
Upgradujeme MySQL server

Hardware je velmi rychle se rozvíjející oblastí IT a výkon počítačů neustále roste. Pojďme se podívat na to, jak správným způsobem upgradovat stávající databázový server, abychom maximalizovali výkon s co nejmenšími náklady.
Seriál: Optimalizujeme výkon MySQL (2 díly)
- Zvyšujeme výkon MySQL změnou konfigurace 14. 6. 2010
- Upgradujeme MySQL server 28. 6. 2010
V minulém článku „Zvyšujeme výkon MySQL změnou konfigurace“ jsme se zabývali optimalizací výkonu databázového serveru z hlediska nastavení systémových proměnných MySQL. Jednalo se o maximalizaci výkonu nevyžadující investiční náklady. V tomto díle pojednáme o tom, jak postupovat v případě upgrade hardwarové konfigurace serveru.
Někteří mohou namítnout, že vertikální škálování je přece jasnou záležitostí a není o čem psát, natož pak samostatný článek. Stačí přece přidat více paměti, koupit výkonnější procesor a rychlejší disky.
V následujícím textu rozebereme postup, jak správně přistoupit k upgradu databázového serveru MySQL. Provedeme počáteční analýzu stavu, pokusíme se detekovat úzká hrdla, zjistíme charakteristiku databázového stroje a navrhneme výměnu hardwarových komponent, které zajistí maximalizaci výkonu. Celý postup je možné zobecnit (až na některé detaily) na libovolný relační databázový server.
Jak lze vyhodit peníze
Vezměme si následující příklad konfigurace serveru: 1x DualCore CPU 1,6 GHz, 2 GB RAM,. Na serveru je nainstalovaný 32-bitový operační systém GNU/Linux a MySQL server verze 4.1. Běžné vytížení MySQL serverem je 50% CPU, 80% RAM, 100% I/O operací a 40% sítě. Jelikož stroj je přetížený, rozhodneme se jej upgradovat na maximální možnou konfiguraci:
2x 120 GB SATA disky v RAID 1, 1 Gbit Ethernet1x QuadCore CPU 2,0 GHz, 8 GB RAM, +2x 120 GB SATA disky pro.
zprovoznění RAID 0+1
Naše „hurá akce“ nás stála, řekněme, 20 000,– Kč a zvýšila náklady na hostování serveru o 1500,– Kč měsíčně. Při následném měření jsme zjistili, že MySQL vytěžuje CPU na 35 %, využívá 32 % RAM a diskové operace jsou stále na 100 %.
Právě se nám povedlo úspěšně promrhat 20000 Kč + dalších 18000 Kč ročně za 12% růst výkonu. Proč?
- Náš 32-bitový Linux systém umí sice adresovat 8 GB RAM, nicméně pro jednotlivé procesy nepovoluje využít více než kolem 2,5 GB RAM . Nemá smysl tedy osazovat RAM na 8 GB, pokud neprovedeme reinstalaci na 64-bitový OS. Navíc MySQL verze 4.1 nám nemusí povolit využívat takové množství paměti (nutno ověřit nastavení proměnných vůči dokumentaci).
- Zbytečně jsme investovali do nákupu lepšího CPU, ačkoliv původní CPU bylo vytížené pouze na 50%.
- Diskové operace se nám povedlo optimalizovat pomocí RAID 0+1, nicméně vlivem nedostatku RAM je nadále nutné neustálé čtení a zápisy z/na disk.
Analyzujeme aktuální stav
Ukázali jsme si, že upgradem hardware databázového serveru bez předchozí analýzy stavu, jsme sice výkon serveru zvýšili, nicméně vynaložené prostředky neodpovídají kýženému výsledku.
Dříve než začneme bezhlavě nakupovat nový hardware, je dobré si zjistit limity, které má provozovaný operační systém či databázový software (zejména možnosti nastavení systémových proměnných, omezení vyplývající z používané verze, apod.).
Poté, co máme definováno, jaké jsou limity software, přistoupíme ke zjišťování úzkého hrdla našeho databázového stroje. Limitujícími faktory jsou zejména velikost paměti RAM, rychlost CPU, čekání na dokončení I/O operací či latence nebo šířka pásma sítě.
Pro analýzu stavu operačního systému je možné využít běžně dostupných nástrojů poskytovaných operačním systémem. Na Linuxu můžeme využít například nástroje vmstat a iostat.
