
SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj

Tímto dílem začínáme část seriálu o implementacích JavaScriptu, která se bude věnovat vnitřnostem konkrétních implementací. Začneme s popisem vybraných částí interpretu SquirrelFish – podíváme se, jak se v něm reprezentují hodnoty javascriptových proměnných a jak je navržen jeho virtuální stroj a bajtkód.
Seriál: Do hlubin implementací JavaScriptu (14 dílů)
- Do hlubin implementací JavaScriptu: 1. díl – úvod 30. 10. 2008
- Do hlubin implementací JavaScriptu: 2. díl – dynamičnost a výkon 6. 11. 2008
- Do hlubin implementací JavaScriptu: 3. díl – výkonnostně nepříjemné konstrukce 13. 11. 2008
- Do hlubin implementací JavaScriptu: 4. díl – implementace v prohlížečích 20. 11. 2008
- Do hlubin implementací JavaScriptu: 5. díl – implementace mimo prohlížeče 27. 11. 2008
- SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj 4. 12. 2008
- SquirrelFish: optimalizace vykonávání instrukcí a nativní kód 11. 12. 2008
- SquirrelFish: regulární výrazy, vlastnosti objektů a budoucnost 18. 12. 2008
- SpiderMonkey: zpracování JavaScriptu ve Firefoxu 8. 1. 2009
- SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu 15. 1. 2009
- V8: JavaScript uvnitř Google Chrome 22. 1. 2009
- Rhino: na rozhraní JavaScriptu a Javy 29. 1. 2009
- Velký test rychlosti JavaScriptu v prohlížečích 5. 2. 2009
- Javascriptové novinky: souboj o nejrychlejší engine pokračuje 19. 3. 2009
Na začátek bychom měli říct, proč začínáme právě interpretem SquirrelFish. Důvodem je především to, že jde o koncepčně asi nejčistší z interpretů, které si budeme popisovat, a můžeme si na něm dobře vysvětlit terminologii a základní techniky použité i v dalších interpretech. SquirrelFish budeme proto věnovat o něco více prostoru.
Místy budeme také víc než o interpretu samotném mluvit o obecnějších principech za ním. Věřím že podrobnější vysvětlení technického pozadí a rozhodnutí, která musí tvůrci interpretů učinit, jsou mnohem zajímavější než pouhé konstatování, že je něco „uděláno tak a tak“.
Připomenutí
SquirrelFish je interpret pohánějící webový prohlížeč Safari a je vyvíjen firmou Apple. Umí kompilovat JavaScript do bajtkódu, který je pak interpretován virtuálním strojem. Vývojová verze SquirrelFish Extreme umí generovat i nativní kód (na platformě x86). SquirrelFish je open source – stejně jako celé zobrazovací jádro WebKit, jehož je součástí. Detaily o historii jeho vývoje najdete ve čtvrtém dílu našeho seriálu, my se dnes budeme zabývat jeho aktuální verzí.
Reprezentace hodnot
Jedním z prvních rozhodnutí, které musí učinit návrháři jakéhokoliv interpretu je, jakým způsobem reprezentovat hodnoty interpretovaného jazyka v jazyce implementačním (v případě SquirrelFish je to C++). Toto rozhodnutí má podstatný vliv na výkon interpretu. V dalším textu budeme pro jednoduchost mluvit o hodnotách proměnných, ale vše platí i pro hodnoty atributů, parametry funkcí, návratové hodnoty atd.
V dynamických jazycích neznáme obecně předem typy proměnných – ty závisí na hodnotách, které jsou v nich uloženy. Součástí informace o hodnotě proměnné musí být tedy také její typ, protože ho není jak jinak zjistit.
