Architektura Druid.io

Druid.io je distribuovaná databáze napsaná v Javě, která se skládá z několika částí. Těmto částem říkáme uzly (nodes) a jsou to separátní Java procesy. Základní instalace Druidu potřebuje alespoň čtyři uzly: Realtime, Historický, Koordinátor a Broker, přičemž každý z nich má jinou zodpovědnost. V článku si všechny čtyři uzly představíme.
Seriál: Druid.io (3 díly)
- Druid.io: distribuovaná immutable databáze pro analytické výpočty 30. 4. 2015
- Architektura Druid.io 18. 5. 2015
- Jak Druid.io agreguje data 11. 6. 2015
Článek původně vyšel na autorově webu Programio.
Dostáváme data do Druidu
Není typické, aby aplikace, které generují data (například naše Node.JS HTTP servery), posílaly data přímo do Druidu. Místo toho využívají nějakého messaging systému, do kterého zprávy posílají, a odtud se poté dostanou až do Druidu. My používáme Kafku.
Začnu s popisem starší verze Druidu, kterou už sice nepoužíváme, ale jednodušeji se vysvětluje. Vstupním bodem celého Druid clusteru je Realtime uzel.
Realtime uzel
Realtime uzel je služba, která se stará o načítání zpráv z Kafky nebo z jiného messaging systému. Spouští se jako obyčejný Java proces:
java io.druid.cli.Main server realtimeV praxi by tam ale byla ještě hromada dalších parametrů, kterými se teď nebudeme zatěžovat. Realtime uzel potřebuje na vstupu ještě konfigurační soubor, tzv. “specFile”. My si z něj ukážeme jen pár částí. Začneme tou, kde se definuje, odkud se budou číst data:
{
"type": "kafka-0.8",
"feed": "impressions",
"parser": {
"data": {
"format": "json"
},
"timestampSpec": {
"column": "timestamp",
"format": "iso"
}
}
}SpecFile říká, ať Realtime uzel čte zprávy z Kafka topicu impressions a ať očekává na vstupu JSON, který má vlastnost timestamp, ve kterém je uložen čas, kdy událost nastala. Toto je opravdu důležité – do Druidu lze dostat jen události, které nastaly v určitý čas a Druid potřebuje vědět kdy. Zprávy bez timestampu Druid zahodí.
Po spuštění začne uzel číst zprávy z topicu, zpracovávat je a ukládat je. V tuto chvíli jsou data dotazovatelná – mohli bychom poslat přes REST API dotaz na Realtime uzel a získat třeba počet zpracovaných impresí.
Segment
Během čtení zpráv začne Realtime uzel vytvářet něco, čemu se říká segment. Segment je soubor, který obsahuje Druidem zpracovaná, indexovaná a agregovaná data za určitý čas. Zpracovaný segment už je dále neměnný, není ho možné updatovat.
Kolik dat bude v jednom segmentu obsaženo závisí na hodnotě segmentGranularity:
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "hour"
}Druid by pro každý nový den začal vytvářet nový segment. Pro jednoduchost můžeme nyní předpokládat, že máme-li denní segmenty, pak se pro každý den vytvoří jeden soubor, který obsahuje všechna data z tohoto dne. Tento soubor se pak nakopíruje na některý z druidích serverů a tento server zodpovídá dotazy pro daný den.
Životní cyklus segmentu
Dejme tomu, že nastartujeme Realtime uzel v pondělí v 11:15. Realtime uzel by začal okamžitě vytvářet denní segment pro pondělí a tento segment by zpracovával až do půlnoci. Po celou dobu by data za pondělí byla na Realtime uzlu, ale byla by dotazovatelná přes REST API.
Další zajímavá věc se začne dít na konci dne, o půlnoci. Realtime uzel se začne připravovat na další segment. V 00:00 se vytvoří další segment a zprávy z úterka se zpracovávají do tohoto nového úterního segmentu.
