
Webdesign po deseti letech. Dělat weby je zase radost

Kudy se ubíral webdesign v uplynulých deseti letech a jak moc odlišně se tvoří weby dnes? Co podstatného se v průběhu posledních roků změnilo a jaké byly nejdůležitější technické mezníky na cestě, kterou se tvorba webových stránek do současnosti ubírala?
Nálepky:
S trochou nadhledu lze říct, že webdesignu coby samostatnému a specifickému oboru dnes o moc víc než těch deset let není. Jistě, weby se vytvářely už o pár let dřív, já sám jsem s nimi začal už někdy v roce 1996.
Byly to doby pionýrské, každý se učil za pochodu, všichni dělali všechno a nikdo nic pořádně. S dnešním profesionálním webdesignem s mnoha úzce vyhraněnými podobory se tehdejší situace nedá moc srovnat.
Přibližně před deseti lety už ale začalo být jasné i úplným laikům, že internet a potažmo web není žádná okrajová zábava pro pár technicistních nadšenců, ale plnohodnotné médium celosvětového významu. Web mezi sebe oficiálně přijala ostatní média a naplno jej do spárů uchopila komerční sféra: začala z něj ždímat, co se dalo, ale i vkládat do něj nereálné naděje a z plných plic nafukovat tu předimenzovanou bublinu (která s prásknutím splaskla hned o pár let později).
1998: Letmý start
V roce 1998 začíná většina uživatelů používat prohlížeče Netscape 4 (NN4) a hlavně v té době zcela nový, zgruntu přepsaný Internet Explorer 4 (IE4). Oba prvně implementují malou část nové technologie kaskádových stylů (CSS). Podpora se týkala hlavně vzhledu písma a barev, layout stránek nadále zajišťovala především struktura vnořených tabulek v HTML – jejichž chování byly ostatně podřízeny i první implementace CSS v prohlížečích.
Objevuje se i Opera 3.5, ovšem s implementací CSS postavenou na odlišném box modelu. Standardizační organizace W3C vydává revidovanou specifikaci CSS 1, postavenou zrovna na tom box modelu, který ani jeden z obou majoritních prohlížečů nepoužívá. Zde někde je počátek vší té nekompatibility a věčného dohadování, jestli je logičtější pojetí standardizátora nebo Microsoftu – nekompatibility, s níž se pomalu vypořádáváme teprve dnes.
Rok 1998 byl svým způsobem převratný hned v několika ohledech. Odstartovala spanilá jízda MS Internet Exploreru. Trapný až legrační paskvil IE3 byl nahrazen poměrně použitelným IE4, který měl každý uživatel Windows předinstalován v počítači, a který začal brutálně válcovat dosavadního hegemona Netscape. V témže roce Netscape zveřejňuje své zdrojové kódy – čímž nakopl projekt Mozilla – načež jej kupuje AOL, a zahajuje tak jeho dlouhý, pomalý pohřeb. Implementace JScriptu v IE4 dala smysl pojmu DHTML. Organizace W3C prezentovala připravovanou specifikaci DOM. Rok nato byl standardizován JavaScript v podobě ECMAScript-262. Započala několikaletá éra souboje akademických vizionářů a pragmatických praktiků.
Typický web v té době nejčastěji vzniká ve WYSIWYG editoru, typický je termín rozřezat: design stránky, nakreslený jako bitmapový obrázek, je „rozkrájen“ na systém obdélníků vyplňujících celou plochu stránky a převeden do jim odpovídajících, často i mnohonásobně vnořených HTML tabulek. Jednotlivé části designu pak tvoří pozadí buněk tabulky, jejich rámečky a většinou textový obsah těchto buněk. V rukou webdesignerů kraluje tehdy především báječný GoLive a začínající DreamWeaver (oba později koupené firmou Adobe a víceméně sloučené do jediného přeživšího produktu).
Kaskádové styly se používají převážně pouze pro určení vzhledu písma a barev pozadí a rámečků. S ohledem na chabou podporu stále ještě majoritního NN4 si o moc víc dovolit nemůžeme. JavaScript se používá na různé speciálky a malé webové aplikace, vnímané spíš coby něco extravagantního. Běžné handlery (mouseovery na tlačítkách, preloady obrázků apod.) řeší obvykle vestavěné funkce zmíněných editorů a webdesignery jejich kód pramálo zajímá. Prakticky každý skript začíná testem použitého browseru a jeho verze a pokračuje větvením kódu podle zjištěných hodnot. Schopnosti i interpretace stejných příkazů v jednotlivých prohlížečích se často diametrálně liší, společná řeč neexistuje.
2001: Kaskádová odyssea
Od přelomu tisíciletí začínají být neúnosně otravné stále rozevřenější nůžky mezi implementacemi webových technologií v hlavních prohlížečích. Zamýšlené standardy jako CSS a JS/DOM/ECMA se ovšem ukazují životaschopnými a mnohé vize nadšenců z W3C dávají smysl. Idea postupného sblížení jazyků HTML a XML, plynoucí z tehdy vydané specifikace jazyka XHTML někoho popuzovala, jiné – včetně mě – naopak lákala. Situace, kdy stávající kreativní, „blbuvzdorné“ parsery HTML byly schopné přeložit málem i první kapitolu Babičky a něco podle toho vykreslit, mi prostě přišla z principu špatná. Naopak jednoznačné, drakonické parsování XML, nepřipouštějící jakoukoli syntaktickou chybu, se jevilo jako čisté, logické řešení. Postupný, pomalý posun neurčitého HTML do světa striktně standardizovaného XML mohl být lékem na většinu neduhů stávajícího webdesignu a vymýtit všechny ty bolestivé nekompatibility mezi prohlížeči.
Na hlavní problém webdesignu té doby však ukazoval i sám trh. Klíčovým začalo být slovo sémantika. Bylo zřejmé, že webové stránky poskládané z mraků značek použitých bez ohledu na jejich původní význam, kód přeplněný daty týkajících se pouze vizuální podoby bez nějakého vztahu k významu a obsahu stránek, plné mnohonásobně vnořených tabulek, je nadmíru obtížné jakkoli dále zpracovávat. Mohli jsme si je pouze prohlédnout v prohlížeči, ideálně v tomtéž, který používal jejich autor.
Web narazil z jedné strany na bariéru a odpor zrakově a jinak postižených uživatelů neschopných sémantikyprosté weby používat, ze strany protější na marketing obtížně preparující z webů jejich podstatu, vyhledávače marně bloudící v nesrozumitelných shlucích kódu i provozovatele stále hůře schopné plnit do stránek obsah ve složitých konstrukcích předepsaných autorem šablony. Nemluvě o nad všechny meze bujících datových objemů: v té době bylo běžné, že HTML kód stránky měl i několik set kB, přičemž samotný obsah netvořil třeba ani 20 % (většinu kódu tvořily prezentační značky a tabulky) a problém vyznat se ve struktuře stránky mívali i sami autoři.