Samotné hodnoty proměnných jsou dost různorodé. JavaScript má kupříkladu šest základních datových typů: Undefined, Null, Boolean, Number, String a Object. První dva typy jsou speciální a mají jen jednu hodnotu (undefined a null), Boolean může nabývat pravdivostních hodnot true a false, Number je 64-bitové číslo s plovoucí řádovou čárkou, String libovolně dlouhý řetězec znaků a Object objekt s libovolným počtem vlastností. Je zřejmé, že hodnoty různých datových typů mají různé nároky na paměť a některé jí mohou zabrat i neomezené množství (String a Object).
Naivní řešení
První způsob, jak hodnoty reprezentovat, napadne asi každého: dvojici (typ, hodnota) uložit do céčkového struct. Položka obsahující hodnotu by pak mohl být union, který by obsahoval překrývající se položky pro různé datové typy. Pro String a Object bude potřeba, aby naše struktura měla proměnlivou délku, nebo jako hodnotu obsahovala odkaz na nějakou další strukturu.

Příklad reprezentace čísla a textu pomocí dvojice (typ, hodnota).
Nevýhoda uvedené reprezentace je, že se s ní v céčku špatně pracuje. Hodnoty je totiž potřeba neustále kopírovat (například při přiřazení či předání hodnoty jako parametru funkce), což je ale v našem případně relativně náročná operace (kopíruje se celá struktura). Alternativou by bylo předávat ukazatel na strukturu, ale to znamená neustálé zpomalující dereference a ne vždy je to možné.
Zlepšení
Možným vylepšením je zaznamenat informace o typu i hodnotě do místa v paměti o velikosti ukazatele na dané platformě. Využijeme přitom faktu, že díky zarovnávání bývá několik nejnižších bitů ukazatele nulových. Můžeme je tak použít k zakódování informací o typu hodnoty. Hodnotu samotnou pak buď zakódujeme do zbývajících vyšších bitů ukazatele (pak jí budeme říkat okamžitá hodnota), nebo do nějaké složitější struktury, na kterou bude ukazatel odkazovat (referencovaná hodnota).
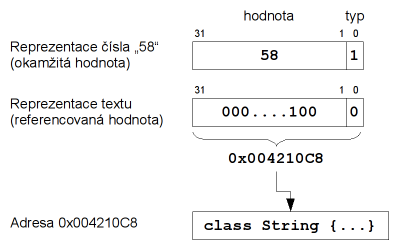
Příklad vylepšené reprezentace čísla a textu.
Zjištění typu hodnoty bude nyní otázka jednoduché bitové manipulace a u okamžitých hodnot zjistíme i hodnotu proměnné bez dereference ukazatele. Jelikož se reprezentace hodnoty vejde do jednoho slova dané platformy, její kopírování bude efektivní.
Uvedená reprezentace není ve světě programovacích jazyků nic nového – je v interpretech používaná už několik desítek let. Její nevýhodou je neportabilita a v případě implementace v jazyce C/C++ také porušení normy ANSI (ta nezaručuje, že velikost ukazatele odpovídá nějakému celočíselnému typu, a tedy že je možné na ukazatelích provádět korektně bitové operace).
Jak je na tom SquirrelFish?
SquirrelFish uvedenou optimalizaci využívá – přesný formát reprezentace hodnot lze vyčíst z komentáře na začátku souboru JSImmediate.h. Jako okamžité hodnoty jsou zde chápány undefined, null, true , false a 31-bitová (či 63-bitová) celá čísla (reprezentující část hodnot typu Number). Všechno ostatní je reprezentováno jako ukazatele na instance třídy JSValue, nebo přesněji řečeno na instance některé z jejích podtříd, které odpovídají zbývajícím typům. V atributech těchto tříd je uložena samotná hodnota proměnné.
Můžeme tedy říct, že manipulace s booleovskými proměnnými, celými čísly a speciálními hodnotami null a undefined je ve SquirrelFish velmi rychlá. U ostatních typů bude docházet ke zpomalení kvůli dereferencím.
