V8: JavaScript uvnitř Google Chrome

Dnes nahlédneme pod pokličku V8 – interpretu JavaScriptu uvnitř Google Chrome. Podíváme se na tři jeho klíčové vlastnosti – kompilaci do nativního kódu, skryté třídy a garbage collector. Na závěr si ukážeme, jak V8 implementuje JavaScript z velké části v JavaScriptu samém.
Seriál: Do hlubin implementací JavaScriptu (14 dílů)
- Do hlubin implementací JavaScriptu: 1. díl – úvod 30. 10. 2008
- Do hlubin implementací JavaScriptu: 2. díl – dynamičnost a výkon 6. 11. 2008
- Do hlubin implementací JavaScriptu: 3. díl – výkonnostně nepříjemné konstrukce 13. 11. 2008
- Do hlubin implementací JavaScriptu: 4. díl – implementace v prohlížečích 20. 11. 2008
- Do hlubin implementací JavaScriptu: 5. díl – implementace mimo prohlížeče 27. 11. 2008
- SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj 4. 12. 2008
- SquirrelFish: optimalizace vykonávání instrukcí a nativní kód 11. 12. 2008
- SquirrelFish: regulární výrazy, vlastnosti objektů a budoucnost 18. 12. 2008
- SpiderMonkey: zpracování JavaScriptu ve Firefoxu 8. 1. 2009
- SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu 15. 1. 2009
- V8: JavaScript uvnitř Google Chrome 22. 1. 2009
- Rhino: na rozhraní JavaScriptu a Javy 29. 1. 2009
- Velký test rychlosti JavaScriptu v prohlížečích 5. 2. 2009
- Javascriptové novinky: souboj o nejrychlejší engine pokračuje 19. 3. 2009
Motivace
Když Google před dvěma lety začínal vyvíjet svůj prohlížeč Chrome, rozhodl se v něm využít renderovací jádro WebKit (používané v prohlížeči Safari a vyvíjené firmou Apple). Bylo dobře napsané, efektivní a snadno upravitelné. Implementace JavaScriptu ve WebKitu se ale Googlu nelíbila, a nutno říci, že oprávněně – tehdejší engine JavaScriptCore (předchůdce dnešního SquirrelFish) byl relativně pomalý a neefektivní. Google se proto rozhodl napsat implementaci vlastní, a tak se zrodil V8.
Vývoj „osmiválce“ Google poněkud neobvykle svěřil své dánské pobočce. Vedoucím odpovědného týmu se stal Lars Bak. Ten není v oblasti virtuálních strojů žádným nováčkem, vedl mimo jiné vývoj známého a úspěšného javovského virtuálního stroje HotSpot. O virtuálních strojích také publikuje a spolu s kolegou z Googlu Kasperem Lundem o nich i přednáší na univerzitě v Arhusu.
Tři pilíře V8
Podle dokumentace Googlu stojí V8 po technické stránce na třech důležitých pilířích:
- kompilace do nativního kódu
- skryté třídy
- inline keš a garbage collector
Pojďme se na ně podrobněji podívat.
Kompilace do nativního kódu
V8 na rozdíl od ostatních interpretů JavaScriptu v prohlížečích nereprezentuje skript bajtkódem a nemá žádný virtuální stroj. Kód skriptu je po parsování uložen v podobě AST (strom reprezentující jednotlivé konstrukce jazyka) a dle potřeby se kompiluje přímo do nativního kódu. Kompilátor je jednoprůchodový a v tuto chvíli se příliš nestará o optimalizaci vygenerovaného kódu. Zpracovává se vždy jen jedna funkce, a to v okamžiku jejího prvního zavolání. Kód, který nebude nikdy spuštěn, se tak vůbec nekompiluje, což šetří čas.