CSS Zen Garden. Legendární web ukazující sílu kaskádových stylů.
Stanuly tak proti sobě v jednom rohu ringu požadavky trhu (čistší sémantika, oddělení prezentační a obsahové složky webu, menší datové objemy, snadnější administrace) po boku s technologiemi, které to dokázaly zajistit (CSS2, JS/DOM), a novou generací prohlížečů, která je uměla jakž takž používat (IE6, macovský IE5, Mozilla a spol., nové verze Opery) – a proti nim celá generace zlenivělých webdesignerů s kudličkami dnem i nocí připravenými k rozřezání „zfotošopovaného“ designu a s pohodlnými tabulkotvornými WYSIWYG editory za zády.
Nastala doba intenzivní osvěty a mohutné evangelizace modernějších technologií a postupů. Objevily se desítky popularizačních webů a blogů. Nebylo týdne, aby někdo ve světě nepřišel s novým řešením a trikem, jak z CSS a aktuálně používaných prohlížečů vymáčknout maximum. Já osobně jsem nikdy předtím ani nikdy potom už nenapsal víc (a bohdá už nikdy napsat ani nebudu muset) evangelizačních článků a příspěvků. Objevily se weby, jako např. CSS Zen Garden, prakticky prokazující životaschopnost CSS a jejich možnosti více než nahradit stávající konstrukce. O mnoho postupů, které dnešním webdesignerům přijdou zcela běžné, logické a samozřejmé, se ještě před nějakými pěti sedmi lety vedly urputné spory a dlouhé, nekompromisní hádanice.
Jedním z podstatných nástrojů nového evangelia se stal validátor W3C. Pojem validní kód byl nejprve vodítkem, symbolickou kometou ukazující onu „lepší cestu“, aby se později (jak to tak bývá) stal pro mnohé jen samoúčelnou modlou, kterou vzývají, aniž by věděli proč, aniž by posuzovali, co z nevalidních konstrukcí je důležité a co nepodstatné. Pro zkušeného kodéra je validátor nadmíru užitečnou pomůckou, ale současně i dnes narážíme na „odborníky“, pro které je validní kód jen samoúčelná víra, kterou bezvýhradně vzývají, aniž by měli sebemenší ponětí o podstatě věci. Nicméně ono nepěkné rčení o účelech, které světí prostředky, tehdy fungovalo více než dobře.
2006: Dobojováno
Po přibližně třech až čtyřech letech usilovné osvěty i urputných sporů bylo přibližně v době kolem roku 2004 už možné považovat „boj“ za vyhraný. Výhody CSS se prosadily a tabulkové weby obhajovalo už jen pár dávno zapomenutých bloudů. Sémantický web výrazně ocenily vyhledávače: hlavně čím dál významnější Google, jednoznačně zvýhodňující weby se zřetelně strukturovaným a sémanticky označkovaným obsahem. Prakticky nikdo už v této době nepochybuje o tom, že oddělení vzhledu od obsahu je lepší a v mnoha ohledech výhodnější cesta. Odborníci nově vzniknuvšího oboru SEO začínají tyto postupy od webdesignerů aktivně vyžadovat a jejich marketingová úspěšnost je jednoznačným důkazem funkčnosti tohoto konceptu.
Končí také pětiletý faktický monopol MSIE, s nástupem Firefoxu a později Safari klesá postupně jeho extrémní a škodlivě nepřirozené zastoupení až na dnešní téměř vyrovnaný stav s ostatními prohlížeči, v určitých oblastech se stává dokonce prohlížečem minoritním. Weby postavené na proprietárních řešeních jediného typu vykreslovacího jádra přestávají být obhajitelné – standardizovaná a multiplatformní řešení začíná požadovat i trh.
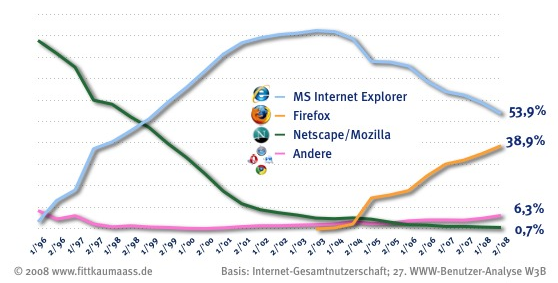
Podíl majoritních prohlížečů za posledních 12 let. Obrázek byl převzat z W3b.org.
Bohužel jedním z poražených, s čestnou mohylou u cesty, se ukázalo být ono slibné XHTML. Liknavost a neschopnost W3C (které si v posledních letech už už zadělalo i na vlastní ponurý hrobeček) mohou nejvíc za to, že se zamýšlené přiblížení k technologii XML nekonalo (jakkoli před pár lety trend vypadal poměrně jasně). Nereálný, nepraktický, odmítaný a vůbec vesměs nepovedený návrh XHTML 2 se k překvapení mnohých míjí na půl cesty se zcela novým návrhem standardu HTML 5, vynořivším se prakticky odnikud, připraveným mimo W3C komunitou WHATWG.
Ten nakonec W3C v posledním záchvěvu soudnosti a pudu sebezáchovy bere pod svá křídla a znovuzaložením pracovní skupiny pro HTML se vrací zpět ke kořenům. K budoucímu standardu HTML 5 se hlásí všichni důležití výrobci prohlížečů, včetně Microsoftu, který se návrhu specifikace aktivně účastní a jehož nový prohlížeč IE8 bude HTML 5 už částečně podporovat.
Použití jazyka XHTML tak dnes už téměř postrádá smysl, webdesign se vrací zpět k HTML 4 s předpokládanou budoucností právě na platformě HTML 5. Je to sice škoda, ale realita je zkrátka taková.
2009: Jak se dnes pracuje webdesignerům?
Život současného webdesignéra je z jednoho pohledu mnohem snazší, z druhé strany ale také o mnoho složitější – úměrně tomu, jak složité jsou weby a co všechno dokáží ve srovnání s těmi před pěti či dokonce deseti lety.

Spousta někdejších typických problémů, které nám kdysi bylo dnes a denně řešit, je historií. Budu teď chvíli mluvit čistě za sebe a ze své vlastní zkušenosti. Ať si kdo chce jak chce lamentuje, aktuální IE7 je pro mě již plnohodnotným moderním prohlížečem, který podporuje dostatečně dobře všechny důležité součásti CSS, funkce JS/DOM, PNG obrázky s alpha kanály atd. Je standardním prohlížečem, kde obvykle „na první dobrou“ funguje kód pracovně odladěný ve Firefoxu, a pro který už nemusím vyrábět obskurní obezličky a náhradní konstrukce obcházející známé bugy jako pro jeho předchůdce. Jistě, chce to mimo jiné i používat striktní DOCTYPE a dalekým obloukem se vyhýbat zlu jménem quirks mode – což ovšem po loňském přehoupnutí IE7 nad IE6 už není žádný problém.