Bajtkód a virtuální stroj
Základem SquirrelFish je interpret bajtkódu – virtuální stroj (co je virtuální stroj jsme naznačili již v 3. dílu). Návrh tohoto stroje a bajtkódu samotného je další věcí, která velmi ovlivňuje rychlost interpretu.
Zásobník vs. registry
Virtuální stroje mohou být v zásadě dvojího typu: zásobníkové a registrové.
Zásobníkový stroj obsahuje zásobník, na který jsou v průběhu vyhodnocování programu ukládány používané hodnoty. Se zásobníkem se dá pomocí instrukcí stroje manipulovat (přidání hodnoty na vrchol, odebrání hodnoty z vrcholu, prohození nejvyšších dvou hodnot apod.) a mnohé instrukce to dělají implicitně (např. instrukce add odebere dvě nejvyšší hodnoty ze zásobníku, sečte je a umístí na vrchol výsledek).
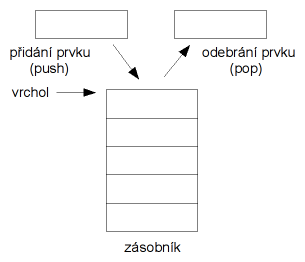
Zásobník a jeho operace.
Registrový stroj, podobně jako reálný procesor, disponuje několika registry, ve kterých má uloženy hodnoty, se kterými provádí výpočty. Oproti procesorům je ale počet registrů obvykle větší – typicky desítky či stovky. Kód k registrům přistupuje explicitně indexem.
Aby bylo vše zamotanější, registry samotné bývají obvykle také uspořádány do zásobníku a každá funkce má svou sadu registrů. V některých virtuálních strojích se navíc sousední sady registrů na zásobníku mohou v paměti překrývat. Při předávání parametrů či návratových hodnot funkci tak není potřeba kopírovat hodnoty z jedné sady registrů do druhé, což vede ke zrychlení.
Které stroje jsou lepší?
Zásobníkové stroje jsou obecně jednodušší na programování. Hodně instrukcí v kódu pro takový stroj je ale obvykle vyplýtváno na manipulaci se zásobníkem a kód je tak oproti registrovým strojům co do počtu instrukcí delší. Kód registrových strojů jde díky absenci zásobníku více „k věci“, instrukce jsou ale obvykle složitější a jejich vykonání tak déle trvá.
Důležitým faktorem je délka instrukcí, která bývá u registrových strojů obvykle větší kvůli explicitnímu uvádění operandů (u zásobníkových strojů jsou operandy většinou implicitně hodnoty na vrcholu zásobníku). Kód registrového stroje je tedy oproti zásobníkovému kratší co do počtu instrukcí, ale často zabírá více paměti. Více přístupů k paměti samozřejmě vykonávání kódu zpomaluje.
Dalším faktorem ovlivňujícím výkon je rychlost dispatchingu instrukcí – tj. jak rychle virtuální stroj najde kód vykonávající danou instrukci a spustí ho. Tato operace je při jednoduché implementaci relativně pomalá, což nahrává spíše registrovým strojům, které instrukcí vykonají méně. Se zrychlováním dispatchingu se rozdíl mezi zásobníkovými a registrovými stroji stírá.
Vlastnosti obou typů strojů přehledně shrnuje následující tabulka:
| Vlastnost | Zásobníkový stroj | Registrový stroj |
|---|---|---|
| počet instrukcí v kódu | velký | malý |
| vykonání instrukce | rychlé | pomalé |
| operandy | implicitní | explicitní |
| délka instrukcí | krátké | dlouhé |
| délka kódu | malá | velká |
Nelze asi úplně jednoznačně říct, který typ strojů je lepší, ale zdá se, že v poslední době se implementace interpretů přiklánějí spíše k architekturám registrovým. Podobný názor vyjadřuje i většina publikovaných vědeckých článků z oblasti výzkumu virtuálních strojů, které jsem četl.