Absence virtuálního stroje omezuje použití V8 pouze na platformy, které podporuje generátor nativního kódu – v současnosti x86 a ARM (ta se používá na mobilních zařízeních). Oproti ostatním interpretům, které virtuální stroj mají, je to konkurenční nevýhoda. Na druhou stranu, pro webové prohlížeče jsou dnes podstatné pouze platformy, které již V8 podporuje, plus x86–64, jejíž podporu nebude pro Google těžké doplnit.
Skryté třídy a inline cache
Pro urychlení přístupu k vlastnostem objektů (a tedy i pro urychlení volání metod) používá V8 princip skrytých tříd a inline keše. Použitá technika je prakticky stejná jako u SquirrelFish a SpiderMonkey a již jsme si ji popisovali – nebudeme to zde tedy dělat znovu. Jen připomeňme, že její princip spočíval v průběžné evidenci informací o struktuře objektů v kódu skriptu a dynamické náhradě kódu přistupujícího k vlastnostem objektů za rychlejší na základě evidovaných dat.
Garbage collector
Garbage collectorům jednotlivých interpretů jsme se v seriálu vůbec nevěnovali – nebyly totiž nijak zajímavé. U garbage collectoru V8 se ale pozastavíme, protože je poměrně vyspělý. Konkrétněji je stop-the-world, kopírující, inkrementální a vícegenerační. Co jednotlivé pojmy znamenají?
Když se V8 rozhodne „uklidit“, zastaví se vykonávání programu (odtud „stop-the-world“), aby se nestalo, že se garbage collector a program budou navzájem rušit. Část paměti, kde leží alokované objekty JavaScriptu, se prohlásí za starou a připraví se oblast nová. Následně se začnou procházet všechny objekty ze staré oblasti, na které se dá z běžícího programu „dosáhnout“, a postupně se překopírují do nové oblasti (odtud „kopírující“). Ukazatele na ně se přitom zaktualizují. Když jsou všechny dostupné objekty zkopírovány, stará oblast je odalokována. Všechny objekty, které nebyly z běžícího skriptu dostupné, tak zaniknou. (Toto je ve skutečnosti jen jeden z možných průběhů garbage collection, ale podrobnější rozbor by zamlžil náš další výklad.)
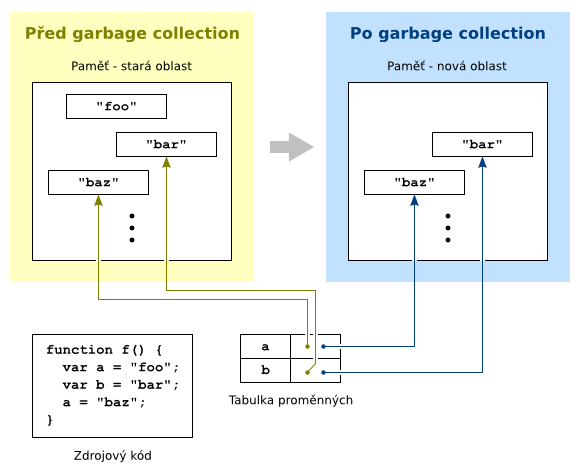
Při garbage collection se do nové oblasti kopírují jen dosažitelné objekty. Ukazatele v tabulce proměnných se zaktualizují.
Protože proces garbage collection dlouho trvá a program po tuto dobu neběží, vše se ve skutečnosti děje po částech (odtud „inkrementální“). Garbage collector tedy nezkoumá všechny objekty najednou, ale vždy jen určité omezené množství a zas na chvíli spustí program. To se opakuje, dokud není celý proces dokončen. Výsledkem je rozložení jedné dlouhé pauzy (která by mohla být pro uživatele prohlížeče nepříjemná) na několik menších (které uživatel ani nepostřehne). Cenou je pochopitelně zesložitění logiky, která musí počítat s tím, že se mezi jednotlivými fázemi například alokují nové objekty.
