem.
Tedy aby se ze slozitych procesu stala zapouzdrena „atomicka“ operace.
Pkud transakce „pada na ptakovine“ no tak zkratka dana „ptakovina“ vubec nema byt soucasti transakce.
A pokud neprovedeni „ptakoviny“ nicemu nevadi, pak zas netusim, proc ji vubec delat.
resseni jednoduche:
begin transaction
business logic
savepoint
ptakovina when exception rollback to savepoint
pokracovani business logic
commit
Ale je to prasecina, ktera pri slusnem navrhu vubec nemuze nastat
Vidim, ze uroven IT lidi v Cesku drsne upada…
Kdyz vidim nektere navrhy „architektu“, kteri se ani nenamahaji testovat zda WebService Call vubec dobehl…
Souhlasim, ze takle nejak by to v idealnim programu mohlo vypadat. Tzn. spolehame, ze nikde v programu neni chyba a transakce nam nevybouchne po necekane exceptione, vsechny ptakoviny (napr. zapis do logovaci tabulky) jsou na konci v „nested“ transaction nebo v nezavisle transakci; programy, ktere nas volaji, si kontroluji nas navratovy kod; mame dvou fazove commity, abychom meli atomicitu pres vice nezavislych aplikaci a distribuovanych uzlu, atd.
Vyvojari modernich DB se snazi prijit s robustnejsim a jednodussim resenim, ktere nevyzaduje idealni svet bez chyb v aplikacich a navrzich, reseni ktere dobre skaluje a umoznuje jednoduse refactorovat. A to je v podstate vse.
To co popisuju neni zadny idealni stav ale minimum pro vytvoreni spolehliveho systemu.
Vubec neni potreba „spolehat ze nikde v programu neni chyba“, kdyz je tam chyba, excepsnu pozere toplevel catch blok, ktery zajisti rollback, vraceni error code nebo rethrow vyjimky. Na databazove urovni to je je otazka cca peti radku kodu.
Zadny nedostizny ideal ale naprosty primitivni zaklad, kdy (kdyz zjednodusim) staci obalit volani metody runMe() to try-chatch bloku.
Ze si volajici program hlida returncode je snad minimalni zaklad, to ma snad aplikace poslat WS call a doufat v prizen bohu? V „modernejsich“ jazyzich od C++ ci PLSQL vyse je dokonce pri chybe vyhozena vyjimka, kterou musi prasecky programator explicitne potlacit, kdyz uz se nehodla zabyvat, zda pozadovana operace vubec probehla.
Vzdyt to co tu popisujes je naprosty maglajz.
Pustim neco a doufam ze to projde.
A kdyz neco neprojde, tak doufam ze slo o „ptakovinu“.
A kdyz to neco nebyla ptakovina, snad si toho v tom svinciku nikdo nevsimne.
Ponekud byzantinsky pristup.
Ono totiz v IT branzi probramy provadeji dane ukoly klidne milionkrat za den.
A staci promile chybovosti a jde to do hlubokych sracek.
Debugovat se to neda, debug projde bez problemu, akceptacni testovani taky.
Pak zacnou litat prakticky neresitelne tikety typu na jedne vygenerovane fakture z milionu se zakaznikovi nepripocitala akcni sleva. A naklady na servis zabijou celou marzi z projektu a nakonec te zakaznik pozene bicem.
To neni zadna vymyslena sofistika ale realita testovana na lidech.
Navrhnout system, ktery zkratka nedovoli, aby data zmizely v nenavratnu, je ukolem SW architekta. A ten dostava slusny plat prave za to.
„Vyvojari modernich DB se snazi prijit s robustnejsim a jednodussim resenim, ktere nevyzaduje idealni svet bez chyb v aplikacich a navrzich“
Ano, prave proto prisli s transakcema.