Lépe než kdy dřív je dnes možné i vhodné starší verze IE oddělit od „zbytku světa“ (především pomocí podmíněných komentářů v HTML), v případě potřeby pro ně odladit samostatné styly a případně i skripty, bez nutnosti nějakých hacků a pofiderních triků. A pro zbytek prohlížečů – včetně IE7 – pak už připravím a vyladím jednotné, společné styly a skripty. Jistě, občas je potřeba pro některý z nich (každý má nadále své mouchy), upravit nějaký detail, ale v obecné rovině už IE7 nepovažuji ani zdaleka za tak problematický, jako byly jeho předchozí verze. Kvalitativní skok mezi IE6 a IE7 je z tohoto ohledu pro mě nebetyčný a srovnatelný snad jen s historickým rozdílem mezi IE3 a IE4 (pro ty, kdož to ještě pamatují).
Co se týče JavaScriptu, AJAXu a ostatních technologií DHTML, tady nám dnes skvěle slouží javascriptové frameworky (jQuery, Prototype, YUI atd.), u kterých musíme nade všechno zjednodušení práce a kódování ocenit především onu browser-independent vrstvu, jež nám zakrývá všechny odlišnosti a specifika jednotlivých prohlížečů a poskytuje jediný unifikovaný příkaz, který můžeme s klidem použít, aniž bychom se starali, jak bude v jednotlivých prohlížečích konkrétně interpretován.
Podpora JavaScriptu na straně klientů už vyšší být skoro nemůže a malé, rychlé knihovny nabízejí kromě DHTML i bezpočet prezentačních a formátovacích funkcí dosud v HTML prakticky nemyslitelných. Od přidání oblých rohů a umělých stínů bez potřeby zasahovat do zdrojových kódů, přes náhrady formulářových kontrolerů grafickými prvky až po plynulé animace všech akcí dějících se ve stránce: často stačí v HTML jen použít vhodnou třídu a nalinkovat do stránky správnou knihovnu. Všeobecně dostupné schopnosti AJAXu poskytují stránkám funkce, do té doby nemyslitelné, od nenápadných našeptávačů a validátorů po složité online aplikace (RIA).
Web se navíc otevírá: provozovatelé pochopili – přinejmenším ve světě, u nás zatím ještě většinou trochu zaspali dobu – jak moc se jim vyplatí své hotové řešení nabídnout uživatelům nejen na webové stránce, ale i vývojářům (ba i konkurenci!) v podobě serverového rozhraní (API) a umožnit ostatním části jejich vlastních aplikací provozovat kdekoli jinde. Protože už jen málokoho dnes zajímají fyzičtí návštěvníci jeho webu: daleko víc stojí o ty, kdo skutečně využijí jeho službu, koupí jeho produkt, zkonzumují reklamu, co prodává. A je jedno, na jakém webu tak dotyčný učiní, hlavní je, když užitečné API přivede zákazníka k cílovému produktu.
Díky tomu existují stovky skutečně špičkových profesionálních řešení, které kdokoli může snadno umístit do vlastní stránky a využít práci jiných pro vlastní potřebu. Synergickým efektem z toho nakonec mají užitek všechny zúčastněné strany. A my webdesigneři několika kliknutími myši můžeme vytvořit ve stránce prvky, které by dříve vyžadovaly profesionální vývojářský tým a mnoho měsíců intenzivní práce.
Nová situace má ovšem za následek i nový styl webdesignerské práce. Zatímco před těmi deseti lety všichni dělali všechno a běžný webdesigner vám vystřihl web od grafického návrhu po CGI skripty na serveru, dnes našemu oboru vládne čím dál užší specializace. Moderní web vyžaduje kvalitního analytika, informačního architekta, grafika, programátora serverové části, kodéra, programátora klientských skriptů, specialistu na SEO, odborníka na marketing, dobrého copywritera a případně i další obory – což už dnes na špičkové úrovni jen těžko dokáže zvládnout jediný člověk. Web menšího rozsahu jeden webdesigner pochopitelně vytvoří sám i dneska, ale jen proto, že některé z jeho složek vynechá nebo nějak „ošulí“. Ale středně velký web je dnes již nemyslitelný bez účasti kompletního týmu specialistů na jednotlivé obory, případně outsourcování na specialisty.
Dnešní webdesign: Nikdy předtím to nešlo lépe
Při naprosté soudnosti a s plnou zodpovědností si troufám tvrdit, že dnes již je možné – na rozdíl od situace ještě před pár lety a patrně poprvé v historii webdesignu – na webu vytvořit prakticky cokoli.
Můžeme nastylovat prakticky jakýkoli vzhled, který si grafici vymyslí. Krom základních omezení webu coby technologie již žádný design stránek nepovažuji za nemožný a nerealizovatelný. Jistě, jsou stále konstrukce, které nejsou proveditelné přímo prostředky HTML, ale ty lze řešit zase jinými cestami (barevné přechody proměnlivé výšky lze generovat dynamicky na serveru, požadované netypické fonty lze zajistit třeba pomocí sIFR, chybějící chování či služby browseru lze doplnit naprogramováním vhodného skriptu atd.). Nestandardní požadavky zákazníků se z kategorie „tohle nejde udělat, protože…“ čím díl častěji přesouvají do kategorie „tohle ovšem bude o XY dražší, protože…“.
Osobně pociťuji velkou radost z toho, co dnešní web dokáže, a občas až fyzické nadšení z moci nad technologiemi, pomocí nichž poměrně snadno a rychle vytvářím věci, které bych ještě před pár lety po právu prohlásil za nemožné a nerealizovatelné.
Nicméně hlavní a zcela zásadní pro dnešního webdesignera je především jedna věc. Uvědomit si, že (a jak) se věci každým dnem mění, a že to, co platilo včera, vůbec nemusí platit zítra. Kdoví, jestli to ještě platí dnes. A potažmo se tomu umět neustále průběžně přizpůsobovat.
Ten, kdo dnes umí dělat weby pouze tak, jako se dělaly před pěti (nedejbože před deseti) lety, kdo se vyhýbá moderním technologiím, odmítá sdílet a používat serverová API, AJAX, DHTML, javascriptové či serverové frameworky, kdo si myslí, že webové stránky se dělí jen na dvou- a třísloupcové, kdo se tvrdošíjně snaží mít weby stejné současně v moderních i zastaralých prohlížečích – takoví webdesigneři nemají moc šancí na přežití. Dnešní zákazníci jsou jen krůček od toho, aby to sami pochopili. Ale profesionální webdesigner musí být před nimi napřed o pěkných pár kroků.