Většina objektů zaniká rychle po jejich vzniku (typicky lokální proměnné). Na druhou stranu, pokud už objekt existuje delší dobu, je pravděpodobné, že bude globálního charakteru a jen tak nezmizí. Tato dvě pozorování vedla k rozdělení objektů do generací (odtud „vícegenerační“). Každý objekt začne svůj život v mladé generaci a pokud přežije několik běhů garbage collection, je přesunut do starší generace. Garbage collector při běžném průchodu zkoumá jen objekty z mladé generace a na starší generaci se dívá pouze „jednou za čas“.
Výše popsané techniky nesou nijak převratné a používají se řadu let. U některých je to ale poprvé, co byly použity u interpretu JavaScriptu v prohlížeči, a často nejsou implementovány ani u interpretů jiných dynamických skriptovacích jazyků. Pravděpodobně je to dáno tím, že napsat dobrý garbage collector je poměrně těžké a zdaleka ne každý implementátor je ochoten vynaložit potřebné úsilí.
Garbage collector ve V8 jsme zde popsali jen stručně a neúplně. Detailnější popis najdete ve videu a slajdech z Google Developer Day 2008 v Praze.
VÍCE K TÉMATU: Jak proběhl Google Developer Day 2008 v Praze
Reprezentace hodnot
V předcházejících dílech seriálu jsme si ukazovali, jak interprety uvnitř reprezentují hodnoty různých javascriptových typů (viz popis SquirrelFish a SpiderMonkey. Pro pořádek bychom to měli u V8 udělat také.
Všechny interprety reprezentují hodnoty složitějších typů (String, Object, částečně Number) ukazatelem na nějakou datovou strukturu obsahující potřebné údaje. Hodnoty jednoduchých typů (Undefined, Null, Boolean, částečně Number) se snaží pomocí „bitové chytristiky“ vměstnat přímo do ukazatele. To je možné díky tomu, že nízké bity ukazatelů nejsou na dnešních architekturách využívány a můžou být použity k zakódování dalších informací. Důsledkem je snížení počtu nutných dereferencí ukazatelů a tedy i zrychlení.
Reprezentace hodnot ve V8 je v principu podobná ostatním interpretům, je ale trochu jednodušší. V8 se přímo do ukazatelů snaží vměstnat jen část hodnot typu Number (31-bitová celá čísla), vše ostatní je odkaz na složitější strukturu. U Undefined, Null a Boolean ale existuje jen jedna či dvě instance daného typu (hodnoty undefined, null, true a false), takže ukazatele vždy vedou na stejná místa. Zjistit, zda daný ukazatel reprezentuje např. hodnotu true, je tak otázka jeho porovnání s předem známou hodnotou (adresou jedné ze dvou instancí typu Boolean). Není tedy třeba ukazatel dereferencovat (stejně jako u SquirrelFish a SpiderMonkey). Ač je tedy reprezentace hodnot ve V8 malinko odlišná od SpiderMonkey a SquirrelFish, efektivitou vyjde prakticky nastejno.
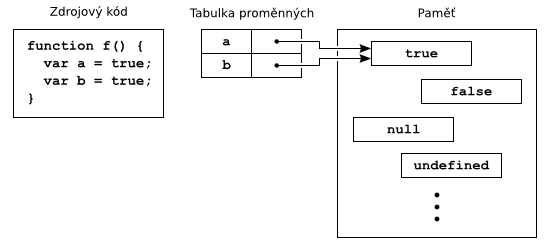
Ukazatele v tabulce proměnných s typem Boolean ukazují všechny na tutéž instanci.
Runtime
Velice zajímavou součástí V8 je jeho runtime. Ten zahrnuje především implementaci standardních objektů a metod jazyka, jako třeba Array.sort nebo String.split.
JavaScript v JavaScriptu
Tvůrci V8 zvolili zajímavou taktiku – místo aby runtime psali v jazyce C nebo C++ (tak tomu je v ostatních interpretech), rozhodli se ho napsat v JavaScriptu samotném. Důvodem je větší pohodlí při programování (kdo raději programuje v C než v JavaScriptu, ať zvedne ruku…) a snadnost úprav. Rychlostní zpomalení oproti C/C++ není velké, protože kód runtime je stejně jako jakýkoliv jiný javascriptový kód kompilován do nativního kódu.