V Oraclu je transakce libovolny DML prikaz ci sada prikazu az do nasledujiciho commitu ci rollbacku. V Oraclu dokonce ani nejde nepouzit transakci, jenom jest potreba dopsat tech 5 radku kodu, aby Oracle vedel, co s exepsnou delat…
> Vubec neni potreba „spolehat ze nikde v programu neni chyba“, kdyz je tam
> chyba, excepsnu pozere toplevel catch blok, ktery zajisti rollback, vraceni
> error code nebo rethrow vyjimky. Na databazove urovni to je je otazka cca peti radku kodu.
A mame to tady – nekonzistentni data, protoze neresis atomicitu na urovni nekolika nezavislych aplikaci. Nebo ano? Nikde tu o tom nevidim zminku.
> Ze si volajici program hlida returncode je snad minimalni zaklad, to ma snad
> aplikace poslat WS call a doufat v prizen bohu? V „modernejsich“ jazyzich od
> C++ ci PLSQL vyse je dokonce pri chybe vyhozena vyjimka, kterou musi
> prasecky programator explicitne potlacit, kdyz uz se nehodla zabyvat, zda
> pozadovana operace vubec probehla.
Jestli je ovsem vubec sance takovy WS call udelat uvnitr transakce, coz ve spouste enterprise aplikaci, ktere navrhoval tzv. „SW architect“ s obrovskym platem nejde.
> Vzdyt to co tu popisujes je naprosty maglajz.
> Pustim neco a doufam ze to projde.
> A kdyz neco neprojde, tak doufam ze slo o „ptakovinu“.
> A kdyz to neco nebyla ptakovina, snad si toho v tom svinciku nikdo nevsimne.
> Ponekud byzantinsky pristup.
Skutecne? A ja si az do ted myslel, ze kdyz clovek pocita s chybami, tak se to jmenuje „robustnost“. Diky za upozorneni, ze „robustnost“ je odted svincik. Doporucuju ti sledovat stranky napr. CouchDB, pak zjistis, jak se resi robustnost, paralelismus, atd. Jejich programatori jsou o par levelu nad tvou teoretickou nebo moji praktickou urovni (ne nadarmo vedouciho vyvojare koupilo IBM, nedavno jim dal vypoved a zalozil si vlastni firmu).
> Navrhnout system, ktery zkratka nedovoli, aby data zmizely v nenavratnu, je
> ukolem SW architekta. A ten dostava slusny plat prave za to.
Takze teoretik (idealista), ktery navrhuje systemy typu „padajici hovno“? To hovno nakonec pres programatory dopadne z velke vysky az na uzivatele a z toho pak dostavame prave ty neresitelne tikety a vytocene zakazniky. Ono neni s podivem, jak te tak posloucham, ze ve svete maji architekti tak hrozne spatnou povest. K nam to zrejme jeste nedoslo, protoze architekti jsou vetsinou v zahranicni firme a tady jsou pouze koderi…ale dojde, dojde…jsme o spustu let pozadu.
Docela mně irituje „spolehame, ze nikde v programu neni chyba a transakce nam nevybouchne po necekane exceptione“ – vždyť přesně tomuhle transakce předchází!
Pokud nemáte transakce, tak se právě spoléháte na to, že se nic nestane. Ve chvíli, kdy se na to spolehnout nemůžu, použiji transakci – pak mám jistotu, že to buď proběhne (a pak jsem spokojený), nebo se naopak vůbec nic nestane (a pak nemusím analyzovat co se mi kam zapsalo blbě a opravovat data).
Jiný problém je, že řada lidí (školy je v tom podporují) transakcím nerozumí a má neodbytnou potřebu všechno dávat do jedné jediné transakce, s utkvělou představou, že zabalením do transakce se zvýší spolehlivost aplikace. Nikoliv, transakce spolehlivost systému snižují – a naopak zvyšují bezpečnost. Je to to samé jako pojistky ve vašem domě – přestože kolikrát vypadnou zbytečně (nízká spolehlivost), hřebík do nich nezatlučete. To proto, že je nemáte kvůli spolehlivosti (nepřetržitá dodávka), ale kvůli bezpečnosti (zamezení požáru, úraz u probíjejícího spotřebiče atd.)