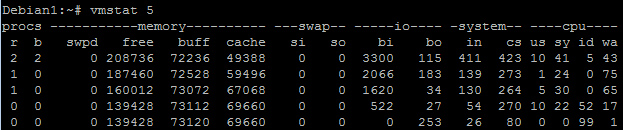
Obr 1. Ukázka výstupu nástroje vmstat
Výstupy podávané nástrojem vmstat
- procs
- r – počet procesů čekajících na CPU,
- b – počet procesů v režimu spánku (čekají na I/O, síť, vstup uživatele);
- memory
- swpd – počet bloků paměti stránkovaných na disk,
- free – počet volných bloků paměti,
- buff – počet bloků používaných pro buffery,
- cache – počet bloků cache operačního systému;
- swap
- si – počet bloků za sekundu swapovaných na disk,
- so – počet bloků za sekundu swapovaných z disku;
- io
- bi – počet bloků za sekundu zapisovaných na blokové zařízení,
- bo – počet bloků za sekundu čtených z blokového zařízení;
- system
- in – počet přerušení za sekundu,
- cs – počet přepínání kontextu za sekundu;
- cpu
- us – celkový čas v % strávený vykonáváním uživatelského kódu,
- sy – celkový čas v % strávený vykonáváním systémového kódu,
- id – celkový čas v % strávený nečinností,
- wa – celkový čas v % strávený čekáním na I/O;
Úzká hrdla omezující výkon MySQL
- Procesor – k nasycenosti CPU dochází v případě, kdy MySQL pracuje s daty, která se vejdou do paměti nebo je možné je načíst z disku tak rychle, jak jsou potřeba. Ve výstupech
vmstatse projevuje vysokou hodnotou ve sloupci us (čas trávený na vykonávání uživatelského kódu). Sloupec r (procesy čekající na CPU) bude většinou také nenulový, navíc bude zpravidla vysoká hodnota ve sloupci cs (přepínání kontextu). - Vstupně/výstupní operace – k nasycení I/O dochází tehdy, když potřebujeme pracovat s velkým množstvím dat, ale tato data se nevejdou do operační paměti, a proto je třeba je číst z disku (nebo se čeká na síť). Ve výstupu
vmstatlze tento případ identifikovat velkým množstvím procesů ve spánku (sloupec b) a vysokou hodnotou ve sloupci wa (čekání procesoru na I/O). - Paměť – jestliže dochází k swapování bloků paměti na disk, je to velký problém, který zásadním způsobem degraduje výkon celého systému. Pokud jsou sloupce si a so ve
vmstatnenulové, je třeba přidat operační paměť. Množství RAM se hodí zvýšit také v případě, že je limitujícím faktorem nasycené I/O (za předpokladu správně zkonfigurovaného serveru, kdy tuto paměť dokáže efektivně využít).
Jaké vybrat CPU pro databázový server?

Nyní, když již máme analyzovánu situaci ohledně slabého článku našeho systému, můžeme se pustit do vlastní výměny slabých komponent. Jak ale vybrat nejlepší procesor pro náš MySQL server? Je lepší investovat prostředky do rychlejšího CPU s méně jádry, nebo lépe použít slabší CPU s více jádry?
Obecně lze doporučit použití serverových procesorů namísto procesorů desktopových. Tyto procesory jsou optimalizovány pro serverové prostředí, mají zpravidla vetší velikost cache a dosahují daleko vyššího výkonu oproti procesorům používaným v běžných stolních počítačích.
Co se týká rychlosti či počtu jader, pak odpověď není zdaleka jednoznačná a záleží na pracovní zátěži konkrétního stroje. Stávající architektura MySQL má určité potíže se škálováním na více jader, neboť není možné nechat běžet jeden dotaz paralelně na několika CPU. Výhodnější proto bývá využití menšího počtu rychlejších CPU. Pomocí rychlejších CPU se sníží doba odezvy jednotlivých dotazů. Také replikace těží více z rychlejšího CPU než z více CPU. Rychlejší CPU bude znamenat také rychlejší uvolnění zámků řádků či tabulek, které mohou blokovat další operace.
Naopak větší množství procesorů je výhodné využít v případě, kdy na serveru běží velké množství databází a jestliže k serveru přistupuje větší množství klientů. Při takovémto scénáři bývají operace na sobě nezávislé a je výhodné použít vyšší počet CPU a zvýšit tak propustnost systému.