Pondělní segment je v tuto chvíli považován za uzavřený a Druid už do něj žádnou další zprávu nevloží. Díky tomu může Druid pozměnit strukturu pondělního segmentu tak, aby data v něm byla optimalizována pro vyhledávání. Po uzavření pondělního segmentu proto Druid přeskládá všechny zprávy a vytvoří nové indexy, aby se v segmentu dalo rychle vyhledávat.
Tento upravený segment odešle do deep storage. Tím Druiďáci nazývají vzdálené úložiště, ve kterém jsou archivovány všechny segmenty. V současné době je podporováno HDFS a Amazon S3. Tohle je podstatná informace – Druid neobsahuje nic jako trvalé úložiště pro zpracované segmenty. Samotná data musíme uložit jinam. Na druhou stranu napojení na ostatní služby není nijak těžké. My používáme HDFS.
Metadata o novém segmentu uloží Druid do MySQL. Základní schéma vypadá takto:

Koordinátor a Historický uzel
Nyní přichází na řadu další dva druidí uzly: Koordinátor a Historický. Oba uzly jsou zase jen další Java procesy spuštěné na serverech. Historický uzel nezpracovává žádná nová data, jen přebírá segmenty, které vytvořil Realtime uzel.
Koordinátor řídí přiřazování segmentů. Máme-li v clusteru deset Historických uzlů, musíme se rozhodnout, který z nich bude servírovat náš pondělní segment. Koordinátor je ten, kdo má v tomto konečné slovo. Proto Koordinátor sleduje stav clusteru a když zjistí, že přibyl nový segment, nalezne vhodný Historický uzel a přikáže mu, aby si nový segment stáhl z deep storage. Segmenty se nikdy nepřesouvají mezi druidími uzly přímo, vždy jen přes deep storage.
Pomůžeme si dalším obrázkem:

Když Historický uzel stáhne segment, oznámí to clusteru a všechny dotazy na data, která jsou uložena v tomto segmentu, půjdou na tento server. Za normálních okolností platí, že všechny dosud vytvořené segmenty jsou buď na Historických uzlech, nebo na Realtime uzlech.
Časová posloupnost akcí při vytváření segmentu by mohla vypadat takto:
- úterý 00:00: Realtime uzel začne vytvářet úterní segment. Oznámí clusteru, že všechny dotazy na úterní data mají jít k němu. Dále uzavírá pondělní segment a začíná vytvářet nové indexy pro pondělní segment.
- 01:30 Kompilace pondělního segmentu dokončena, Realtime uzel začíná nahrávat segment do HDFS.
- 01:50 Nahrávání dokončeno, Realtime oznamuje clusteru, že vytvořil nový segment.
- 01:51 Koordinátor přikáže některému Historickému uzlu, aby si k sobě stáhnul pondělní segment.
- 02:08 Historický uzel dokončil stahování segmentu a informuje cluster o tom, že bude odpovídat na všechny dotazy za pondělek.
- 02:09 Realtime uzel maže pondělní segment a oznamuje clusteru, že už dále nebude odpovídat na dotazy na pondělní data.
Teď ale máme data za pondělí na Historickém uzlu a data za úterý na Realtime uzlu. Co když chceme znát součet impresí za oba dny současně? Musíme se zeptat obou serverů. Naštěstí to ale nemusíme dělat ručně, Druid nám poskytuje čtvrtý typ uzlu, který právě řeší dotazování.
Broker uzel
Všechny dotazy posíláme Brokeru. Broker je další uzel Druidu, který za nás řeší dvě věci:
- Ptáme-li se na nějaká data, Broker zjistí, které segmenty tato data obsahují a které uzly tyto segmenty servírují.
- Broker přepošle dotaz všem uzlům, které servírují potřebné segmenty a čeká na odpovědi. Tyto odpovědi následně spojí do jedné odpovědi (například sečte počty impresí za pondělí a za úterý) a odešle tuto odpověď zpátky klientovi.