A stejná paralela je i u DB a aplikací – u FB je pro mně prioritou spolehlivost (uptime), u skladového SW bezpečnost (účetní a věcná správnost). Je to prostě o tom, co chcete, aby se v tom „neideálním světe s chybami“ stalo. Coby správce ERP systému chci, aby se to v případě chyby celé zastavilo a neprasilo data.
[…] Coby správce ERP systému chci, aby se to v případě chyby celé zastavilo a neprasilo data. […]
jako vedouci vyroby v takove firme, ve ktere byste Vy byl ERP spravce bych delat nechtel, ja bych totiz nemohl cekat, az vy rano prijdete a zanalyzujete ty problemy …
Jeste jednou, opisovanim ‚teoretickych pravd‘ ze skolnich ucebnic se daleko nedojde. Ten opravdovy svet se nachazi mimo skolni lavice a musi existovat i pote, co se nejaky debilne navrzeny system rohodl pro rollback.
[…] To jako vyskladnim polozku ve skladu A, spadne konexe do RDBMS, naskladneni do skladu B se uz neprovede a co pak?
To jako polozka zmizi ze sveta? […]
to je prave ten problem, ze misto toho, aby se napsal do jedine tabulky zaznam o pohybu, tak se na dvou mistech dela update.
manday za 25000 Kč, wow, tak tam bych chtěl taky dělat
> Jak už jsem psal v jiném příspěvku, neříkám že je to nejlepší způsob, ale jen nevím o lepší a jinému nevěřím.
To mi pripomina jednoho minuleho kolegu: „Nic o tom nevim, …, ale vim zcela urcite, ze to musi byt takhle“.
Jinak pro lepsi predstavu o cem jsou NoSQL vam doporucuji si precist prispevek nize: „key-value no-sql databaze maji radu vyhod“.
NoSQL DB jsou kupodivu o tom, ze nepouzivaji SQL (samozrejme mohou byt relacni, obsahovat ACID atd.).
Je mi jasne, ze je to pro vas rana – roky jste se srotil SQL, nic jineho neumite a ted vam na nej nekdo saha ;).
Pro jeste lepsi predstavu, jak se moderne programuje si zkuste nejake ORM frameworky, jakou jsou ActiveRecord (Ruby), pripadne neco podobneho pro Javu/C#.
Možná je to pro vás rána, ale i za těmi skvělými ORM frameworky se dnes obvykle schovává staré dobré SQL, ORM je jen vrstva navíc, aby se aplikační programátor nemusel namáhat s přemýšlením nad tím, jak to v té databázi vlastně funguje. Naneštěstí to vede nezřídka k tomu, že se pak DB používá výrazně méně efektivně než by to šlo tradičním způsobem. Je to bohužel další z projevů současného trendu, kdy vývojáři přestávají přemýšlet nad efektivitou svých výtvorů, protože spoléhají na to, že to za ně udělá nějaký úža framework…
Rana to pro me neni, protoze jsem si minimalne ctyri podobne mini ORM frameworky napsal sam na miru dane aplikace. Ono je to celkem snadne (psal jsem si je sam proto, aby byl vysledek co nejefektivnejsi). Samozrejme, ze me stve SQL, ktere vetsinou bude pod ORM frameworkem schovane. A pisu _muze_, protoze v pripade pekne noSQL databaze clovek muze prejit na nejaky opravdu efektivni zpusob komunikace s DB, kterym SQL opravdu neni.
Nechci vas skolit o tom, jak se resi performance, tak si to prosim zjistete sam. Kazdopadne od kazdeho programatora, ktery programuje alespon 20 let zjistite:
===
More computing sins are committed in the name of efficiency (without neces-
sarily achieving it) than for any other single reason—including blind stupidity.