Přesto ale zní celá myšlenka dost nesmyslně – jak je možné psát součást JavaScriptu v JavaScriptu? Jak lze v JavaScriptu napsat třeba třídu String bez toho, aby už byla k dispozici? Jak se bude třeba alokovat paměť pro její instance, když na to JavaScript nemá jazykové prostředky? Není to celé problém typu slepice a vejce?
Odpověď na tyto otázky je jednoduchá – malinko jsem lhal. Většina runtime opravdu je napsaná v JavaScriptu, ale určité primitivní funkce jsou implementovány v C++. Tyto funkce poskytují především základní operace s datovými strukturami (jako jsou pole nebo řetězec) a javascriptový kód je může snadno volat. Kód runtime je tedy taková obálka nad těmito primitivními funkcemi, zapouzdřující je do objektově-prototypové podoby.
Pokud by vás zajímalo, jak kód runtime v JavaScriptu vypadá, můžete se podívat přímo do zdrojového kódu V8 a vyhledat si všechny javascriptové soubory (*.js) v adresáři /src. Poměrně dobrou představu o kódu vám dá například implementace operátoru + nebo funkce String.substring. Volání funkcí prefixované znakem % v souborech runtime jsou ve skutečnosti volání primitivních funkcí napsaných v C++. Ty jsou implementovány v souboru runtime.cc.
Předkompilace
Protože kompilace celého runtime do nativního kódu docela trvá a runtime se nijak nemění, je při kompilaci V8 předkompilován a je uložen jeho snapshot. Tento snapshot je pak při inicializaci V8 natažen a propojen s běhovým prostředím. Rychlost startu V8 se díky této optimalizaci podařilo snížit z cca 30 ms až na 4–8 ms (zdroj bohužel neuvádí, na jakém stroji).
Co nás čeká příště
Náš seriál se pomalu, ale jistě blíží k závěru – zbývají už jen dva díly. Ten příští budeme věnovat interpretu Rhino, který je zajímavý tím, že je napsán v Javě. Právě integrace mezi JavaScriptem a Javou bude to, co nás bude zajímat nejvíc.
Zdroje
- Introduction – V8 JavaScript Engine – hlavní stránka dokumentace V8
- Design Elements – V8 JavaScript Engine – popis designu V8
- Video a slajdy z Google Developer Day 2008 v Praze
David Majda
Autor je vývojář se zájmem o programovací jazyky, webové aplikace a problémy programování jako takového. Vystudoval informatiku na MFF UK a během studií zde i trochu učil. Aktuálně pracuje v SUSE.



ja se teda hlasim…
uzitecnost tech vlastnosti je totiz casto velice sporna a muze vest k celkovemu zpomaleni aplikace.
Autor možná narážel na Python. Tam je reference counting + detekce cyklů. Problémem není ani tak rychlost, ale spíš existence globálního zámku (GIL), protože synchronizovat každou (de/in)krementaci by bylo ještě horší.
Jinak super článek.
Nenarážel, toto je pro mě novinka. Python znám jen zběžně.
pythoni gc je taky vicegeneracni.
lze vlastnosti (konfiguraci) gc v prohlizecich nejak menit?
Nevím o žádném prohlížeči, kde by to šlo.
Věděl jsem, že se někdo najde :-)
V tom případě je otázka, proč své garbage collectory podobným směrem rozvíjí třeba Sun ve své JVM nebo Microsoft v .NET. Kdyby byly „nadupané“ garbage collectory méně výkoné, než ty jednoduché, tak by je přeci vývojáři neimplementovali.
Google často hraje "na krásu", možná kvůli prestiži. Zrovna v Javě je prý využívání paměti špatné, takže asi předpokládají, že jakýkoli vývoj bude k lepšímu a proč navíc nesáhnout po trendy řešení.
