
SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu

V předchozím dílu našeho seriálu jsme si představili SpiderMonkey, interpret JavaScriptu ve Firefoxu. Dnes si povíme o jeho vývojové verzi TraceMonkey, která zvládá kompilaci do nativního kódu pomocí nové techniky zvané trace trees. Vyzkoušet si ji můžete v betaverzích Firefoxu 3.1.
Seriál: Do hlubin implementací JavaScriptu (14 dílů)
- Do hlubin implementací JavaScriptu: 1. díl – úvod 30. 10. 2008
- Do hlubin implementací JavaScriptu: 2. díl – dynamičnost a výkon 6. 11. 2008
- Do hlubin implementací JavaScriptu: 3. díl – výkonnostně nepříjemné konstrukce 13. 11. 2008
- Do hlubin implementací JavaScriptu: 4. díl – implementace v prohlížečích 20. 11. 2008
- Do hlubin implementací JavaScriptu: 5. díl – implementace mimo prohlížeče 27. 11. 2008
- SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj 4. 12. 2008
- SquirrelFish: optimalizace vykonávání instrukcí a nativní kód 11. 12. 2008
- SquirrelFish: regulární výrazy, vlastnosti objektů a budoucnost 18. 12. 2008
- SpiderMonkey: zpracování JavaScriptu ve Firefoxu 8. 1. 2009
- SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu 15. 1. 2009
- V8: JavaScript uvnitř Google Chrome 22. 1. 2009
- Rhino: na rozhraní JavaScriptu a Javy 29. 1. 2009
- Velký test rychlosti JavaScriptu v prohlížečích 5. 2. 2009
- Javascriptové novinky: souboj o nejrychlejší engine pokračuje 19. 3. 2009
V našem seriálu jsme již několikrát zmínili, že na interprety JavaScriptu je v poslední době vyvíjen velký tlak ze strany složitých webových aplikací. Ty potřebují, aby byl JavaScript velmi rychlý. Tvůrci interpretů JavaScriptu na to reagují jejich neustálým vylepšováním a optimalizací. Vrcholem tohoto úsilí je kompilace JavaScriptu do nativního kódu, kterou v současnosti umí interprety SquirrelFish, SpiderMonkey a V8.
Do SpiderMonkey byla kompilace do nativního kódu platforem x86, x86–60 a ARM přidána v létě 2008 v rámci projektu TraceMonkey. V současnosti není k dispozici v žádné stabilní verzi Firefoxu a svou premiéru bude mít až ve Firefoxu 3.1. Je ale možné si ji vyzkoušet v nočních sestaveních nebo v betaverzích Firefoxu 3.1 – podrobnější návod najdete níže v článku.
Zatímco u SquirrelFish a V8 funguje kompilace „tradičně“, SpiderMonkey používá novou a zajímavou techniku zvanou trace trees. Tu si v dnešním článku podrobněji přiblížíme.
Tradiční kompilace do nativního kódu
Abychom pochopili motivaci techniky trace trees a její výhody, stručně si připomeneme, jak funguje tradiční kompilace do nativního kódu (viz také dřívější obecný popis způsobů interpretace).
Ve většině interpretů (nejen těch javascriptových) je nativní kód vygenerován z bajtkódu. Jedná se obvykle o poměrně mechanickou záležitost – přepis jednoho sekvenčního kódu do jiného. Generátor kódu se pouze musí rozhodovat, jak přeložit složitější instrukce bajtkódu. Může buď do nativního kódu vložit kód, který instrukci vykonává, nebo ho mít v pomocné funkci a tu z nativního kódu zavolat. Podrobněji jsme si o tomto rozhodování povídali při popisu generování nativního kódu ve SquirrelFish.
Vygenerovaný kód je obvykle „hrubý“ a neefektivní. Často tedy následuje průchod optimalizátorem, který se ho pokusí vylepšit. Obvykle se zde používá peephole optimization, což znamená, že se v kódu hledají určité sekvence instrukcí, které nejsou optimální, a nahrazují se efektivnějšími sekvencemi se stejným významem.