—William A. Wulf [Wulf72]
We should forget about small efficiencies, say about 97% of the time: prema-
ture optimization is the root of all evil.
—Donald E. Knuth [Knuth74]
We follow two rules in the matter of optimization:
Rule 1. Don’t do it.
Rule 2 (for experts only). Don’t do it yet—that is, not until you have a
perfectly clear and unoptimized solution.
—M. A. Jackson [Jackson75]
===
Dale se prosim zamyslete nad tim, jakym zpusobem se zacaly nasazovat SQL databaze. Bylo tu spousta DB radoby specialistu, kteri tvridli, jak je to SQL k nicemu, neefektivni, pomale a chybove. A vite co, kdyby prukopnici na takovehle lidi dali, tak jeste dnes programujeme v _uzasne_ efektnim asembleru.
Hm, no nevím, ale psát pro každou aplikaci extra ORM framework, aby to bylo efektivní, mi přijde jako typická ukázka těch programátorských hříchů pácháných ve jménu efektivity, o kterých hovoří ty vaše citáty.
Co se týká ORM a noSQL DB jako takových, v zásadě proti nim nic nemám. Jen nechápu, proč plivete na SQL, když jeho základní smysl je prakticky stejný jako v případě ORM – za cenu určité ztráty efektivity poskytuje pohodlnější a transparentnější rozhraní k DB.
>To mi pripomina jednoho minuleho kolegu: „Nic o tom nevim, …, ale vim zcela urcite, ze to musi byt takhle“.
Lepším je míněno to čemu také uvěří zákazní, lepší je to s čím se mi dobře pracuje. Velké firmy většinou slyší zase na jiné velké firmy proto frčí Oracle pro ty co na to mají (pominuli express edition) a další velcí dodavatelé.
>Je mi jasne, ze je to pro vas rana – roky jste se srotil SQL, nic jineho neumite a ted vam na nej nekdo saha ;).
Na to se dá říct snad jen toto: Studium SQL určitě není na roky. Rána to rozhodně není. Rána to byla když mi spadl na auto led se střechy ve městě. A do toho, kdo mi na něj zrovna saha vam fakt nic neni.
A co se týče ORM nejsou pro mě neznámoou záležitostí, ale černé skříňky používám opravdu s velkým odporem.
A mám pocit že stále by se mělo programovat hlavně dobře. Bez ohledu na to co je zrovna moderní. To znamená abych se mohl bez obav postavit za svou práci a chtít za ní patřičnou odměnu.
(Děkuji za zajímavé příspěvky do diskuse Vám i vašim oponentům, ale poprosím vás všechny: Zůstaňte u výměny názorů, klidně i ostré, ale zdržte se, prosím, osobních komentářů, hodnocení znalostí nebo zkušeností ostatních diskutujících – tedy výroků na téma „kdo co neumí“, „kdo co nechápe“ nebo „kdo komu na co sahá“! Určitě se shodneme na tom, že podobné vsuvky do jinak věcných komentářů zbytečně stáčí diskusi od tématu k planému dohadování o tom, kdo – a teď promiňte – ho má většího. Děkuji všem za pochopení.)
Plne s Vami souhlasim a duvod proc jsem se svym extremismem vubec zacal byl ten, ze uz mam po krk netolerance (NoSQL je pro Pankace), extremistu a alfa-samcu (mam plat 2× vetsi nez ostatni a nikdy nedelam chyby, ostatni jsou matlalove).
Dotyčným se timto omlouvam.
Tento „blud“ se mi potvrzuje minimalne 5× do roka. Takovahle aplikace funguje mesice ale treba i roky bez problemu, pak spadne a uz nenabehle. Behem spousteni se ta vec zhrouti s nejakou silenou chybou/vyjimkou, ktera vice-mene rika jen to, ze data v DB jsou nekonzistentni a ze se takhle neda pokracovat. Vetsinou je to napsany v Jave, zadny poradny logy z toho napadaji a nikdo od toho nema ani zdrojaky.