Trh nikoho nepředběhne. Zašlápne ho.
Autor článku je webový designer a vývojář na volné noze. V poslední době se specializuje na programování online aplikací, JavaScript, AJAX a moderní dynamické weby. Kromě toho se zabývá návrhy uživatelských rozhraní, jejich použitelností, přístupností a hrou na mnohé nástroje.
Petr Staníček
Autor je návrhář UI/UX, analytik, grafik, javascriptový vývojář a advocatus diaboli ex offo.



Moc hezký rozbor toho, jakou dlouhou cestu web během let ušel. Velké díky Pixymu za napsání a Martinovi za vydání.
Když je XHTML mrtvé, tak jak budeme zapisovat na webových stránkách vzorce a vektorovou grafiku? Nebo se snad v HTML5 chystá možnost vkládání MathML a SVG stejně jednoduše, jako v XHTML?
To je záležitost prohlížečů. Jeden pomězně málo známý prohlížeč to zvládne, v aktuální verzi 11 jsem ověřil zobrazení takto vloženého SVG obrázku, že to jde jsem se nedávno dočetl od Chamurappiho.
Opera a Webkit a výše zmíněný prohlížeč umí i školácky jednoduchou konstrukci <img src=obrazek.svg>, prohlížeči Opera "chutná" SVG i v CSS jako backgound nebo list-style-image.
Ano, ale do XHTML jde vkládat SVG rovnou do stránky díky jmenným prostorům – ne jen jako odkaz na externí dokument. Totéž ta matematika.
Nebo se snad v HTML5 chystá možnost vkládání MathML a SVG stejně jednoduše, jako v XHTML?
Ano, autoři HTML5 ve spolupráci s tvůrci MathML a SVG o něčem podobném uvažují, ale zda najdou nějakou schůdnou cestu, zatím těžko říct.
Ono SVG je už dost dobře podporované i dneska a knihovny jako OpenLayers (viz příklad) s tím počítají. Na IE to zatím funguje přes obezličku VML, ale ohlašovaný IE9 by to měl (konečně) změnit.
Bude to nejspíš úplně stejně, jako u současného HTML. Použije se tam něco velmi podobného XML, co se bude lišit jen v některých okrajových detailech — tak, aby to znemožnilo pracovat s tím jako s XML. Vzor si můžeme vzít ve jmenných prostorech v HTML, které na tomhle principu fungují. Hlavně že odpůrci XML budou spokojeni, že "uhájili" HTML.
vzorce vkladaji do stranek jenom smradlavy matfyzaci, to nikoho nezajima ….
Bejt tebou, tak bych do matfyzáků moc nerejpal. Mohlo by se ti stát, že budeš do konce života počítat na abakusu a psát na psacim stroji. ;-)
Smradlaví matfyzáci používají TEX, XHTML + MathML by využila Wikipedia.
HTML5 má dva způsoby serializace — HTML a XML. Takže pokud potřebujete vkládat fragmenty XML do HTML5 dokumentů, můžete použít XML serializaci (někdy se jí také říká XHTML5).
Navíc se pracuje na tom, aby se práve MathML a SVG dalo přímo vkládat i v HTML syntaxi. Ale jak to nakonec dopadne, není úplně jasné.
Nechcem Vam brat to nadsenie ale ja teda taky "radostny pocit" z toho nemam.Stale je dost IE6 na trhu, ale s tym sa nic nenarobi to chce cas.Frameworky na strane serveru su bud prehnane mohutne alebo su to len hlupe kniznice kde vsetko treba to toho zlozito narvat.Dnesne az nebezpecne nadsenie nad Javascriptom ma zaraza.Jednak frameworky (pripadne aj s gui/grafikou) ktore su strasne rozsiahle (Extjs a pod) ktore sa ale zle ohybaju/upravuju takze paradoxne sa hodia na jednoucelove veci, alebo potom ostatne ako jquery a pod. kde aj tak treba vecsinu veci si doroboti.Ostatne mam pocit ze pre vecsie projekty sa aj tak oplati naspisat si vsetko sam na mieru.A tiez vykonnostna nenazranost javascriptu s domom je nechutna.Dalej z predchadzajuceho boja o standardy sa teraz stava zasa boj o rychlejsi jscriptovy interpreter google vs mozilla.Ako tak pouzitelny je flex a silverlight ale ani to neni ono.No a prave tej vasej vety ze je mozne spravit hocijaky design mam strach.Dost ludi si to vyklada ze nie len design je mozne spravit hocijaky ale aj rovno aplikaciu.Priznam sa nechapem preco sa tlaci office na web, bitmapove editory na web a dalsie aplikacie.Uz beztak je dost humus ze na desktope zacina vladnut ten podivne interpretovany kod (java/.net).
Zaver je skor ze sa web akurat tak viac znasilnuje.
Souhlas, velmi dobře popsáno. Až na tu poznámku "java/.net" – ty už jsou tak daleko, že co do rychlosti jsou skoro na úrovni nativního kódu (s pamětí už je to horší, ale koho to trápí).
no s tou vykonnostou je to vzdy problem ale fakt pri beznych aplikaciach je to asi jedno,budu to nejake jednotku percent.To pomalsie startovanie a vyssia pametova narocnost "java/.netu" to sa este da zvladnut, ale fakt netusim ake plusy to ma pre dnesny sw.Interportabilita pri jave skoncila a je to len fikcia a .net ani s niecim takym neratal.Jazyky su to dobre (java,c#), objektovy model a rozsah kniznic to vsetko beriem ale preco to nemoze byt kompilovany kod ? A vyhody typu ze je to bezpecnejsie a aplikacia bezi v sandboxe su blbost.Bezpecnost sa da dosiahnut aj beznymi prostriedkami os a dovolim si tvrdit ze 90% beznych uzivatelov na desktope ani netusi kde si moze nastavit napriklad parametre pre .net app.
A co sa tyka vykonnosti tak si skuste povedzme v MS SQL management studio zobrazit nejaku vecsiu tabulku v gride.Len skrolovanie je otrasne aj na dual masine.Cele je to napisane v .NETe.Pritom hocijaky sql klient ktory je klasicky kompilovany a nepouziva .net je v pohode.
Tak si ty javovský zdrojáky kompiluj. Kompilátory do strojového kódu existují.
1) Kompilovana java do nativu je pomalejsi.