Důležitou otázkou je, kdy nativní kód vygenerovat. Klasické kompilátory ho generují pro celý program najednou. U interpretů je obvyklejší generovat kód až když je opravdu potřeba – například zkompilovat funkci před jejím prvním spuštěním (tak to dělá SquirrelFish). Je také možné kompilaci pozdržet a kód vygenerovat pouze pro funkce, které jsou spouštěny velmi často.
Důvodem pro odkládání generování kódu je, že kompilace je drahá (paměťově i časově), takže ji nechceme spouštět zbytečně. V ideálním případě bychom chtěli kompilovat přesně v těch případech, kdy spouštěním nativního kódu místo bajtkódu ušetříme více času, než bude trvat kompilace. Tohoto ideálu ale nelze z principiálních důvodů dosáhnout, jen se mu přiblížit.
Trace trees
Po připomenutí tradičního průběhu kompilace se už můžeme věnovat trace trees. Tuto techniku vymysleli Andreas Gal a Michael Franz z University of California. Původně ji implementovali pro virtuální stroj Javy, nebylo ale těžké ji adaptovat pro JavaScript. Podobně jako výše popsaná tradiční kompilace vychází z bajtkódu a selektivně ho kompiluje do nativního kódu.
Co kompilovat?
Výchozím bodem celé techniky je pozorování, že do nativního kódu zdaleka není potřeba kompilovat celý program, celé funkce apod. Je třeba kompilovat pouze ty části programu, kde nám opravdu záleží na výkonu. A jak ví asi každý, kdo někdy něco optimalizoval, těchto pro výkon kritických míst je v programu obvykle jen několik.
Autoři techniky toto pozorování trochu doplnili: uvědomili si, že výkonnostně kritické místo v programu je nejčastěji uvnitř cyklu. Málokdy se stane, že je pro výkon kritický kód, který běží jen jednou. (Bavíme se zde pouze o výkonu interpretu jazyka, nikoliv o zpomaleních způsobených například načítáním dat z externího zdroje. Zde samozřejmě snadno může nastat situace, že nás bude velmi zdržovat operace, která se provede jen jednou. S tím nám ale rychlejší interpret nijak nepomůže.) Kompilátor využívající trace trees proto kompiluje pouze cykly.
Průběh kompilace
Po spuštění programu interpret normálně vykonává bajtkód. Přitom v něm ale detekuje cykly (pozná je jednoduše – podle skoku zpět v posloupnosti instrukcí) a u každého nalezeného cyklu si poznamenává, kolikrát již proběhl. Jakmile počet běhů cyklu přesáhne nějaké stanovené minimum (v SpiderMonkey je to 2), interpret se rozhodne cyklus zoptimalizovat
Prvním krokem optimalizace je spuštění záznamu vykonávaných instrukcí bajtkódu. Ten běží tak dlouho, dokud nedojde ke skoku zpět na začátek cyklu. V tom případě je záznam úspěšný a výsledná zaznamenaná lineární posloupnost instrukcí bajtkódu se nazývá stopa (trace). Záznam může také skončit neúspěšně, pokud ho přeruší nějaká mimořádná událost (třeba vyhození výjimky).
Důležité je, že záznam se nezastavuje při volání funkcí, ale normálně pokračuje uvnitř volané funkce, sleduje vykonávání kódu v ní a také následný návrat do volajícího kódu. To samozřejmě platí i pro vnořená volání včetně volání rekurzivních. Pokud je ale do sebe vnořených volání příliš (ve SpiderMonkey víc než 10), záznam se přeruší.
Když je záznam stopy úspěšně dokončen, zaznamenané instrukce se zkompilují do nativního kódu. Kompilace je oproti tradičnímu kompilátoru jednodušší, protože nekompilujeme úsek programu, ale jen lineární posloupnost instrukcí odpovídající jednomu konkrétnímu průchodu cyklem. Kompilátor zde díky tomu může uplatnit několik zajímavých optimalizací a postupů, které zefektivňují výsledný kód. Na jejich podrobný popis v tomto článku bohužel nemáme prostor.