Problémy souběžnosti
- Logické – spadají sem soupeření o zdroje jako například tabulkové či řádkové zámky. Řešením je obvykle změna aplikace tak, aby byla schopna využít jiný úložný engine či použití jiné úrovně izolací databázových transakcí.
- Interní – soupeření o zdroje, kterými jsou semafory, přístup ke stránkám bufferovaným v InnoDB pool a jiné. Vyřešení problémů bývá složité. Je možné zkusit změnu nastavení serveru, změnit operační systém, použít jiný úložný engine nebo aplikovat speciální patche.
Pořizujeme více operační paměti
Jestliže máme ověřené, že námi použitý operační systém a instalovaný software pro databázový server podporuje využití více operační paměti, je výhodné paměť dokoupit. Více operační paměti je nutností zejména pro swapující stroje. Toto je věc, kterou u databázového serveru nikdy nebudeme chtít dopustit. Zvýšené množství paměti je výhodné také v případech nasycení I/O operací, neboť čím více informací můžeme umístit do operační paměti, tím méně se jich musí číst z pevného disku.
Na druhou stranu bychom se měli vyvarovat nějakého extrémního navyšování množství paměti, pokud nemáme odpovídající množství dat. Asi je hloupost mít systém se 32 GB RAM, když velikost celková velikost databází včetně indexů je 6,5 GB. V tomto případě je nejekonomičtější spokojit se s velikostí operační paměti 8 GB (v případě dedikovaného serveru).
Akademie ROOT pořádá školení „Návrh a používání MySQL databáze“. Školení proběhne 29. 9. 2010 v 10 hodin.
Naučte se používat jednu z nejrozšířenějších databází – MySQL. Na našem školení se dozvíte vše potřebné od návrhu až po samotné využití MySQL ve vašich projektech.
Optimalizujeme vstupně-výstupní operace
Pokud procesor místo vykonávání efektivní práce čeká na dokončení I/O operací, jedná se o poměrně zásadní záležitost, kterou bychom měli řešit. Rychlost jednotlivých úložišť značně vzrůstá směrem od procesoru k pevnému disku (registry → L1 cache → L2 cache → operační paměť → disk). Cena a velikost těchto pamětí pak probíhá podobnou křivkou, kdy nejrychlejší paměti jsou nejmenší a zároveň nejdražší a naproti tomu nejpomalejší paměti mají velkou kapacitu a jsou levné.
Databázové servery používají dva typy diskových I/O operací:
- Sekvenční I/O – data jsou v tomto případě umístěna sekvenčně za sebou, čtení probíhá postupně v sekvenci a nově přidaná data jsou zapisována vždy nakonec. Hlavy disku se v tomto případě nemusí přesouvat a nemusí se čekat na patřičné otočení disku.
- Nesekvenční I/O – data jsou umístěna náhodně po disku a není možné je číst sekvenčně. Hlavy disku musí neustále měnit polohu a musí se čekat na otočení ploten do příslušné pozice.
Sekvenční operace jsou poměrně rychlé a disk je schopen číst velké množství informací za sekundu (řádově desítky MB). Oproti tomu nesekvenční operace jsou velmi pomalé a databázové systémy musejí obvykle provádět indexové operace. Pro MySQL jsou indexy uloženy ve formě B-stromů. V důsledku propastného rozdílu mezi sekvenčními a nesekvenčními I/O, je daleko výhodnější cachovat data pro nesekvenční I/O, které jsou v operační paměti o 3 řády rychlejší.
Při upgradu pevných disků databázového serveru, je nejvýhodnější využít disků s co nejmenší přístupovou dobou, která bezprostředně ovlivňuje rychlost nesekvenčních I/O. Dalším důležitým faktorem je pak počet otáček za sekundu, které opět ovlivňují rychlost přístupu k datům nesekvenčním způsobem. Na velikost se budeme ohlížet v případě, že provozujeme datový sklad.