Stroj uvnitř SquirrelFish
Jak vypadá virtuální stroj uvnitř SquirrelFish? Především je registrový. Hodnoty registrů jsou uloženy v jednom velkém staticky alokovaném poli, ve kterém se vytváří rámce (call frames) pro jednotlivé funkce. Ty se mohou kvůli ušetření kopírování parametrů a návratových hodnot překrývat. Z kódu jsou pak registry adresovány vůči těmto rámcům, nikoliv absolutně. Práce s registry je poměrně dobře optimalizována.
Statická alokace pole s registry samozřejmě znamená, že při velmi hlubokém zanoření volání funkcí může dojít k přetečení zásobníku, i když je ještě k dispozici dostatek paměti. Autoři SquirrelFish se tomu snaží zabránit dostatečnou velikostí pole, které standardně pojme 524 288 registrů. Na Unixových systémech je toto pole kvůli optimalizaci alokováno pomocí funkce mmap.
Bajtkód SquirrelFish je (jak je u interpretů dynamických jazyků obvyklé) poměrně vysokoúrovňový a jeho operace z velké části přímo korespondují s operacemi jazyka. Instrukce nemají pevnou délku a skládají se z opkódu (tedy čísla identifikujícího instrukci) a variabilního počtu operandů. Opkód i operandy mají velikost jednoho slova na dané platformě (tj. 32 či 64 bitů). Aktuální vývojová verze SquirrelFish má celkem 86 instrukcí, jejichž stručný popis lze nalézt na webu WebKitu.
Pokud by vás zajímaly bližší podrobnosti o implementaci registrového stroje a jeho bajtkódu, je nutno se ponořit přímo do zdrojového kódu interpretu, především do souborů v adresáři JavaScriptCore/interpreter. Jádro implementace samotného interpretu je v souboru Interpreter.cpp – hlavní smyčku interpretu tvoří metoda Interpreter::privateExecute. V komentáři na začátku souboru RegisterFile.h je podrobněji popsán formát registrů. Podoba instrukcí je definována v souboru Instruction.h.
Dispatching instrukcí
Jak již bylo řečeno výše, jedním z problémů virtuálních strojů je rychlost dispatchingu instrukcí. SquirrelFish to donedávna řešil technikou zvanou direct threading a v nejnovějších verzích pak pomocí context threading. Druhá technika souvisí s generováním nativního kódu, který SquirrelFish nyní také umí. Na obojí se podíváme v příští části.
Zdroje
Hlubším zájemcům o problematiku virtuálních strojů doporučuji pro další studium článek Virtual Machine Showdown: Stack Versus Registers, ze kterého také pochází některá pozorování uvedená v článku. Neméně zajímavý je i popis architektury interpretu jazyka Lua, kterým byl SquirrelFish do značné míry ovlivněn.
David Majda
Autor je vývojář se zájmem o programovací jazyky, webové aplikace a problémy programování jako takového. Vystudoval informatiku na MFF UK a během studií zde i trochu učil. Aktuálně pracuje v SUSE.



Pochvala: paradni serial, vazne
Dotaz: nevite nekdo, jak reprezenruje hodnoty V8? Koukal jsem do zdrojaku, ale vycist se mi to nepodarilo
pochvala +1
Děkuji za pochvalu.
K reprezentace hodnot ve V8 se dostaneme při popisu tohoto interpretu, na který dojde prevděpodobně někdy v lednu.
Dekuji za hezky clanek. Uvital bych, kdybyste napsal clanek, v kterem byste vysvetlil, jak funguje uvnit interpret pythonu, dekuji.
S autorem seriálu jsme dohodnuti pouze na interpretech JavaScriptu. Čímž nevylučuji, že bychom někdy v budoucnu na Zdrojáku nemohli něco podobného napsat i o Pythonu.
Pythonu bohužel nerozumím do takové hloubky, abych si o něm troufnul cokoliv psát, natož pak popisovat jeho interpret.