Po dokončení kompilace se ke zpracovávanému cyklu přidá odkaz na vygenerovaný kód. Ten se pak při dalších průchodech cyklem vykonává místo bajtkódu a cyklus se tak výrazně urychlí.
Stromy stop
Čtenáře možná napadne, co se stane, když se při záznamu stopy projde nějakou podmínkou. Do stopy se totiž zaznamená pouze jedna větev této podmínky. Po spuštění zaznamenané a zkompilované stopy se může stát, že podmínka už nebude platit a bude potřeba spustit druhou větev. V takovou chvíli se znovu spustí záznam vykonávaných instrukcí bajtkódu a nahraje se nová stopa, která začíná u nedodržené podmínky a prochází její druhou větví. Po kompilaci se nová stopa spojí se starou a dohromady vytvoří strom stop (trace tree). Ten může být časem i docela „košatý“, pokud je podmínek ve stopě víc (ve SpiderMonkey je „košatost“ omezena nejvýše na 16 větví, pak už se nové stopy nekompilují).
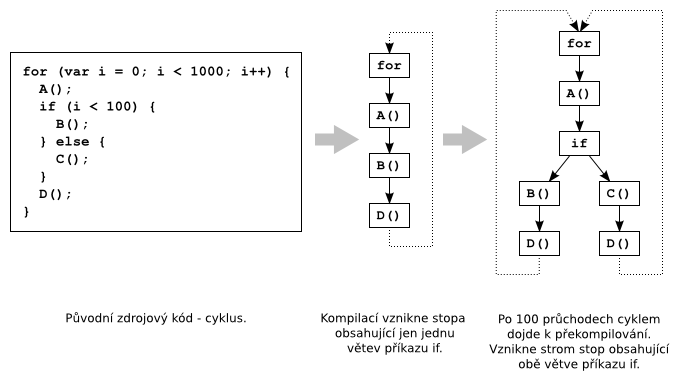
Ukázka kompilace cyklu s vnořenou podmínkou.
Podobným způsobem jako podmínky je potřeba ohlídat i další situace, kde se nám mohlo od doby nahrání stopy něco „změnit pod rukama“ – přístup k vlastnostem objektů, typy proměnných apod.
Stopy a dynamické typování
Zajímavou vlastností kompilace založené na trace trees je, že téměř eliminuje neefektivitu kódu způsobenou dynamickým typováním. Stopa je zkompilována s předpoklady o typech proměnných platných při jejím nahrání (jsou do kódu přidány jako umělé podmínky). Zkompilovaný kód může na tyto informace spoléhat podobně jako u staticky typovaných jazyků a je tedy přibližně stejně rychlý. Jakmile se typ nějaké proměnné změní a za běhu zkompilované stopy se na to přijde, je (podobně jako u obyčejných podmínek) nahrána nová stopa s novými předpoklady o typech proměnných, na které opět může spoléhat.
Podobně jako u dříve popsané inline keše se zde ukazuje, že absence statického typování v jazyce ve skutečnosti neovlivňuje rychlost jeho zpracování tak moc, jak by se mohlo na první pohled zdát. Vývojáři SpiderMonkey ostatně věří, že brzy se bude rychlost JavaScriptu moci srovnávat s rychlostí céčka a třeba u jednoduchého cyklu je rychlost srovnatelná už dnes (pokud uvažujeme neoptimalizovaný kód vyprodukovaný kompilátorem gcc).
Shrnutí
Co byste si měli z předchozího textu o trace trees odnést? Že je to technika kompilace do nativního kódu, která pracuje pouze s často spouštěným kódem uvnitř cyklů. Místo složité kompilace části programu kompiluje pouze jeden konkrétní průchod cyklem. To celý proces značně zjednodušuje a výsledný kód může být lépe optimalizován než v obecném případě. Pokud je možných průchodů cyklem více, zpracují se postupně všechny, na které se při běhu programu narazí. Podobně se postupně zkompilují různé verze kódu podle typů proměnných, které jsou v něm používány.