2) Pametovan nenazranost javy je dost znacna a kdyz budete mit na pocitaci podobne komplexni aplikaci jako Office v Java zjistite ze si k tomu uz ani ten prohlizec skoro nepustite.
ad 1] To byla trochu sarkastická reakce na to, že přispěvovatel výše z nějakého důvodu baží po kompilaci do nativním kódu. Tu možnost má :) Výhody/nevýhody musí zvážit sám.
ad 2] Bohužel paměťová nenažranost nejen javy je dost značná :-/ Příkladem budiž firefox v c/c++. Spíš jde o to, jak je daný SW udělanej. Program v java může být klidně paměťově velmi úsporný. Ne že by to bylo pravidlo :)
Pripajam sa k tomuto nazoru. U nas je realita taka, ze 90% browserov je IE6 (+WinXP). Internetova apliakcia, okolo 4000 prihlasenych userov, okolo 12000 zaregistrovanych. AJAX / Javascript len sity namieru, dolezity je aj security audit. CSS ma tiez svoje hranice.
Ja by som skor povedal, ze to nie je ani horsie ani lepsie, ako to bolo. Resp. od cias "gopher na vax terminale" je to stale komplikovanejsie – miesto obsahu sa viac dba na formu. Chapem, z eniekedy je to nevyhnutne, ale preco uplne vzdy? Nasi uzivatelia potrebuju informacie hlavne rychlo, a len patricne mnozstvo. Vsetko naviac povazuju za obtazovanie. A animovane posuvanie okien je sice pekny marketingovy tah, ale neuveritelne otravujuci – nas manager to vola iphone efekt, a cpe to vsade. a mna ide z toho drbnut, lebo na jeho quad core super-duper compe to vyzera OK, ale pracovnici v terene s netbookmi sa z toho mozu aj to….
V tom případě to spíše vypadá, že vás "lokálně" panují podmínky, které na celém Webu byly možná tak před 5 lety. Patrně nebudete jediný, takových ostrůvků, zej. na intranetech, se v ČR najde určitě víc, ale rozhodně to není obvyklá situace na celém Webu (ani na celém Webu v ČR).
No na prvy pohlad to tak mozno vyzera. Ale prax je taka, ze strasne vela klientov si velmi oblubilo netbooky. A atom N270 sa jednoducho vykonnostne neda porovnavat s dual core CPU. Vista tiez nie je oblubena na netbookoch (preto aj IE6). Casto sa browsuje mobilne, UMTS nie je vsade, tak sa ide cez GPRS. Teda musime optimalizovat na rychlost a prehladnost. Samozrejme vyuzivame AJAX, XML, JavaScript, CSS (WEB2.0 ako by povedal moj manager :) ) ale nemoze sa to robit na ukor funkcionality a rychlosti. Samozrejme ma AJAX zmysel, napr. na zobrazenie zakladnych udajov, a na pozadi sa stahuju zvysne udaje. Ale nejake animacne efekty (ako som vyssie spominal napr. "iPhone efekt") sme nastastie museli killnut ;)
A na netbook s XP se nedá nainstalovat Firefox, Opera, Chrome, Konqueror, Safari a nebo třeba i IE7 a IE8 (až bude)? Proč by tam měl být nutně IE6, který má 10x pomalejší zpracování Javascriptu než ostatní prohlížeče?
Jasne ze sa da, preco by sa nemalo dat?
No tak kde je potom ten problém s netbooky? Pokud tam je dobrý prohlížeč, tak s JavaScriptem, CSS a AJAXem není žádný problém. Atom procesor na to celkem v pohodě stačí, samozřejmě si uživatel počká chvilku dýl než na dvoujádrovém stolním PC. Ale s tím snad uživatel počítá, když si pořídí levný minipočítač.
Specialne se "nebezpecne nadseni z javascriptu" projevuje jeho pouzivanim i tam, kde vubec neni potreba (neni problem narazit na stranku, ktera bez js nefunguje, protoze js otevira treba popupy s obrazky a obycejny href k obrazku chybi).
Ma to i bezpecnostni dusledky – velka cast security advisories k prohlizecum vyzaduje zapnuty js k exploitaci (typicky "heap spraying" aby se spustil kod).
Proč se tlačí kancelářské aplikace a další na web? No já osobně jsem na to čekal celý život – nechci trávit čas instalací, nastavováním a údržbou SW pokaždé, když si koupím nový počítač, telefon, atd. Chci spustit prohlížeč a být ve stavu, kde jsem byl předtím na jiném (starém, cizím…) stroji. Zaplaťpánbůh za Google apps, acrobat.com, atd. atd.
Copak, my ještě žijeme v době HTML 3 a 256 MB RAM?
A .NET není intepretovaný, chytrolíne. Tam je JIT kompilace, bytekód se poprvé zkompiluje rovnou do nativního kódu a tak už ZŮSTANE. A frameworky na straně serveru jsou přehnaně mohutné? Možná v tom poťapaným amatérským PHP, ale ASP.NET, to používat je radost. Pokud už si dodávám nějakou 3rd party komponentu nebo třeba třídy pro práci s nějakým API, všude jsou to jenom zkompilované knihovny DLL.
Pri jeho cteni me nostalgie, kdyz jsem si vzpomnel jak jsem placal svuj prvni web v GoLive :-) Tuto zkusenost jsem uz davno vytesnil z hlavy.
Jistě, chce to mimo jiné i používat striktní DOCTYPE a dalekým obloukem se vyhýbat zlu jménem quirks mode…
To má nějakou souvislost? Můžu využívat výhod standardního vykreslovacího režimu MSIE a současně namísto ořezané verze HTML mohu používat plnou verzi, skromně nazvanou Transitional.
Díky za výborný článek, budu jej odkazovat fňukajícím začátečníkům.
V MSIE ano (pokud ovšem použijete DOCTYPE včetně URL). Ale Transitional HTML 4 se nevykresluje zcela striktně v Gecku. Ano, tam to sice není "quirks mode", ale takový ten hybrid "almost/pseudo standard mode", což taky není ideální. Viz ten link v článku příp. http://wellstyled.com/html-doctype-and-browser-mode.html
Osobně ale dnes nevidím k použití Transitional DOCTYPE smysluplný důvod. Vy ano? K čemu to může být dobré, zajímalo by mě to. Dík.
napr. mozes pouzivat element menu, striktny dtd ti umozni len semanticky nespravny element ul.
„ale takový ten hybrid „almost/pseudo standard mode“, což taky není ideální.“
V čem přesně to není ideální? To kvůli těm cca dvěma rozdílům oproti standardnímu režimu, které kodér stejně musí ošetřovat i v Exploreru? Tobě záleží na tom, jestli máš exkluzivně v Mozille pod obrázkem místo na nožičky? Člověk, který si nepřečte, že skoro-standardní režim existuje, se o jeho existenci pravděpodobně nikdy nedozví.
„Osobně ale dnes nevidím k použití Transitional DOCTYPE smysluplný důvod.“
Někdo třeba chce mít validní stránku a zároveň používat <menu>, číslovat si jinak <ol> nebo směrovat výsledek formuláře do <iframu>. Viz můj článek.