Broker uzel nám jako klientům zajišťuje transparentnost – nemusí nás zajímat, na kterých serverech jsou uložena naše data, jestli je servíruje Realtime uzel nebo Historický uzel. Broker dále cachuje výsledky z Historických uzlů, čímž se výrazně zlepšuje výkonnost celého clusteru. Historické uzly obsahují immutable segmenty, takže pro dva stejné dotazy vrátí vždy stejné výsledky. Cachovat data z Realtime uzlu si nemůže dovolit, protože tam se data typicky mění každou sekundu.

Jak výpadek jedné ze služeb ovlivní chod clusteru
Výpadky Realtime uzlu
Na Realtime uzel jsou kladeny největší nároky – musí zpracovávat příchozí zprávy, zároveň je musí poskytovat k dotazování a k tomu všemu musí být nějak odolný vůči výpadkům.
- První přístup byl takový, že si Realtime uzel průběžně ukládal všechna data, která zpracovával, na disk. Po pádu Realtime uzlu a jeho restartu si mohl načíst již zpracovaná data z disku a mohl pokračovat dále tam, kde přestal. Toto ale zdaleka není stoprocentní řešení – mohlo se stát, že se nějaké zprávy zduplikují, ale to zase tak moc nevadí, protože lambda architektura. Jenomže pokud by shořel celý server, na kterém Realtime uzel běží, tak bychom přišli o všechna data. Navíc ve chvíli, kdy neběží Realtime uzel, třeba i jen minutu, nemáme přístup k datům, které už zpracoval.
- Proto se začaly ručně vytvářet repliky Realtime uzlů. To se bohužel muselo trochu nahackovat přes Kafka consumer group ID – spustily se dva Realtime uzly a každému se nastavilo jiné group ID, viz Jak funguje Kafka consumer. Jenomže to způsobilo další problémy a celkově je to víc hack než řešení. Navíc už není jednoduché jen tak přivézt k životu jednou spadlý Realtime uzel. Máme-li dva Realtime uzly, po pádu jednoho z nich a po jeho znovu nastartování získáme nekonzistentní stav clusteru, protože uzel, který spadl, obsahuje třeba hodinu stará data, zatímco uzel, který celou dobu běžel, má aktuální data.
- To se nakonec vyřešilo tím, že se přešlo od pull-based řešení k push-based řešení. V novějších verzích se proto typicky data do Druidu posílají, místo toho, aby si je Druid sám tahal z Kafky. O tom se ale budeme víc bavit někdy příště. Tento přístup zajistil, že replikace je už snadno konfigurovatelná věc. Můžeme nastavit, že chceme, aby se Realtime uzel třikrát replikoval. Spadne-li jedna replika, automaticky se obnoví až s dalším segmentem – nenastává problém s tím, že bychom získali hodinu stará data.
Výpadky zbylých částí clusteru
- Když vypadne jeden Broker, můžeme se zeptat druhého.
- Když vypadne Historický uzel, převezme jeho práci jiný Historický uzel. V Druidu můžeme nastavit replikaci Historických uzlů, takže pokud ji nastavíme na 2, po výpadku jednoho Historického uzlu se nestane nic – v clusteru bude vždy existovat ještě jeden uzel, který obsahuje dané segmenty. Pokud by vypadly všechny repliky pro daný segment, musel by se segment časem stáhnout na jiný Historický uzel. Do té doby, než by se segment stáhl, by byla data nedotazovatelná, ale zbytek funkčnosti clusteru by to neovlivnilo.
- Když vypadne Koordinátor a neexistuje jeho replika, tak se zmrazí stav clusteru. V tuto chvíli není možné, aby se segment z Realtime uzlu dostal na Historický uzel, protože Historickému uzlu nemá kdo říci, aby si stáhl nový segment. Nicméně segment, který zůstal na Realtime uzlu je nadále dotazovatelný. Problém by nastal až ve chvíli, kdy by na Realtime uzlu docházelo místo nebo paměť.