Hlavní výhodou trace trees je selektivnost a rychlost kompilace spojená s jednoduchostí celé techniky a efektivní prací s dynamicky typovaným kódem. Začlenění kompilátoru založeného na trace trees do existujícího interpretu navíc obecně vyžaduje jen minimální úpravu původního kódu (v podstatě stačí přidat detekci cyklů a počtu průchodů skrze ně, aktivaci záznamu stopy a možnost jejího přehrání). Především tyto důvody pravděpodobně vedly vývojáře SpiderMonkey k tomu, že trace trees použili.
Jak velké je zrychlení?
Kompilace do nativního kódu pomocí trace trees poměrně výrazně urychluje vykonávání JavaScriptu. Grafy v původním oznámení o použití této techniky ukazují i více než třicetinásobné zrychlení u některých konkrétních benchmarků. Podle dva a půl měsíce starého měření Pavla Cvrčka bylo tehdy aktuální noční sestavení Firefoxu 3.1 se zapnutou kompilací v testu SunSpider cca 2× rychlejší oproti Firefoxu 3.0.3, který kompilaci nepodporuje. V testu Dromaeo je rozdíl méně patrný, zrychlení je pouze přibližně čtvrtinové. To nejspíš souvisí s tím, že Dromaeo netestuje jen samotný JavaScript, ale také operace s DOM.
Pro Firefox je urychlení JavaScriptu důležité i proto, že tento jazyk je používán i pro oživení jeho uživatelského rozhraní (to je napsáno ve speciálním značkovacím jazyce XUL a způsobem fungování se příliš neliší od běžných webových stránek). Rychlejší JavaScript tedy neznamená jen svižnější webové aplikace, ale i Firefox jako takový.
K rychlostním srovnáním je třeba dodat, že vývoj interpretu probíhá velmi rychle a je docela možné, že v tuto dobu budou rozdíly mezi verzemi ještě výraznější, než naznačují odkazované benchmarky. Pokud má někdo ze čtenářů chuť, může si zkusit testy zkusit spustit sám s aktuální verzí interpretu a podělit se o výsledky.
Vyzkoušejte si rychlejší JavaScript
Jak již bylo řečeno, kompilaci do nativního kódu podporují aktuální noční sestavení Firefoxu a také obě betaverze Firefoxu 3.1. Kompilace je v tuto chvíli standardně zapnutá pouze pro skripty webových stránek, nikoliv už pro skripty použité v uživatelském rozhraní. Nastavení můžete změnit v about:config nastavením hodnot javascript.options.jit.content a javascript.options.jit.chrome na true nebo false. První hodnota určuje, zda se budou kompilovat skripty ve webových stránkách, druhá zda skripty v uživatelském rozhraní. Na wiki Mozilly najdete o něco podrobnější návod.
Co nás čeká příště
Dnešním dílem jsme ukončili povídání o SpiderMonkey. Příště se podíváme na V8, což je interpret JavaScriptu používaný v prohlížeči Google Chrome.
Zdroje
- TraceMonkey: JavaScript Lightspeed – popis implementace trace trees ve SpiderMonkey
- A. Gal, C. W. Probst, M. Franz: Hotpath VM: An Effective JIT Compiler for Resource-constrained Devices – srozumitelný popis techniky trace trees a její implementace pro JVM
- A. Gal, M. Franz: Incremental Dynamic Code Generation with Trace Trees – trochu techničtější popis trace trees
- M. Chang, M. Bebenita, A. Yermolovich, A. Gal, M. Franz: Efficient Just-In-Time Execution of Dynamically Typed Languages Via Code Specialization Using Precise Runtime Type Inference – využití trace trees a další techniky zvané double dispatch k urychlení JavaScriptu kompilovaného do bajtkódu Javy
David Majda
Autor je vývojář se zájmem o programovací jazyky, webové aplikace a problémy programování jako takového. Vystudoval informatiku na MFF UK a během studií zde i trochu učil. Aktuálně pracuje v SUSE.



Pro FF je dulezita nejen rychlost JS interpreteru, ale i to jakym zpusobem se pouziva. SpiderMonkey je sam o some multivlaknovy interpret JS. Ve FF ale bohuzel bezi v jednom vlakne a vykonava kod ze stranek i kod z handleru v XULu. To znamena, ze stranka, ktera obsahuje neefektivni JS kod, muze na nejaky cas zablokovat ovladani cele aplikace.