Microsoft podle mě záměrně komplikuje .NET, aby házel klacky pod nohy konkurenčním prostředím pro běh Windows aplikací, jako třeba Wine. Samotný přínos .NETu je podle mě pochybný, mnoho verzí, mnoho děr, mnoho zabraného místa, velké stahování, pomalejší programy, které neběží jinde a .NET musí instalovat správce.
Mám dojem, že tímto neobjektivním (a nepravdivým) příspěvkem jste se právě vyřadil z věcné diskuze.
Možná jsem se trochu rozepsal mimo téma, ale subjektivní je _cokoliv_, co napíše jakýkoli člověk a trvám ta tom, že tomu, co jsem napsal, věřím a beru to za pravdu. Mohu se samozřejmě mýlit, ale vyprošuji si urážlivé napadání, oponujte mi laskavě věcně.
mozna proto, ze napsat slusny garbage collector je docela veda… napriklad incrementalni GC umoznuje programu bezet plynulej, ale za cenu ze celkovy cas straveny v GC se zvysi, atd.
Pravil uživatel Boehmova konzervativního GC :-)
A pokud vím, všechny zmíněné techniky jsou dneska v podstatě mainstream (i když psát inkrementální algoritmus bych nechtěl, to přebarvování jsem zatím moc nepochopil :-) ) a o tom, že by jejich užitečnost byla sporná, slyším prvně. Nebyly by nějaké odkazy?
zkusil jsem spoustu 3rd party collectoru a boehmuv GC je bohuzel jediny (OSS) poradne pouzitelny (portabilni, multithreadovy,…)
ne… vsechno jsem si to bohuzel musel overit sam… :-/
Přijde mi to divný. Vždyť to v podstatě všechno vymysleli Lispaři :-)
LISPari vymysleli spoustu chytrych veci. o tom zadna… (mimochodem i ten typ kompilace, ktery je pouzity ve V8 jsou uz videl v nejakem lispovem prekladaci)
velky problem soucasnych GC je, ze nejvetsi vyvoj se deje kolem JVM a ostatni jazyky tak nejak sbiraji jenom drobky…
Já nevím, a proč je to problém? Chlapci od JVM se poslední dobou snaží udělat z toho svého bazmeku univerzální virtuální mašinu a podle toho, co se děje kolem MLVM (Da Vinci Machine), to vypadá nadějně. Garbage collectorů mají hromadu už teď, a jsou docela konfigurovatelné, do Javy 7 by měl přibýt další (což mi připomíná, že si musím konečně najít čas na ten článek o G1).
Super clanek, diky za nej…
Jo jo, super. Diky.
Děuji za pochvaly :-)
Zda se mi to nebo je ta funkcionalita garbage collectoru stejna jako je u Microsoft .Net ?
Nevím jestli je úplně stejná, ale podobná určitě (alespoň podle toho mála, co o vnitřku .NETu vím).
Možná by byl zajímavý článek, který by porovnával garbage collectory v různých reálně používaných jazycích/prostředích.
GC u V8 je tu popsan jen zhruba, ale ano, je to dost podobne .NETu. Ten ma GC "compacting", tj. udrzuje souvislou oblast obsazene pameti – alokace objektu tak znamena jen zvyseni hranice tehle oblasti, garbage collection pak "sesype" objekty za sebe.
Take pouziva vice generaci (3?), kdy se starsi generace neprohledavaji – a ted si nejsem jisty, jestli si neudrzuje i seznam ukazatelu z nich jako dalsi koreny pro GC.
Videl jsem o tom moc pekny clanek – pokud by mel nekdo extra zajem, muzu zkusit vyhrabat link…
Garbage collector V8 je také částečně „compacting“, detaily se dají nalézt ve videu odkázaném v článku. Do článku jsem to opoměl zmínit.
Ja by měl zájem převeliký.
Taky bych mel zajem.
Kopírovací GC je compacting tak nějak z definice :-)
Kopírovací GC compacting není, protože compacting GC z definice nepotřebuje druhý poloprostor (tedy z definice, která se používá pro klasifikaci GC).