- Když vypadne MySQL, tak je to podobné, jako když vypadne Koordinátor.
Horizontální škálovatelnost
Realtime uzel
Ve starém přístupu jsme mohli vytvořit tolik Realtime uzlů, kolik partitionů obsahoval náš Kafka topic. V novém push-based přístupu už je to zcela nezávislé a můžeme si sami nastavit, kolik Realtime uzlů má zpracovávat vstupní zprávy. Můžeme nastavit, že naše zprávy budou zpracovávány třemi shardy a replikaci můžeme nastavit na dva. Tím dosáhneme toho, že se automaticky vytvoří celkem šest Realtime uzlů, které bude zpracovávat naše data. Vstupní zprávy se rozdělí na třetiny a každá třetina je poslána jiné dvojice uzlů.
Pro příklad předpokládejme, že máme devět zpráv, očíslované od jedné do devíti. Každý ze tří shardů bude zpracovávat “každou třetí zprávu”:

Potřebujeme-li se dotázat na aktuální data, musíme se vždy zeptat tří Realtime uzlů. Vypadne-li Realtime #3, zastoupí ho #4. Vypadne-li i ten, jsou zprávy ze Shardu #2 nedostupné. Realtime uzly #3 a #4 by se automaticky znova nastartovaly s novým segmentem (tj. v našem příkladě se začátkem nového dne).
Ostatní uzly
- Koordinátor horizontálně škálovatelný není. Máme-li více Koordinátorů, zvolí se mezi nimi leader a ten koordinuje cluster. Koordinátor nicméně vykonává nenáročnou činnost, jeden aktivní uzel by měl bohatě stačit.
- Historické uzly jsou sobě zcela nezávislé a můžeme jich mít kolik chceme. Každý Historický uzel zkrátka servíruje určitý počet segmentů, které jsou navíc immutable, a Broker ví o tom, který segment je uložený na kterém Historickém serveru. Můžeme mít klidně pro každý segment, tj. pro každá denní data, vlastní Historický uzel.
- Broker je opět nezávislý uzel, který nepotřebuje vědět o ostatních Brokerech. Broker jen přijímá dotazy a rozesílá je na Historické a Realtime uzly. Můžeme jich mít kolik chceme a v aplikaci pak střídavě rozesílat dotazy na různé Brokery.
Celkově vzato je Druid velmi horizontálně i vertikálně škálovatelný. Můžeme proto postavit větší cluster, než jaký jsme viděli na posledním obrázku. Pokud bychom nechali počet Realtime uzlů a jen zvětšili počet Historických uzlů, mohl by dotaz „vrať mi součet impresí za uplynulý týden“ položený v neděli dopadnout takto:

Broker se za nás zeptá Realtime uzlu z každého shardu a zároveň se zeptá všech Historických uzlů, které zrovna obsahují data, která potřebujeme. Počká na všechny odpovědi, ty spojí a vrátí uživateli.
A jaký je dosud největší Druid cluster?
- 50–100 PB surových dat, z kterých Druid po všech kompresích vytvořil 500 TB dat.
- 20 bilionů událostí (~ řádků).
- 400 serverů.
Konzistence dat
Data nejsou konzistentní napříč Realtime uzly. Může se totiž stát, že Realtime uzel #1 zpracovává zprávy s offsetem 10 000, zatímco Realtime uzel #2, jeho replika, je trochu pozadu a zpracovává zprávy teprve s offsetem 9 750, tedy je o 250 zpráv pozadu. Tomu se nedá vyhnout, ať už používáme starý přístup, nebo nový přístup. Broker se přitom může jednou zeptat Realtime uzlu #1 a potom uzlu #2. Potom by se mohlo stát, že by v prvním dotazu zjistil od uzlu #1, že už proběhlo 10 000 impresí, ale o sekundu později by z uzlu #2 zjistil, že proběhlo 9 750 impresí, což je zjevně nesmysl, aby o sekundu později nastalo méně impresí.