Mna by zaujimal rozdiel v praci s tymito premennymi:
var str1 = new String("smt1");
var str2 = "smt2";
Opdovídám trochu pozdě, ale přece…
Tato konstrukce vytvoří objekt (hodnotu typu
Object), jehož prototyp bude rovenString.prototype. Tento objekt je zapouzdřením řetězce do objektu, samotnou hodnotu řetězce bude mít uložen ve svém interním atributu. Interně bude tento objekt reprezentován odkazem na instanci třídyStringObject, v jejímž atributum_internalValuebude odkaz na instanci třídyJSStringreprezentující hodnotu řetězce. Při následném přiřazení se odkaz naStringObjectumístí do tabulky lokálních proměnných na místo indexovanéstr1.Tato konstrukce vytvoří hodnotu (nikoliv objekt!) typu
String, jejíž obsahem bude"smt2". Interně bude tato hodnota reprezentována odkazem na instanci třídyJSString, v jejímž atributum_valuebude uložen samotný řetězec. Při následném přiřazení se odkaz naJSStringumístí do tabulky lokálních proměnných na místo indexovanéstr2.Pokud bych to měl celé shrnout: Ve druhém případě vytváříme (v javovské terminologii) primitivní hodnotu, zatímco v prvním případě wrapper okolo ní. Interně to zanemná přidání jedné úrovně tříd a ukazatelů navíc.
Takze som dobre pochopil, ze druhy sposob je rychlejsi. Potom vsak nevidim dovod pouzivat prvy sposob okrem pripadov, kedy je potrebne predefinovat/pridat nejake metody na triede String.
Ono to není potřeba používat v podstatě nikdy, protože v situaci, kdy se s řetězcovou hodnotou zachází jako s objektem, dojde k automatické konverzi této hodnoty na objekt (jakoby se obalí voláním
new String(...)).S tym uplne nemozem suhlasit napr. "test".prototype.alert=alert alebo ako ste to inak mysleli?
Volat
prototypepřímo na hodnotě řetězce nemá smysl, protože výsledek budeundefined(vlastnostprototypemají definovanou pouze funkce).Myslel jsem to takto:
Pěkný článek, gratuluji!
Ten pomalý a stále více znatelný příklon spíše k registrovým VM (začalo to Parrotem, později Lua atd.) je také způsobený tím, že prakticky všechny moderní procesorové platformy jsou založené na registrech, takže se hoodně investovalo do kvalitních překladačů pro registrové mikroprocesory (a mnoho věcí z překladačů se dá použít při JIT kompilaci). Posun v oblasti zásobníkových strojů je poměrně malý, sice pár odborných článků na toto téma vyšlo (EuroForth apod.), ale oproti mainstreamu to je slabší, což je IMHO škoda.
Mimochodem, například Javovský VM (JVM) se sice tváří, že je zásobníkový, ale jen pro vyhodnocování výrazů. Předávání parametrů je přes standardní rámce, což je odklon od klasického "dvouzásobníkového" VM, který například používá Forth.
Pokud vím, tak
nullnení základní datový typ a je reprezentován objektem. Ve výčtu naopak chybí datový typfunction. Možná to má SquirrelFish jinak, ale v článku je to napsáno jako kdyby to platilo pro celý JavaScript.Podle specifikace ECMA-262 (konkrétně podle úvodu kapitoly 8) je to skutečně tak, jak píšu:
Jiná věc je, co vrací operátor
typeof. A zde je pravda, že pro typNullvrací"object"a pro funkce vrací"function", byť jsou to formálně hodnoty typuObject. Toto chování je specifikováno v ECMA-262 v odstavci 11.4.3.Při popisu jazyka obecně vycházím ze specifikace ECMAScriptu, ne z konkrétních implementací a jejich reprezentací. Ve chvíli, kdy v sérii článků píšu o více implementacích, není myslím jiný přístup schůdný.