Víceméně souhlas. Ale ta Java s tím souvisí jak? Nebo to bylo jen kopnutí? Přijde mi totiž, že disciplinovanost je u javistů trochu vyšší než jinde (i když bastlíři se samozřejmě najdou všude). Java jako taková je na tom, co se týče transakcí dobře – nejde jen o primitivní commit/rollback nad jednou databází, ale i distribuované transakce – viz JPA, XA, 2PC.
Proti Jave jako jazyku nic nemam. Java je pro me ale synonymum pro projekty typu „rychle“, „levne“ a hlavne „rychle pryc od toho“. Systemy napsane v COBOLU nebo Ccku uz prosly selektivnim vyberem a prezily pouze ty dobre a udrzovatelne. Tahle faze Javu jeste ceka. Na „enterprise“ systemu v Jave muze pracovat kdejakej amater a ono bude i fungovat, ale dat ladici vypisy na spravna mista v kodu, tak na to potrebujete programtora se zkusenostmi – a ty zatim indum a cinanum chybi.
PS: to ze JDBC podporuje XA to vim – ono to funguje ale uz jsem i tak stravil par dnu resenim problemu s kompatibilitou driveru. High-level veci jako distribuovane transakce jsem moc casto nevidel. Mnohem casteji se setkavam s tim ze hibernate spousti x-krat za sekundu ten samy dotaz porad dokola a nikdo nevi proc ani nedokaze urcit ktery modul aplikace je za to zodpovedny.
Nesouhlasím. Transakce mají svůj význam, a že je většina systémů nepotřebuje (nebo na ně kašle), není ještě důkazem, že jsou zbytečné. Podstatné je vědět, k čemu jsou a kdy je žádoucí je použít nebo naopak kdy je jejich použití zbytečné.
A upřímně řečeno, aplikace, která řeší přesuny peněz a ve které může nad stejnými daty pracovat více lidí (nebo obecně nějakých procesů), je snad nejtypičtějším příkladem, kdy mají transakce zjevný smysl.
Ne, není to blud, je to nutnost, v případě skladové evidence dokonce zákonem daná.
Nebo si opravdu troufnete s finančním úřadem diskutovat o principech podvojného účetnictví? Chápu, že není problém, pokud se někde ztratí tweet. Ale když se někde ztratí faktura?
Za blud je to možné považovat až ve chvíli, kdy někdo začne tvrdit, že transakční logiku musí zajistit DB vrstva. To už samozřejmě není pravda a existuje řada velkých relačních DB, které neumí transakce.
a jsme u diskuze co ma skladova evidence spolecneho s podvojnym ucetnictvim.
Zdá se mi, že problémem NoSql je to, že neexistují žádné metodiky pro návrch „schématu“ NoSql databáze.
Nebo je jedinou metodikou to, že „schéma“ má odpovídat nejčastějším dotazům? Tak mi to z článku přijde…
Do jisté míry to tak je… Schéma není, nejsou poučky o relacích a denormalizaci, prostě jsou jen nějaké „sklady“ a v nich „krabice“, a do nich si házíte předměty – a je na každém skladníkovi, aby si našel ten správný způsob, jak ZROVNA ON najde nejrychleji to co potřebuje. Čili další technologie, co dnes vyžaduje spíš cit a představivost.
Myslím, že kombinácia NoSQL a SQL môže byť často ideálna. V posledných rokoch som robil nad väčšími IS kde počet tabuliek v databázy bol niekoľko sto záznamov. V niektorých prípadoch jeden komplikovaný objekt obsadil aj 20–30 databázových tabuliek len aby bolo možné popísať všetky jeho atribúty. Z pohľadu NoSQL by bolo ďaleko jednoduchšie uložiť tento objekt ako jeden JSON dokument.