Nicméně pokud oba Realtime uzly stíhají, tak by tato nekonzistence měla být nepostřehnutelná.
Data napříč Historickými uzly jsou plně konzistentní, protože pokud dva Historické uzly servírují segment pro daný časový úsek, tak tyto dva segmenty jsou zcela identické.
ZooKeeper
V předchozích obrázcích jsem například nakreslil šipku z Koordinátoru přímo do Historického uzlu. To nebylo úplně přesné, protože ve skutečnosti Koordinátor s historickým uzlem nekomunikuje přímo, ale pomocí ZooKeeperu.
ZooKeeper je hojně používaná služba v distribuovaných systémech, protože umožňuje takové věci jako zvolit leadera v distribuované síti, udržuje synchronizovaný log napříč svými servery a často se používá na ukládání konfigurací či jiných metadat. Kromě toho poskytuje klienty, které jsou schopny reagovat na změnu dat v Zookeeperu.
Potřebuje-li Koordinátor něco říct Historickému uzlu, uloží na předem domluvené místo v ZooKeeperu danou zprávu a Historický uzel si potom sám všimne, že se v ZooKeeperu na dané adrese něco změnilo, zjistí co a provede příslušnou akci.
Ve skutečnosti tak obrázek s komunikací vypadá takhle (vypůjčeno přímo z dokumentace Druidu):
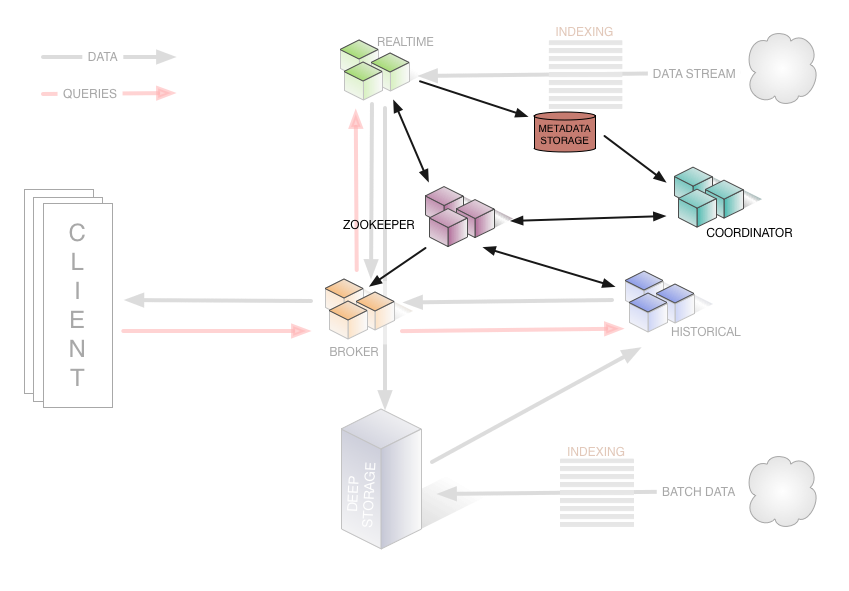
Všechny šipky jdou vždy z druidího uzlu do ZooKeeperu, nikdy ne do dalšího druidího uzlu. Na principu se nic nezměnilo. Druiďáci ale mají v plánu použití Zookeeperu omezit. Což není úplně neobvyklé, nová Kafka už také daleko méně závisí na ZooKeeperu než starší verze.
Přes ZooKeeper také Realtime a Historické uzly sdělují celému clusteru jaké segmenty jsou u nich aktuálně uložené. Na tyto informace pak reaguje Broker, který musí v každé chvíli vědět, koho se má zrovna zeptat.
Příště si ukážeme, jak Druid agreguje a zpracovává všechny vstupní zprávy, ze kterých vytváří segmenty.
Lukáš Havrlant
Pracuji ve firmě Internet Billboard jako Node.JS vývojář, píšu blog Programio, občas tweetuju.