V závislosti na dostupných finančních prostředcích pro upgrade je výhodné použít větší počet pevných disků, které propojíme do pole RAID. Využití RAID zajišťuje zpravidla redundanci dat a rychlejší čtení a zápisy. Jednotlivé vlastnosti shrnuje následující tabulka.
|
Úroveň |
Vlastnosti |
Redundance |
Disky |
Rychlejší |
Rychlejší |
|
RAID 0 |
Levný, rychlý, nebezpečný |
Ne |
N |
Ano |
Ano |
|
RAID 1 |
Rychlé čtení, jednoduchý, bezpečný |
Ano |
Obvykle 2 |
Ano |
Ne |
|
RAID 5 |
Kompromis bezpečnosti, rychlosti a náklady |
Ano |
N + 1 |
Ano |
Ano/ne |
|
RAID 10 |
Drahý, rychlý, bezpečný |
Ano |
2N |
Ano |
Ano |
Tabulka 1. Vlastnosti diskových polí RAID
Využíváme cloud hostingové služby
Cloud hostingy jsou poměrně moderním trendem a velice zajímavou strategií, jak lze snadno a efektivně vyřešit otázku škálování výkonu dle aktuálních potřeb. Kvalitní cloudová řešení nabízejí možnost vlastní konfigurace virtuálního serveru, kdy si můžeme určit výpočetní výkon CPU, počet jader, množství operační paměti a velikost diskového prostoru.

Obr 3. Ilustrační obrázek pro Cloud computing
Dříve než se pro takovéto řešení rozhodneme, je dobré se na začátku seznámit s kompletní technologií daného cloud hostingu. Zjistit si, jaký hardware využívají, jak mají řešenu topologii, diskové úložiště a další věci. Nutno podotknout, že tyto služby jsou v České republice bohužel zatím v plenkách a oproti zahraničí není příliš z čeho vybírat. Analýza cloud hostintové situace ovšem přesahuje rámec tohoto textu, a proto ji nechme na nějaký příští článek.
Závěr
V dnešním článku jsme se seznámili s optimálním způsobem přístupu k upgradu databázového serveru. Uvedli jsme si nástroje, které je možné využít pro analýzu stavu serveru a sloužící k detekci slabého místa. Při upgradu procesoru jsme uvedli rozdíly mezi vhodností použití rychlejšího CPU oproti více pomalejším CPU. Pojednáno bylo o vlivu operační paměti vzhledem k I/O, typech diskových operací a diskových polích RAID, která lze využít při upgradu. Závěrem byla uvedena možnost využití cloud hostingových služeb, které se postupně prosazují a mohou být jednoduchým a efektivním způsobem pro vertikální škálování.
V příštím díle se podíváme na možnosti replikace, jejího nastavení a využití.
David Hübner
David Hübner pracuje na pozici vedoucího vývoje a projektového manažera ve společnosti eBRÁNA s.r.o.



„nicméně vlivem nedostatku RAM je nadále nutné neustálé čtení a zápisy z/na disk“ – zde by možnábylo dobré zdůraznit, že autor má na mysli swap, v případě disk cache to nedává smysl, PAE kernel může (AFAIK) použít „up to 64G“ paměti i pro cache.
U RAID0 (nebo jeho variant) pozor na stripe size, při malé velikosti roste sice teoretická rychlost čtení menších požadavků, ale pochopitelně roste i režie. Co víc, nastává daleko větší šance na rozdělení řádku mezi dvě odnože. Pokud se nějaká aplikace pokusí číst celý tento řádek, je potřeba seekovat na obou větvích. Daleko lepším řešením v případě 2 disků je (mimo heavy-write workloady) použít RAID1. Zvlášť na BSD, kde kernel umí i dynamicky „stripovat“ sekvenční čtení, je schopen zapisovat na jeden disk a číst z druhého (a uchovává jistou formu primitivních „transakcí“), oproti tomu mdadm hraje víc na striktní sync disků.
Jak bylo v článku zmíněno, velkou většinu času tráví server čekáním na I/O disku, je tedy na místě uvažovat o 10000+ RPM discích, případně SSD. Pochopitelně RAM je taky důležitá, na CPU mnohdy ani moc nezáleží. Většinu „zatížení“ procesoru stejně tvoří iowait.
Jestliže swapuje server na kterém běží dedikovaný SQL server, tak to neznamená nic jiného než špatnou konfiguraci databáze. tj. špatnou konfigurací db lze totálně zazdít výkon bez ohledu na hw a zatížení. Databáze musí být vždy nakonfigurována tak, že systém neswapuje!
Článek jsem pouze proletěl, ale spousta autorových tvrzení už na začátku článku není pravdivá, dál jsem se rozhodl to nečíst.