Čtení tohoto seriálu mi připadá jako přehlídka zbytečně promarněné námahy chytrých lidí, kteří by určitě mohli dělat neco užitečnějšího než optiomalizaci ECMAScriptu. Nebylo by mnohem efektivnější navrhnout a implementovat pro psaní složitých webových aplikací nějaký pořádný jazyk s jednoduchou a efektivní kompilací, místo ztrácení času na optimalizaci kompilátoru špatně navrženého jazyka? (I když, samozřejmě, jako duševní rozcvička to může být zábavné.) Navíc, právě ty rysy ECMAScriptu, které dělají jeho interpretaci/kompilaci obtížnou, žádný programátor hodný toho jména v životě nepoužije, protože jenom zhoršují porozumění programu a ztěžují jeho udržovatelnost.
To mate to same jako uz mnohokrate diskutovane CISC versus RISC, x86 vs. zbytek sveta a podobne. Jakmile se neco uchyti tak se to stane defakto standartem a jedina moznost jak s tim neco udelat je to proste vylepsit.
Co se tyce "poradneho" jazyka na psani webu – myslim ze jednodusi bude nejaka uprava v budoucnu (at uz treba ke kvalitni podpore OO, zahozeni problematickych casti nebo i jinak) nez jeho kompletni zahozeni…
Mám několik poznámek:
Ad 4.: Stačí si přečíst 3. díl tohoto seriálu.
Z toho mi přijde opravdu relevantní pouze inspekce zásobníku spojená s prací s argumenty volajících funkcí. To jsem totiž opravdu nikdy neměl potřebu použít a nedovedu si v tuto chvíli představit, jaké rozumné využití by to mohlo mít kromě debuggingu. (Ale má fantazie je omezená :-)
Ostatní problematické oblasti zmiňované v článku (
evalawith) mají své využití (byť omezené). Výkonnostní problémy způsobené příkazemwith(zbrždění lookupu) jsou dány jeho podstatou. Uevallze diskutovat o tom, nakolik je nutné, aby uměl ovlivňovat své okolí, a zda by nebylo vhodnější, aby měl svůj vlastní scope. Myslím ale, že use-casy, kde je ovlivnění okolního scope nutné, by se našly.pri vykonech dnesnich cpu…
Ale milionkrát nic umoří i vola ;-)
"… absence statického typování v jazyce ve skutečnosti neovlivňuje rychlost jeho zpracování tak moc, jak by se mohlo na první pohled zdát…" … srovnatelná rychlost s C …
Vím že už to tu bylo v komentářích, ale pořád to nevidím – pokud vím (ať už ze statického typování, nebo z hintů pro kompilátor ala Lisp), že sčítám malá celá čísla a výsledek je rovněž malé celé číslo, můžu generovat jednu sčítací instrukci. Pokud to nevím, musím kontrolovat přetečení do bigintů, nebo riskovat že dostanu špatný výsledek. Pokud je toto v hlavní smyčce (nebo to nekontroluje HW jako údajně v Lisp Machine), rychlosti Cčka se nedosáhne. Jak tohle úskalí chtějí překonat?
Hmm, asi neporovnavaji vysledky u programu ktery jen scita mala cisla a driv nez pretecou tak skonci :-)
Nejdřív trochu šířeji: Při opakování tvrzení, že dynamické jazyky mohou být skoro stejně rychlé jako statické, mi jde především o to, abych vyvrátil poměrně zaběhnuté mýty, že musí být řádově pomalejší. Tyto mýty jsou založené na tom, že dynamický jazyk „musí“ být interpretovaný, „musí“ hledat metody a vlastnosti v hash tabulkách a že neznalost typů předem je „drahá“.