Pokud HTML 5 na něco navazuje, tak na HTML 4.01 Transitional. Nikoliv na Strict. Jaký máš smysluplný důvod k použití Strictu?
Já používám Strict a žádné dva rozdíly nikde neošetřuju. Což je odpověď i na ten dotaz: Strict používám především proto, že mi zaručuje maximálně shodné chování všech prohlížečů.
A víš co? Ty můžeš svobodně používat Transitional a já zase Strict, nikomu to nevadí a všichni jsme spokojeni.
Jak se to vezme. Na drakoničnost nebyl nový jazyk vůbec potřeba,
drakonicky se dalo parsovat i HTML (myslím „HTML“, tj. standardizované
HTML, nikoliv tag soup). Nicméně i ve světě XML se brzy ukázalo, že
drakonický přístup nelze ustát – např. uživatelé chtěli RSS čtečky,
které fungují a nehlásí parse-error, byť chyba byla na straně nevalidního
RSS feedu. Takže se i obdoby HTML prohlížeču, tedy RSS čtečky, naučily
parsovat kapitoly z Babičky. A historie se opakuje, jen tu máme zbytečně
dva jazyky.
XHTML bylo významné spíš z hlediska osvětového, než technického.
Přikládám takovou historickou poznámku pro všechny, kdo se zamýšlí na tím, kdy, proč a jak se ona volnost do HTML dostala:
Bylo to hned na začátku – v prvním webovém prohlížeči na světě WorldWideWeb od TBL. Co si na ty jeho zdrojáky ještě pamatuji, tak jeho HTML parser měl nějakých slabých 2-3 tisíce řádek a hlídal si hlavně počáteční značky, tj. ani se nezajímal o to, na jakou koncovou značku právě narazil – když na nějakou takovou značku narazil, jednoduše ukončil poslední otevřenou HTML značku, co měl (tj. neměl v tomhle místě žádnou kontrolu na překřížené značky, byl to jednoduchý zásobník – o úroveň dovnitř, o úroveň ven). V tehdejším jednoduchém HTML (nějakých 20 značek) tenhle primitivní nějak fungoval.
Hlavní ovšem je, že TENKRÁT TO VŮBEC NEVADILO, protože webový prohlížeč WorldWideWeb byl zároveň WYSIWYG editorem HTML. A tak to mělo podle návrhu TBL také zůstat na věky. Tvůrci webových stránek měli používat tento editor a neměli s HTML značkami vůbec přijít do styku (jazyk HTML tedy nebyl primárně navržen, aby jej používali lidé, nýbrž stroje!). A jelikož WYSIWYG editor tvořil stránky bezchybně, bylo vlastně šumafuk, zda budou parsované drakonicky nebo ne.
Jak sami víte, tohle TBL příliš nevyšlo. Snad žádný další webový prohlížeče té doby (a že jich vznikly během pár let asi dvě desítky) neobsahovat WYSIWYG editor. A ukázalo se, že autoři webů docela ochotně ručně píší "ty divné značky v lomených závorkách". Tady nastal problém, protože tady se začaly do HTML dokumentů vkrádat chyby jedna za druhou. Jenže ty další prohlížeče zřejmě na volné parsování HTML prostě navázaly (tuhle oblast nemám pořádně prozkoumanou, ještě jsem ty všechny jejich parsery neprošel) a bylo to hotovo, již se nedalo vycouvat.
Tenhle mezník, kdy se z HTML coby jazyka psaného stroji stal jazyk psaný lidmi, je tím klíčovým momentem, který se nedokázal podchytit. TBL se o to snažil, ale možná jinak, než si myslíte – snažil se přesvědčit ostatní prohlížeče, aby to udělaly podle něj a také implementovali WYSIWYG editory. Marně. Kdyby se je tenkrát místo toho snažil přesvědčit, aby začaly parsovat HTML striktně, možná by uspěl a celá historie HTML by byla jinak.
Otázka zní, zda právě tohle, zda právě tenhle "omyl" nepřispěl k rychlému a masivnímu rozšíření HTML. Já si myslím, že ano, ovšem přesvědčit se o tom nemůžeme, takže nám tu zbudou jen věčné dohady, zda by to s tím přísným přístupem hned od začátku třeba náhodou nedopadlo stejně nebo třeba taky mnohem líp.
Kdysi jsem se o tom trochu zmiňoval na Lupě http://www.lupa.cz/clanky/mate-tam-chybu-time/
koho zajimaji prakticke duvody: http://www.ericsink.com/Browser_Wars.html , vice v stackoverflow podcastu.
podla mojho skromneho nazoru je skor problem ten ze z HTML,volne prelozene jazyk na popisovanie/ukladanie hypertextu, sa stalo nieco co ma byt nejaky aplikacno datovy popis/api/platforma.Web mal zostat tym cim bol – ukadanie dokumentov a textu.To co sa teraz deje to je zverstvo.
A co sa tyka kvality kodu, stacilo by drasticke opatrenie keby browseri nekorektnu stranku proste nezobrazili.Autori stranok by museli danu webu opravit aby bola validna a funkcna.
stacilo by drasticke opatrenie keby browseri nekorektnu stranku proste nezobrazili
Něco takového je dnes u HTML nemožné. Chyba, kterou jsem popisoval, nastala počátkem 90. let a tehdy se skutečně dala vyřešit. Dnes už je pozdě a stávajíc stav potrvá tak dlouho, dokud potrvá Web.
Pořád se xhtml parsuje řádově líp než jakýkoliv html, i 5 samozřejmě. Takže xhtml 1.0 strict budu používat nadále pro projekty, kde je parsování výsledku alfa omega, a kravinky typových inputů ve formuláři nepotřebuju.
Ano, to je velmi oblíbený argument pramenící z neznalosti, na který obvykle odpovídám dotazem: dokáže tohle váš parser?
To jsme si nerozumněli. Já mám naprostou kontrolu na tim, jak bude vypadat výstup, neparsuju cizí výstupy, a tím pádem mám parser postavenej tak, že stačí, že umí to, co mu předložim, a nemusí umět takovýhle čuňárny.
*nerozuměli
Takový argument je nezávislý na formátu. Říkáš, že umíš pohodlně rozebrat to, co si sám sestavíš. Já si také hravě přečtu své nevalidní HTML a mému parseru se také řádově lépe žvýká HTML než jiné formáty.
Prakticky vzato ale málokterý webmaster potřebuje rozebírat výsledný produkt, který servíruje návštěvníkům. Kódy baští hlavně prohlížeč, a proto by formát měl být v symbióze především s ním.