.
To sme mohli zamozrejme urobiť aj teraz – uložiť daný objekt ako XML (alebo JSON) do jednej tabuľky ako BLOB objekt. Tým by sa počet tabuliek podstatne zmenšil.
Jj, kombinace relačního a „dokumentového“ se mi taky zamlouvá.
Právě ten xml sloupec (sémanticky to samé jako Json) mi přijde jako dobrý prostředek k dosažení „gumovosti“. Např. MS SQL umí i indexy nad obsahem xml sloupců…
Nejen MS SQL – XML sloupce jsou dnes celkem normální PostgreSQL Oracle, DB/2… často je možné generovat XML i z klasických tabulek (viz ten odkaz na pgsql).
Jj, mluvil jsem jen o MS SQL, protože jen u MS SQL vím, že je možné dělat indexy nad obsahem Xml sloupečku. Tím jsem nechtěl popřít, že by to ostatní databáze neuměly, jen s tím nemám zkušenost ;-)
Co si myslíte o tomhle řešení? IMHO je Xml sloupeček (navíc indexovaný) přesně to, co NoSQL řeší.
Ohledně škálovatelnosti – horizontální škálování umí každá slušná relační databáze, takže to za výhodu NoSql řešení nepovažuji.
Jedinou (avšak ne nedůležitou) výhodu NoSql vidím v tom, že se vesměs jedná o velmi „lehká“ (takže rychlá) řešení, protože se moc neřeší ACID apod.
Jsou mé úvahy správné nebo mi něco podstatného uniká?
„Co si myslíte o tomhle řešení? IMHO je Xml sloupeček (navíc indexovaný) přesně to, co NoSQL řeší.“
Pokud bychom to hnali do extrému, tak je to porušení 1NF a je to tedy špatné – ale stejně tak špatné by mohlo být i to, že když chceme změnit jeden odstavec v textu článku a musíme přeplácnout hodnotu sloupce jako celku (tzn. celý text článku i když měníme jen odstavec). Vytvoříme si proto tabulku „odstavec“ a napojíme ji na tabulku článků přes cizí klíče? Asi ne :-)
Proti XML sloupcům v relační DB nic nemám (pokud je k nim nějaký „dobrý důvod“*). Člověk tím získá mnohem větší flexibilitu – dají se najednou do DB ukládat velmi složité struktury, aniž by člověk měl model obsahující desítky nebo stovky tabulek. Ale zároveň v tom není takový nepořádek jako u bezschémových databází – vždycky se dá dokument zvalidovat. Navíc čím dál víc XML technologií se přesouvá** na úroveň databáze, takže je člověk nemusí řešit až v aplikace – např. takhle jde použít XPath v SQL
SELECT xpath('/my:a/text()', '
test ',
ARRAY[ARRAY['my', 'http://example.com']]);
něco ke čtení:
http://www.postgresql.org/docs/8.4/static/functions-xml.html
http://wiki.postgresql.org/wiki/XML_Support
„že se vesměs jedná o velmi „lehká“ (takže rychlá) řešení“
S tou rychlostí je to sporné – jde totiž o to, abychom tu chybějící funkcionalitu (třeba transakce, referenční integritu, dotazování atd.) nemuseli suplovat v kódu naší aplikace. Pokud se tak stane, bude to většinou hodně špatné (a pomalé), jelikož za vývojem RDBMS jsou roky nebo desítky let práce profíků – kdežto naši aplikaci psalo třeba půl roku pár „průměrných“ aplikačních programátorů – nechci nikoho podceňovat, ale u běžných projektů se musí stíhat termíny a vejít se do ceny a není moc prostoru na vymýšlení nějakých extra kvalitních řešení a nových věcí***. Podobné je to i s aplikačními servery atd.