Jiná věc je, že podle těch slidů je ten GC částečně mark&sweep…
Kopírovací GC udržuje heap kompaktní, to nepopřete. A to jsem měl na mysli. Co je mimochodem compacting GC? Neexistuje jenom mark and compact.
Pokud si to dobře pamatuju z Google DevDay, GC ve V8 je pro mladší generaci kopírovací, pro starší mark and sweep, což je taková klasická kombinace.
Teď na to ještě koukám, a je to ještě trochu zajímavější (slajd č. 18).
Ano, garbage collector V8 je trochu komplikovanější než je popsáno v článku. Nechtěl jsem to z důvodů srozumitelnosti a omezeného prostoru až tak rozepisovat, tak jsem pouze zmínil, že popisuji jen jeden z jeho možných průchodů. Ostatně, Google to tak v některých svých materiálech dělá také a fakt, že popisuje jen něco, ani nezmiňuje.
Není někde ještě něco k té reprezentaci hodnot? Nebo aspoň jméno souboru zdrojáku v8, kde se to řeší. Dík.
Výklad o reprezentaci hodnot jsem se snažil vzít jen stručně, protože tohoto tématu jsme se už dotkli jak u SquirrelFish, tak u SpiderMonkey a V8 se od nich zas tak neliší. Pokud máte nějaké konkrétní otázky, můžu je zkusit zodpovědět nebo vás navést, kde odpovědi hledat.
Ve zdrojovém kódu se hodnoty řeší především v souboru
objects.h.Dík moc, zkoušel jsem to studovat před několika měsíci a moc chytrej jsem z toho nebyl, ale teď se znalostma z článku to možná bude už snažší, zkusim se k tomu vrátit.
Měl bych ještě jeden (možná triviální) dotaz: Jak je uděláno, že když se ve v8 vytvářejí třeba stringy:
v8::String::New("blabla")
tak že to je normální funkce a nikoliv metoda nějakýho objektu, který by udržoval tabluky stringů, objektů atd.? tj neco jako
context->NewString("blabla)
nebo
v8::String::New(context, "blabla")
Nebo oni si odkazy na všechny stringy uržovat nepotřebujou (kvůli GC)? (Co kdybych třeba rozjel víc v8 java Interpretrů najednou?)
No, vlastně když je GC kopírující, tak seznam všech objektů na GC nepotřebuju, ale zase potřebuju vědět, jakým alokátorem naalokovat paměť pro ten string, abych mohl pak uvolnit tu oblast, ze které se kopírovalo, ne?
GC obecně potřebují znát pouze "root set": sadu objektů, o kterých je známo, že jsou vždy dosažitelné. To jsou objekty na zásobníku, globální objekty, a tak. V případě generačních GC se to trochu komplikuje, ale to nechme. Tranzitivní uzávěr root set (všechny objekty, na které se z root set lze dostat přes reference) jsou pak "živé" objekty, ostatní lze vyházet. Takže obecně platí, že GC nepotřebuje tabulku všech objektů (to nezávisí na použitém algoritmu).
Uvolňování paměti je zajímavá otázka, to se leckde vůbec neřeší. Třeba Suní JVM co jednou schvátí, to už nenavrátí. Kopírovací algoritmus se obvykle popisuje tak, že alokovaná paměť se rozdělí na dvě části a ty si aplikace spravuje sama, ale zřejmě se dá implementovat i tak, že nová oblast pro objekty se vždycky alokuje znova a ta stará se po zkopírování všech živých objektů dealokuje, jak mi vyplývá z tohoto článku.
Dík za reakci, ale to se mi úplně nezdá. U Mark and Sweep alogoritmu je Mark fáze jasná, ale v té sweep fázi se uvolňují nedosažitelné objekty a pak je nějak potřebuji znát (přinejmenším v některých implementacích), abych je mohl uvolnit. Např. Lua si pro tento účel udržuje slinkovaný seznam objektů (aspoň v té verzi, na kterou jsem se koukal). Jak už jsem psal, pokud je GC kopírovací, tak to je něco jiného. Ale v tom případě existuje jenom jeden globální "alokátor" na objekty?