FF3 to jako xhtml bere, jako html ne, takže mi to připadá že to zní spíš ve prospěch xhtml?
ano, dokáže
Ale to je přece opačný případ. To co v prohlížeči zpracovává XHTML stránky není plnohodnotný XML parser. O tom není pochyb. Pointa je v tom, že XHTML stránku napsanou pro prohlížeč (tzn. v té chudé podmnožině XML, kterou prohlížeče správně zpracují) je schopen zpracovat každý XML parser. V základu PHP je jich několik s různým rozhraním, v Javě nepočítaně, v C++, v Pythnou, Perlu, … prostě tu stránku načtu a zpracuji, ať už používám cokoliv. Naopak HTML parser mimo prohlížeč, který z 'tag soap' vyrobí korektní DOM nebo jeho obdobu, aby hledal s lupou. A to už nemluvím o možnosti použít na takovou stránku třeba xsltproc nebo ji přímo nahrát do XML databáze. Možná je automatické zpracování HTML už za horizontem pro běžného webdesignéra, pro kterého svět končí prohlížečem. Ale mě jako programátorovi, který tohle musí řešit, pohaslo vznikem HTML5 veliké světlo naděje.
Velmi striktní parsování XHTML je hloupost. Může fungovat pouze v ideálním světě, kde prohlížeč XHTML kódu je bezchybný. Ale jak známo, vše, co je dílem člověka může obsahovat chyby, na které vývojáři nepřijdou, ale několika uživatelům se objeví. Zvlášť velká slabina XHTML prohlížečů je to, že mají předepsány situace, ve kterých mají selhat (čili ukončit zpracování stránky a zobrazit chybu) a ve kterých ne. To je z hlediska uživatelů nesmysl, neboť je nezajímají chyby, je zajímá obsah. Takže XML funguje pouze v případě kombinace bezchybný prohlížeč + bezchybně napsaný kód. Bezchybně napsaný kód lze možná zaručit, bezchybně napsaný prohlížeč nikoliv.
Existuje ještě jeden silný důkaz o neúspěšnosti XHTML. Podstatná většina stránek, které i přesto, že jsou napsány v XHTML jsou odesílány s Content-type: text/html , místo toho aby byly odesílány s Content-type: text/xml , Content-type: application/html+xml či nějakým jiným, který označuje, že jde o XML, aby se obešla kontrola správnosti sestavení XML.
Dovolím si tvrdit, že ani jeden z prohlížečů nezpracovavá XHTML podle XML specifikace, možná kromě prohlížeče Amaya. Ostatní buď neselhávají v situacích, kdy by selhávat měly, nebo selhávají v situacích, kdy by selhávat neměli.
Jako text/html se neposílají kvůli obejití správnosti, autoři kteří mají opravdu stránky v xhtml, by je velmi rádi i poslali jako xhtml, ale nedělají to kvůli jedné jediné chybě v MS IE a jeho quirks mode :) Kvůli MS IE tudíž nemohou posílat xhtml, ale zbývá jen staré "dobré" html. Nebýt IE, bylo by to nejspíš jinak. Pokud nebylo, pak teprve by šlo hovořit o nějakém důkazu.
To si nemyslím. Plno webů posílalo XHTML jako "opravdové" XHTML alespoň Firefoxu (A obecně prohlížečům, které to zvládaly), ale už tak nedělají. Za všechny třeba http://www.w3.org :-).
presne tak
Jestli to nebude tak, že pečlivý správce nastavil XHTML a pro IE výjimku, a pak přišla lama a celý mu to „zaktualizovala“.
Tohle jsem taky řešil a vyřešil jsem to tak, že mám engine, který podle Accept hlavičky vrátí buď XHTML s Content-Type application/xhtml+xml nebo text/xml nebo HTML s Content-Type text/html. Ono totiž posílat XHTML jako text/html je dost rozšířená prasárna.
Velmi striktní parsování C++ je hloupost. Může fungovat pouze v ideálním světě, kde komilátor C++ kódu je bezchybný. Ale jak známo, vše, co je dílem člověka může obsahovat chyby, na které vývojáři nepřijdou, ale několika uživatelům se objeví. Zvlášť velká slabina C++ kompilátorů je to, že mají předepsány situace, ve kterých mají selhat (čili ukončit komilaci kódu a zobrazit chybu) a ve kterých ne. To je z hlediska uživatelů nesmysl, neboť je nezajímají chyby, je zajímá aby to "nějak jelo". Takže C++ funguje pouze v případě kombinace bezchybný komilátor + bezchybně napsaný kód.
Není to odověď na otázku, proč i Franta vod vedle, kterej na základce 3x propadl je dnes Top Web Designer?
Proč tento argument nefunguje vlastně dokonale vystihuje rozdíl mezi programovacím a značkovacím prezentačním jazykem. Všimněte si, že společně s HTML se vyvíjel i JavaScript, obojí vždy v jednom prohlížeči, a zatímco u JavaScriptu je jakákoliv chyba v kódu fatální, u HTML se toleruje.
HTML totiž spíš než k programovacímu jazyku můžeme přirovnat k bitmapovému obrázku. Pokud se v JPEG objeví chyba, je obvykle lepší, pokud jej dokáže prohlížeč alespoň nějak zrekonstruovat (ať už web browser nebo bitmap editor), třeba s upozorněním, než zcela odmítnout.
U programovacích jazyků je tomu právě naopak.
Přičemž i XML může vystupovat v opačné úloze, než která platí pro XHTML nebo RSS. Například u API webové služby, které komunikuje v nějaké aplikaci XML, je záhodno netolerovat žádnou odchylku.
Máš pravdu. Já bych HTML jen spíš přirovnal k formátům pro uchovávání informace jako je PDF nebo takový ty palmbooky. Vůbec mě nezajímá, zda a kolik chyb se v takovém souboru nachází. Chci, aby z něj čtečka dostala maximum, co dokáže.
Pixy se musel na stará kolena dočista pomátnout! Jestli opravdu na stránky vkládá složité prvky jedním klikem a pak mu všechno na první pokud funguje v celé škále IE, FF a dalších, tak to mu gratuluji!
Moje praxe je jiná. IE7 má bugy, o kterých se nám dříve ani nezdálo, na trhu je dále IE8 a s nezanedbatelným podílem i IE6 (dvacet procent!!) a složité prvky se musí složitě naprogramovat. Řady obskurních prohlížečů se nazenedbatelně rozrostly (iPhone, Android, Safari) a testování zabírá nejvíce času.
Radost to není ani omylem. To by musel být člověk masochista.
Ty beres jeho nazory vazne? To teda koukam.
Soudě podle ankety s autorem (do nějaké míry) souhlasí nějakých 80% čtenářů, což mě osobně velmi těší a doufám, že to také na českém webdesignu bude znát.
Anketa je poněkud neštastná; už z principu vývoje by mělo být stále lépe.
Pokud by však v anketě byla odpověd "je to dobré", málokdo by na ni asi klikl.