*) dobrým důvodem není, že si řeknu, že XML teď letí, a tak si v relační db udělám jednu tabulku kde bude jen ID a XML sloupec a do nich namastím úplně všechno – což by byla v lepším případě předčasná „optimalizace“ a v horším naprostá idiocie :-)
**) takže to pak ani s tím porušováním NF není tak horké, protože jednotlivé kousky XML dokumentu se dají adresovat na úrovni SQL – nepracuje se s ním jako s „hloupým“ textem, ale SŘBD těm XML strukturám „rozumí“.
***) jednoduše proto, že se to nezaplatí – aplikaci bude používat jeden zákazník (nebo pár zákazníků) – kdežto SŘBD je software, který používají tisíce nebo miliony zákazníků, mezi které se rozkládají náklady.
Koukám, že z té ukázky vypadla celkem důležitá část, tak znovu:
SELECT xpath('/my:a/text()', '<my:a xmlns:my="http://example.com">test</my:a>',ARRAY[ARRAY['my', 'http://example.com']]);
V podstatě jakákoliv ACID databáze je docela znatelně bržděná zápisem dat na trvalé médium. A zápis může brzdit čtení – tak aby byla zajištěna konzistence a izolace. To v případě ne ACID db odpadá – předpokládá se, že vždy je databáze jištěná dalším uzlem, který přebere činnost v případě výpadku a na kterém se dohledají data. To by teoreticky mohly převzít i SQL db. Třeba teď obě architektury používají multigenerační architekturu. Klasická ACID db může existovat sama o sobě, non ACID db musí mít k sobě další nezávislý hw.
Další rozdíl je v datovém modelu – key-value X normalizované tabulky. Už to tu zaznělo. Pokud řeším čtení/zápis – tak key/value model je jednodušší a rychlejší (za předpokladu, že zpracovávám entitu po entitě). V opačném případě – kdy provádím určité operace nad množinou entit, je naopak výhodnější relační model. SQL databáze jsou systémy pro hromadné zpracování dat – NoSQL db naopak systémy pro izolovaná data.
v teto oblasti je bohuzel jeste hodne poli neoranych a pojmy ktere se nachazeji v prostoru se casto prolinaji. Dnesni no-sql bych vyjadril ‚bez-schematu‘. Nebo trochu popularneji ‚dobre-pro-dokumenty‘. U nas ve firme pouzivame no-sql spise ve forme ‚nepouzivam-pro-dohledani-dat-sql-dotaz‘.
Snad jedinym jednoticim prvkem je ten pojem ‚key-value‘.
Takovych databazi existuji mraky (t.zn. nejen ty dnes moderni jako couchdb ..) a jsou tu s nami uz 30 let. Na rootu zde pred lety o nich psal myslim pan Kolar.
Radu let jsem pracoval v oblasti informacnich systemu a tam je mozno najit u malych systemu mnoho takovych, ktere nepouzivaji rel databazi. Nakonec pcfand je neco takoveho. Zrovna tak jako u relacnich databazi jsou u takovych key-value databazi data organizovana v tabulkach a misto radku se rika rekord. Navrh se provadi uplne stejne jak je to zname z oblasti relacnich databazi. Jenom neexistuje referencni integrita, trigger a vsechen ten kram, to je proste v aplikaci.
Ze zkusenosti mohu rici, ze informacni system na bazi key-value databaze je radove rychlejsi nez takovy, ktery pouziva rel databazi. Necim ty rel databaze tu ‚vyhodu‘ deklarativniho dotazu zaplatit musi → plati se tou rychlosti.
Je tu jeste jeden, mnohem zavaznejsi moment a to je modularita. Z principu rel. databazi plyne, ze dotaz na data musi byt ‚obsahly‘, ‚znaly vsech struktur databaze‘. Je nesmyslne vytvorit ‚male‘ sql dotazy, jejich vysledky pak v programu zpracovat a pouzit pro sadu dalsich ‚malych, jednouchych‘ dotazu. Takovy system by byl nemozne pomaly. Proto funguji ‚spravne‘ informacni systemy s rel databazemi tak, ze jsou v nich ‚mega-dotazy‘, ktere joinuji desitky tabulek apod.
