
Webové stránky dostanou rozpoznávání řeči – přichází Web Speech API

Webové stránky a aplikace lze ovládat hlasem. Minimálně v Google Chrome, který se řídí specifikací Web Speech API. Ukažme si, jak použití takového rozpoznání funguje. Podporována je i čeština.
Nálepky:
Práce s lidským hlasem není pro webové stránky něco zcela nového. Někteří z vás si možná vzpomenou, že hlasovou syntézu i rozpoznání řeči měla ve své době už Opera (po doinstalování příslušného doplňku, kód tehdy pocházel od IBM). Nejednalo se pouze o hlasové ovládání prohlížeče, k rozpoznávání řeči měly přístup i webové stránky, které pomocí JavaScriptu mohly od uživatele přijímat hlasový vstup, převádět ho na textovou podobu a s tou dále pracovat.
Nicméně tehdy na webu tento přístup neuspěl. Mezi další prohlížeče se nerozšířil, ani sama Opera ho dále nevyvíjela, ač nefungoval zcela spolehlivě (občas se v něm objevil problém a byl nutný restart prohlížeče) a před časem ukončila jeho podporu.
Web Speech API
Zapojení lidského hlasu do webových aplikací ovšem dostává další šanci. Objevilo se v poslední beta verzi prohlížeče Chrome. Řídí se návrhem specifikace Web Speech API Specification, ta pochází od Googlu a teprve se ukáže, zda ji přijme W3C a další prohlížeče.
Nejedná se ze strany Googlu o prvotinu, již před dvěma lety implementoval do Chromu tzv. Speech Input API, které je nové specifikaci do jisté míry podobné.
Demo
Pokud máte novou beta verzi Google Chrome, můžete si vyzkoušet malé demo. Podporováno je i rozpoznávání češtiny.
Z důvodů ochrany soukromí si prohlížeč od uživatele vyžádá povolení pro přístup k mikrofonu.
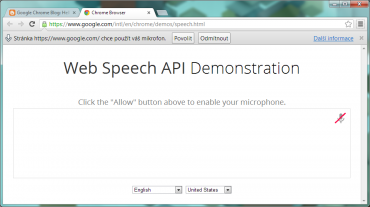
Během celého přístupu k mikrofonu je zobrazeno upozornění.

Rozpoznání hlasu funguje pouze pokud jste online, využívá k tomu službu Googlu podobně jako aplikace na Androidu. Pokud se odpojíte, přístup je ukončen.
Další text vychází z článku Voice Driven Web Apps: Introduction to the Web Speech API, který napsal Glen Shires a je zde zveřejněn pod licencí CC BY 3.0.
Podívejme se, jak demo funguje. Nejprve ověříme, zda prohlížeč podporuje Web Speech API; stačí zkontrolovat přítomnost objektu webkitSpeechRecognition. (Jedná se o experimentální API, obsahuje proto vendor prefix.) Po té vytvoříme objekt webkitSpeechRecognition, který nám poskytne potřebné rozhraní.
if (!('webkitSpeechRecognition' in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
Výchozí hodnotou atributu continuous je false, což značí, pokud uživatel přestane hovořit, rozpoznávání bude ukončeno. To je ideální volba pro jednoduché texty, např. krátké pole input. V našem demu ho ale nastavíme na true a rozpoznávání tak bude pokračovat, i když uživatel přestane hovořit.
Výchozí hodnotou atributu interimResults je false, což znamená, že při rozpoznávání budou vráceny konečné výsledky, které se již dále nezmění. V našem demu ho nastavíme na true, získáme tak rychlou odezvu rozpoznávání, výsledky se ale můžou dále měnit. Sledujte pozorně demo, šedivý text je dočasný a někdy se ještě změní, zatímco černý text je již konečným výsledkem rozpoznávání.
Když uživatel klikne na tlačítko mikrofonu, rozpoznávání začne:
function startButton(event) {
...
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
Nastavíme jazyk uživatele (dle BCP-47, např. „en-US“ pro americkou angličtinu). Pokud bychom ho nenastavili, byl by nastaven dle atributu lang kořenového prvku HTML dokumentu.
Po té zavoláme recognition.start(), čímž aktivujeme rozpoznávání řeči. Následně je vyvolána událost onstart a s každým novým výsledkem rozpoznávání je vyvolána událost onresult.
recognition.onresult = function(event) {
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
Naše funkce výsledky spojí do dvou řetězců: final_transcript a interim_transcript. Výsledné řetězce mohou obsahovat znak „n“, např. když uživatel řekne „new paragraph“, proto použijeme funkci linebreak ke konverzi na HTML značky <br> nebo <p>. A konečně vložíme oba řetězce do příslušných span prvků.
interim_transcript je lokální proměnná a vytváří se znovu při každém zavolání, protože dočasné výsledky se mohou měnit. Mohli bychom totéž udělat i s final_transcript nastavením počátku cyklu na 0. Ovšem finální text se už nemění, rychlejší bude použití globální proměnné final_transcript, takže cyklus začne od event.resultIndex a bude se přidávat jen nový text.
A to je všechno! Zbylá část kódu má jen kosmetický charakter, např. změna vzhledu tlačítka s mikrofonem, animace červené tečky okolo něj apod.
Martin Hassman
Martin Hassman založil a vede magazín Zdroják. Absolvoval VŠCHT Praha. Byl u založení projektu CZilla (dnes už nepamatujete, nevadí). Stavěl mosty a metal cestu pro HTML5 (to tu ještě máme). V GUG.cz organizoval akce pro vývojáře (a jestli neumřeli, kódují si dodnes…).



Tady se píše, že čeština podporována zatím nebude. No, na druhou stranu, nevím jak moc velkou váhu přisuzovat právě technetu.
Čeština podporovaná je, stačí si to v tom demu vyzkoušet 8-)
No jo, no. 8-)
Dokud to nebude offline a v Chromiu, je to na nic.