Jenže už z "principu vývoje" to dostatečně dobré není nikdy.
presne tak
Přesně tak. Dělat weby je radost jenom tehdy, když od toho zase tak moc nechcete nebo si můžete dovolit ignorovat IE7.
Období veselého ignorování IE mi bohužel před pár týdny skončilo, a není snad dne, abych si nerval vlasy na hlavě z toho, jak postupně (znovu-)zjištuju, co všechno v tom zaflusanym bastlu nechodí, jak by mělo (i jak by mělo dle MS)…
Dnes:
1) css-hack pro transparent PNG v IE6 – odkaz na pseudo-obrázku nefunguje v místech, kde je obrázek neprůhledný
2) IE7 bez css-hacku – kolem neprůhledné oblasti je "glow"
Takže hlavně v IE to je "Pořád něco ku*va!!!" :(
ja myslim, ze IE7 je jeste hodne spatny, ale IE8 uz dela presne to co ocekavam!
toto je uzasny renderovaci engine implementovany v PHP!!! http://freshmeat.net/projects/html2ps_php/
Bohuzial, zakaznici to chapu davno a prave kvoli nim sa vsetky tie nezmyselne komplikovane stranky navrhuju (a technologie vznikaju). Niet nad jednoduchy layout bez zbytocnosti, ktore len stazuju v tej spleti slov a obrazkov najst informaciu, ktoru clovek hlada. Ja ako zakaznik chcem cistotu a informacnu hodnotu a prehladnost. Ostatne je balast, ktoreho je cim dalej viac.
Co sa tyka prinosnosti novych technologii na webe, presvedcilo by ma nieco taketo: Napisem nativnu aplikaciu pre operacny system XY (pomocou nastrojov a s vyuzitim API, ktore su na to urcene). Chcem nastroj, ktory mi aplikaciu umozni spustat v prehliadaci (t.j. ako webaplikaciu) bez toho aby som aplikaciu nanovo rucne vytvaral v kombinacii htmo, javascript, ajax, …. A take nic zatial neexistuje, miesto toho sa nanovo prepisuju aplikacie (vid sluzby ako mobile.me a im podobne).
Já lidi jako je Staníček nechápu. Potřeboval někdy něco najít na Internetu?
Vždyt to kvůli "jeho" stylům, javascriptům a AJAXům je prakticky nemožené.
Ledaže byste byli něco jako grafiti na Internetu a zaujímalo Vás, jak co barevně vypadá nebo bliká a jak kde mají novou reklamu (a kdy pojede Vámi pomalované metro). Na rychlé prohlédnutí desítek odkazů si prostě musíte vzít nějaký textový WWW-browser.
Pro koho tedy lidé jako je autor stránky vytvářejí? Asi především pro čumily na Smíchovském nádraží čekající na "svůj" zamlovaný vlak nebo metro – a potom pro zbohatlíky na krizi, kteří občas odhodí (Staníčkovi) nějaké pamlsky či peníze, aby pro jejich potěchu vypracoval design jejich firemní stránky, a to honem než zbankrotují také.
Jenže to není vůbec pravda. Pokud se vrátíme do začátků CSS a Google, tak tam se docela jasně ukázalo, že dobře udělaným webům používajícím CSS bez tuny zbytečných vizuálních značek vyhledávač rozumí daleko líp a uživatel je tak i snáz najde.
Google si na to může obstarat dostatek výpočení kapacity.
Ale já než se prokoušu desítkami stránek, které na mě všechny blikají a přetáčejí se anebo jsou alespon mimo obrazovku, protože zrovna nemám nejnovější browser. (A to už nemluvím o době, potřebné na stažení všech nesmyslných obrázků jenom proto, že i s těmi si tvůrce hrál ve stylech, aby byl pomalý ale "in".)
Opravdu jste někdo potřeboval informaci, která byla třeba až v 15-tém odkazu?
A o upgradu prohlížeče jste nepřemýšlel? Já také někdy cvičně zkouším procházet weby v prvním Mosaicu. Vždy to prostě nejde, ale to není problém ani prohlížeče ani těch webů.
Já lidi jako je Staníček chápu :) A to i přesto, že na některé jednotlivosti mám trošku jiný názor (např. na IE7). Naopak nechápu lidi jako "uživatel si přál zůstat v anonymitě", kteří zjevně nechápou, ale nijak jim to nebrání k jednoznačným soudům.
—Vždyt to kvůli "jeho" stylům, javascriptům a AJAXům je prakticky nemožené.—
Ano, není nad mnohonásobně vnořovaný tabulkový layout, který podá všechna data krásně přehledně. </ ironie>
Samozřejmě, a všechna auta by mohla být černý Ford T, že.
Pekny clanek, diky.
nasprosty souhlas – diky za clanek
pretoze IE ma, ako jediny prehliadac, najslabsiu podporu css selektorov a css3..
Pěkný článek. Díky. A já jim tenkrát říkal: vykašlete se na univerzálnost a věnujte se pořádně jen jedné "disciplíně".
Hezke shrnuti. Jednou za cas kvalitni clanek.
Pripojuji se, nic lepsi na sobotni rano jsem k snidani nemohl doprat :-)
Chcem sa vas uzivatelov – webkoderov (ale aj autora clanku) spytat na toto:
Ked zacinate kodit novy disajn stranky, rozhodujete a vedome ovplyvnjete vykreslovacie mody jednotlivych prehliadacov? Urobite konkretne rozhodnutie, ze napr. FF, O a ine std. prehliadace prepnete do std. modu a "IE-cka" do quirku, alebo to ani neriesite.
Ak ano, ako mody nastavujete?
Ja to robim momentalne tak, ze vsetky standardne prehliadace (vratane IE7) nastavim do std. modu pomocou DTD XHTM 1.0 Strict s plne kvalifikovanou URL a IE6 a nizsie zhodim do quirku pomocou XML prologu na prvom riadku. Kdesi som davnejsie cital nazor, ze IE6 je v quirku predvidatelnejsi browser, preto to robim.
Stranku odladim vo FF pomocou Firebugu, v standardnych browseroch stranka takmer nevyzaduje ziadne dodatocne ladenie a potom IE6 vyladim pomocou podmienenych komentarov. Myslite si, ze je to efektivne (IMO ano)?
To je subjektivní a hodně záleží na tom, co děláte, já osobně postupuji většinou jednim ze dvou způsobů:
1/ klasické prezentační stránky tvořím v XHTML 1.0 strict pro všechny prohlížeče a málokdy přesáhnu 5 speciálních CSS deklarací pro MSIE 6 (většinou se týkjí základních sloupců)
2/ webové aplikace dělám v quirku (schodím ho tam buď pomocí XML deklarace, nebo pomocí CSS), protoze quirk box model je intuitivnější (box zabírá 200px bez ohledu na to, kolik zabírá jeho samotný obsah).