Nicméně stejně by mě zajímal odpověď na můj původní dotaz, protože absence nějakého kontextu mi připadá záhadná.
Pokud se týká stringů, tak třeba .NET na ně mí spciální zacházení. Zde je odkaz na dokument http://moon.felk.cvut.cz/~xballner/vyuka/x36api/lectures/API_6.pdf.
Ani u mark and sweep algoritmu nepotřebujete vyrábět seznam nedosažitelných objektů. Pokud třeba reprezentujete volnou paměť pro alokátor objektů jako zřetězený seznam volných bloků: v mark fázi označíte živé objekty a ve sweep fázi procházíte celý heap od začátku do konce a každý blok paměti, který nepatří živému objektu (to poznáte podle značky a velikosti každého objektu, která musí být známa), do toho seznamu přidáte. Ten seznam dokonce nemusí být nikde mimo, všechna data (velikost tohoto bloku + ukazatel na následující volný blok) mohou být uložena přímo na místě. Netuším, jak to dělají kucí od Luy, ale čekal bych spíš právě tohle.
Samostatné alokátory pro různé typy objektů – hm, to je zajímavé, to mne nenapadlo. Alokace objektu přece znamená, že se (v nursery) rezervuje určitá část paměti, případně se nějak inicializuje, a reference se někam uloží. S řetězcovými konstantami se třeba dělají různé fígle, ale v principu to na věci nic nemění. Takže mi ani nějak není jasné, proč by něco jako kontext alokace mělo existovat.
Nemyslel jsem samostatné alokátory pro různé typy objektů, ale Javascript "strojů". To, co popisujete v prvním odstavci, je jen jiná forma seznamu nedosažitelných objektů. Jde mi o to, jeslti ve v8 existuje jen jeden heap globální heap. Pokud mám jen jeden globální alokátor (heap), pak nemůžu rozjet vedle sebe víc samostatných Javascript strojů vedle sebe (jinak by měly měly společný heap (a případně další struktury právě nesené nějakým kontextem)).
Aha, rozumím, vlastně celou dobu píšu o něčem jiném :-) Podle toho textu odkázaného níže (Embedder's Guide) je kontext zřejmě implicitní. Představuju si to jako globální zásobník kontextů, přičemž aktivní je ten na vrcholu. Nějaká data ty kontexty určitě sdílejí, ale to je spíš optimalizace (na principu copy on write?), dá se na to koukat tak, že každý kontext má všechno vlastní.
Jo, asi bude vždy aktivní jen jeden, jinak si to taky vysvětlit nedovedu. Zkusím se znovu zanořit do zdrojáků, ale je to trochu nad moje síly.
Pročtěte si Embedder's Guide, lecos je tam vysvětleno a pokud tam nenajdete odpověď, aspoň budete budete tušit, co dál zkoumat. Více kontextů V8 samozřejmě podporuje (je to nutné už kvůli tomu, že je používán v prohlížeči, kde se obecně stránky nesmí navzájem ovlivňovat.
No jasně, já vim, že má, proto mi to vrtá v hlavě. Embedder's Guide jsem četl, ale moc mi to nepomohlo. Dokonce jsem si vytváření nového stringu ve V8 krokoval, ale za chvíli jsem se v tom ztratil.
Každopádně dík za odpovědi i za pěknou sérii.
dalsi js engine: http://www.terrainformatica.com/tiscript/main.whtm
Ja tedy zvedam ruku, ze mam radeji C ;-)
Za mne také čárku pro C :-)
C si nechajte, ale take C++ s STLkou a boostom… ;) uz iba trochu chrumkavej reflexie :(
Jak se dá vypnout ? Blbne mi mail na seznamu !
Jarku, nejspis tu jsi spatne. Hledas urcite nejake forum s radami uzivatelum, ze? Zkus se podivat na GUG, tam by ti mohli poradit.