U key-value databaze mohu dotazy ‚rozdelit‘ do mensich jednotek a ty pak cilene pouzivat. To je modularita.
<i>Je tu jeste jeden, mnohem zavaznejsi moment a to je modularita. Z principu rel. databazi plyne, ze dotaz na data musi byt ‚obsahly‘, ‚znaly vsech struktur databaze‘. Je nesmyslne vytvorit ‚male‘ sql dotazy, jejich vysledky pak v programu zpracovat a pouzit pro sadu dalsich ‚malych, jednouchych‘ dotazu. Takovy system by byl nemozne pomaly. Proto funguji ‚spravne‘ informacni systemy s rel databazemi tak, ze jsou v nich ‚mega-dotazy‘, ktere joinuji desitky tabulek apod.</i>
To je zrovna zpusob, jak napsat pomale bazmeky a monstra. Modularita je, alespon podle meho nazoru, o necem uplne jinem a s SQL nesouvisi nebo jen malo – primarne jde o jinou vrstvu. Pokud chapete modularitu jako rozdeleni aplikace do pokud mozno co nejvice izolovanych modulu, a tak pristupujete i db vrstve, pak pravdepodobne bude mit nektera data ulozena duplicitne – to neni ovsem vec SQL nebo NoSQL, ale vec architektury systemu.
Pročetl jsem si názory a rozhodl se přidat vlastní příspěvek. Dlouhodobě se pohybuji na projektech v enterprise prostředí a zažil jsem různé přístupy. Záleží hodně na architektuře a vůbec návrhu. SQL databáze je v případě třeba Oracle PLSQL univerzální řešení a prostředí nabízí bohaté možnosti pro umístění části aplikační logiky (PLSQL API, joby, mat. view … neobhajuji, jen konstatuji). Zažil jsem i XML databáze, dobré zkušenosti mám s vedlejšími proudy vývoje, kde nedochází k mapování na objekty (JAXB, XMLBeans, Castor …), ale pracuje se přímo s XML (XPath dotazy, transformace … je to efektivní, elegantní, ale také složité). Relativní novinkou je parser VTD-XML, ten v kombinace XPath může mnohdy výborně posloužit i u velmi velkých XML souborů (čtení i modifikace za běhu). Bohužel zde často vůbec nebývá řešená transakčnost apd. Osobně největší šanci dávám projektům, které na to jdou podobně jako objektové cache. Ne náhodou Terracotta pohltila projekt EHCache a zrovna Terracotta je slibným výborně škálovatelným produktem. Výhodou Terracotty (zároveň ale i omezením) je tvorba klasických Java POJO tříd a využití vícevláknového modelu Javy (což je pěkné, ale někdy i složitější na pochopení). Dalším takovým produktem je DB4O, kde je v případě .NETu výhoda ve výborném dotazovacím jazyku LINQ (ač mám Javu a UNIX rád, tohle se Microsoftu opravdu povedlo). Bez kvalitního dotazovacího jazyka jsou pro mě v 99% případech návrhů objektové databáze mrtvé, je to dobré tak na uložení konfigurace nebo logů, ale už ne na pokročilá prohledávání vztahů nebo dokonce agregace. Snad jsem někoho upozornil na zajímavé technologie. Závěrem musím říci, že v tuto chvíli bych se na většině projektů nepustil do rizika alternativy a použil ověřenou SQL databázi :)
noSQL databáze jsou něco jako assembler :-)
Humbuk kolem „noSQL“ databází
tak databáze typu NoSQL budou v podstatě zbytečná ztráta času. Relační databáze má to, co nerelační nikdy mít nemůže, a to transakce. Ty jsou základem. HOWGH…