Pro efektivní provozování MySQL je nutné MySQL opatchovat (nebo používat vývojové verze) viz MySQL percona|facebook|google patch. Na druhou stranu, lidí, kteří by si na něco takového troufli a zároveň věděli, co dělají, tu moc nebude. Řešením je počkat si na novou verzi MySQL – snad brzy vyjde 5.5
Konkrétně Percona server lze stáhnout přímo na stránkách firmy viz. http://www.percona.com/software/percona-server/. Výkonově je tento server opravdu na daleko lepší úrovni než MySQL a až vyvíjená verze 5.5 stírá rozdíly. GA verze MySQL 5.5 by měla vyjít co nevidět, plánováno bylo v polovoně roku 2010. No snad bude vývoj pod Oraclem pokračovat i nadále tímto trendem.
A mě by zase zajímalo, jak je to s tím „daleko vyšším výkonem“ serverových CPU oproti desktopovým. Argumenty pro serv. jsou myslím jasný, ale šlo by to alespoň řádově nějak specifikovat?
Dejme tomu, že bych chtěl postavit MySQL server pro interní použití – nejde mi tedy o žádné „enterprise“ vlastnosti serverových komponent a 99.999% dostupnost, ale výhradně o poměr cena / výkon. Odpovídá cenový rozdíl alespoň přibližně rozdílu ve výkonu?
Samozřejmě, že i desktopový procesor v poměru cena/výkon může být dostačující. Bohužel k tomu, aby bylo možné přímo něco doporučit, tak by bylo třeba vědět bližší údaje o očekávané žátěži takového interního serveru.
V praxi jsou MySQL servery nasazovány pro vnitrofiremní účely běžně na desktopové stroje. Jak ale říkám, je potřeba znnát bližší údaje o předpokládané zátěži, požadované odezvě a mnoha dalších faktorech.
Každopádně ve firmě s řádově desítkami zaměstnanců si s tímto opravdu nemusíte asi lámat hlavu a můžete server nainstalovat na PC, které máte zrovna po ruce. Pokud výkon nebude dostačovat, upgradovat můžete vždy.
Celkem aktualizované benchmarky naleznete například na stránkách http://www.cpubenchmark.net/
Me ten clanek neprisel tak zly, pro laika lepsi nez nic
u vmstat je swap je popsan obracene:
si – počet bloků za sekundu swapovaných na disk,
so – počet bloků za sekundu swapovaných z disku;
tusim, ze je to naopak viz vypis:
0 4 537244 2319624 11260 266960 497 0 1390 55 510 768 5 3 0 92
0 6 536052 2310708 11528 268112 473 0 778 1415 527 476 2 4 2 93
0 6 534892 2297220 11868 271784 454 0 1215 70 542 574 4 2 0 94
jeste zkusim pridat nazvy sloupcu..
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 4 537244 2319624 11260 266960 497 0 1390 55 510 768 5 3 0 92
0 6 536052 2310708 11528 268112 473 0 778 1415 527 476 2 4 2 93
0 6 534892 2297220 11868 271784 454 0 1215 70 542 574 4 2 0 94
Tabulka RAIDu je trosku zvlastni. Rekl bych, ze RAID10 je pro databazi nejlepsi volba, ale take nejdrazsi. RAID5 a RAID6 maji super cteni, ale zapis byva slabsi. Slabsi zapis muze byt castecne eliminovan zalohovanou zapisovou kesi (+procesorem na pocitani parity). Slabsi zapis je zpusoben tim, ze pri zmene bloku je potreba nacist bloky ze vsech disku v RAID, vypocitat paritu a zapsat.
ono to bude ovlivnovat hodne faktoru – typ pole (raid), disky (scsi, sas, sp, dp, rpm – 7200, 10k, 15k), cache (bateryback write-back), pripojeni – interni nebo san (2Gb, 4Gb, 8Gb), dalsi vykonnost ovlivnuje napr. virtualizace pole (napr. HP EVA) atd atd atd
nemate tuseni, proc intel deli prociky pro small businesess na servery a datacentra a desktopy, pricemz kdyz je porovnate
http://www.czechcomputer.cz/product.jsp?artno=79307
http://www.czechcomputer.cz/product.jsp?artno=58003
tak jsou vpodstate stejny ? Je tam naky rozdil v necem ?