Mýty jsou způsobeny tím, že když člověk dostane do ruky popis dynamického jazyka, přečte si ho a začne přemýšlet, jak by ho implementoval, napadnou ho jen naivní řešení všech možných problémů a z toho usoudí, že to celé musí být hrozně pomalé. Sám jsem tak kdysi uvažoval, takže si to dovedu představit. Tyto úvahy se pak šíří dál a jsou podpořeny i tím, že interprety běžných dynamických jazyků různé naivní techniky často používají a opravdu jsou typicky řádově pomalejší než jazyky statické.
Celým seriálem se jako červená nit vine myšlenka, že spoustu zdánlivých nedostatků dynamických jazyků z pohledu výkonu lze v mnoha běžných případech chytrou optimalizací téměř eliminovat, což se může zdát překvapivé. Když mluvím o „srovnatelné rychlosti s C“, tak tím nemyslím, že zpracování jazyka bude rychlejší (to až na vyjímky nebude z principielních důvodů), ale že se bude lišit „o malé konstanty“, ne „o řády“.
Teď konkrétně: Ano, u sčítání se stále musí kontrolovat typ, tj. především zda jde o celé číslo. To je konkrétně ve SpiderMonkey záležitost testu jednoho bitu = 1 nebo 2 instrukce procesoru (nepamatuji si už příliš x86 assembler a nechce se mi hledat). V terminologii TraceMonkey se těmto instrukcím říká guard instructions. Stejně tak se musí kontrolovat přetečení – opět záležitost jedné nebo několika málo guard instructions. Skoky související s těmito testy jsou procesorem dobře predikovatelné, testy tedy nebudou obvykle způsobovat vyprázdnění pileline procesoru.
V ideálním případě (testy typu a přetečení se vejdou do 1 instrukce) se tedy u cyklu sčítajícího dokola dvě proměnné s čísly dostáváme na něco jako 4 instrukce na cyklus, vs. 1 instrukce na cyklus u céčka. Při složitějších operacích bude overhead menší. Bez statické analýzy bude nějaký overhead existovat stále, podstatné ale je, že to jsou jednotky instrukcí, nikoliv stovky či tisíce, jak je tomu u běžných interpretů.
Nevím, jestli se mi povedlo dostatečně vyjádřit, jak to se „srovnatelnou rychlostí“ myslím, ale snad ano.
První odstavec je asi opravdu klíčový, pak s tím nemám problém. Jen jsem nevěděl, že ten mýtus pořád ještě existuje a je rozšířený.
Já jsem to schválně zkusil na svém zvýrazňovači syntaxe, do kterého jsem shodou okolností zrovna dnes dodělával nějaké optimalizace, a bohužel to zatím nefunguje. Ve skriptu je ošetřen stav, ke kterému by teoreticky nikdy nemělo dojít a přesně k němu v Firefoxu 3.1 Beta 2 se zapnutým
javascript.options.jit.contentdojde (s vypnutým ne).Nahlásil jsem to jako bug 473777.
V 1.9.1b2 to skutečně nefungovalo, v 1.9.2a1-pre to už zdá se funguje. Ke zrychlení mého testu ale bohužel nedojde – naopak došlo ke zpomalení (měřeno Firebugem).
V současnosti ten JIT pořád ladí, takže bugy ani zpomalení mě nepřekvapují. Ostatně nedoladěnost TraceMonkey je hlavním důvodem odsunu vydání 3. bety Firefoxu 3.1.
Zpomalení bych klidně reportoval jako bug (možná s nějakým omezenějším testcasem).
Možná to doopravdy reportuji, protože moje implementace zvýrazňovače syntaxe je podle mě pro kompilaci ideální – mnohokrát opakovaný cyklus, který se sice hodně větví, ale v zásadě pořád do stejných větví.
Jestli to pomůže, tak mě to nefunguje jenom při zvýrazňování syntaxe v php ostatní syntaxe fungujou…
Mám tehle prohlížeč: Mozilla/5.0 (X11; U; Linux i686; cs; rv:1.9.1b2) Gecko/20081201 Firefox/3.1b2 a zkoušel jsem to v online demu co je přímo na těch odkazovaných stránkách.
Dekuji autorovi i cele redakci zdrojaku za super clanky. Tento k nim urcite patri take…