Java na webovém serveru: práce s databází II

V předchozím díle jsme začali téma práce s databází, naučili jsme se k ní přistupovat pomocí JSP značek a napsat si vlastní zjednodušenou DAO vrstvu. Dnes se budeme věnovat dvěma pokročilejším způsobům přístupu k databázi – použití třídy JdbcTemplate a ORM Hibernate.
Seriál: Java na webovém serveru (16 dílů)
- Java na serveru: úvod 8. 1. 2010
- Java na webovém serveru: první web 15. 1. 2010
- Java na webovém serveru: práce s databází 29. 1. 2010
- Java na webovém serveru: práce s databází II 12. 2. 2010
- Java na webovém serveru: lokalizace a formátování 19. 2. 2010
- Java na webovém serveru: autorizace a autentizace 26. 2. 2010
- Java na webovém serveru: autorizace a autentizace II 5. 3. 2010
- Java na webovém serveru: porovnání Javy a PHP 10. 3. 2010
- Java na webovém serveru: Vlastní JSP značky a servlety 17. 3. 2010
- Java na webovém serveru: posílání e-mailů a CAPTCHA 24. 3. 2010
- Java na webovém serveru: píšeme REST API 7. 4. 2010
- Java na webovém serveru: SOAP webové služby 14. 4. 2010
- Java na webovém serveru: hlasování a grafy v SVG 28. 4. 2010
- Java na webovém serveru: Komentáře a integrace s Texy 9. 6. 2010
- Java na webovém serveru: AJAX formuláře 23. 6. 2010
- Java na webovém serveru: implementujeme Jabber 30. 6. 2010
Nálepky:
Jak jste si asi všimli v minulém díle, psát datovou vrstvu jen s použitím základního JDBC vyžaduje poměrně dost nudného a opakujícího se kódu. To znamená jednak práci navíc a jednak potenciální chybovost – čím víc kódu, tím víc míst, kde jsme mohli udělat chybu. Tyto problémy samozřejmě postupem času řešíme, optimalizujeme, vyčleňujeme opakující se kód do znovupoužitelných tříd… až najednou zjistíme, že si píšeme vlastní framework. Někdy je to správná cesta, jindy je ale lepší, soustředit se na jádro naší aplikace (obchodní logiku) a pro datovou vrstvu použít raději už hotový framework. V následujícím textu si proto ukážeme, jak využít kód, který za nás napsal někdo jiný – Hibernate a Spring.
Jen pro připomenutí: jako obvykle si z Mercurialu stáhneme aktuální verzi zdrojových kódů k dnešnímu dílu seriálu:
$ hg pull $ hg up "4. díl"
Případně si je můžete stáhnout jako bzip2 archiv přes web.
Pomocník JdbcTemplate
Třída JdbcTemplate pochází z frameworku Spring. Jedná se o velmi rozsáhlý framework a JdbcTemplate představuje jen zlomek jeho možností. Základní kostru třídy PodnikDAO necháme stejnou a upravovat budeme jen vnitřek metod getPodniky() a ulozPodnik(). Prezentační vrstva JSP a JavaBean tak může zůstat nezměněná.
Do webového projektu si přidáme knihovnu Spring Framework (již obsažena ve vaší instalaci Netbeans):
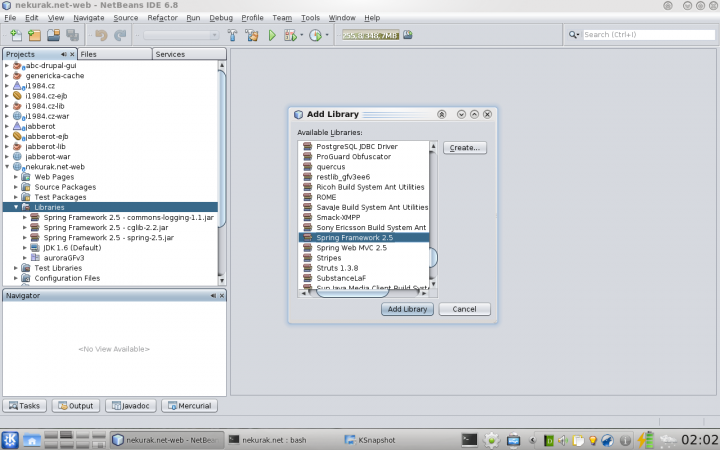
Díky použití JdbcTemplate dojde k výrazné úspoře kódu (přinejmenším na první pohled). Z původních devatenácti řádků:
public Collection<Podnik> getPodniky() {
Connection db = getSpojeni();
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = db.prepareStatement(getSQL(SQL.SELECT_VSECHNY));
rs = ps.executeQuery();
Collection<Podnik> vysledek = new ArrayList<Podnik>();
while (rs.next()) {
vysledek.add(new Podnik(rs.getInt("id"), rs.getString("nazev")));
}
return vysledek;
} catch (Exception e) {
log.log(Level.SEVERE, "Chyba při získávání podniků.", e);
return null;
} finally {
zavri(db, ps, rs);
}
}
Na pouhý jeden:
public Collection<Podnik> getPodniky() {
return jdbcTemplate.query(getSQL(SQL.SELECT_VSECHNY), podnikRowMapper);
}
Řekněte, není to skvělé? Je to skvělé! …bohužel tady nejsme v teleshoppingu, takže nebudu zastírat i tu druhou stranu mince. Jak tedy k úspoře kódu došlo?
Mapování pomocí RowMapperu
Jistě jste si všimli proměnné podnikRowMapper – ta odkazuje na instanci třídy PodnikRowMapper, kterou jsme si museli napsat. Třída implementuje springové rozhraní ParameterizedRowMapper a vypadá následovně:
…
public class PodnikRowMapper implements ParameterizedRowMapper<Podnik> {
public Podnik mapRow(ResultSet rs, int i) throws SQLException {
Podnik p = new Podnik();
p.setId(rs.getInt("id"));
p.setNazev(rs.getString("nazev"));
return p;
}
}
RowMapper se stará o vytažení hodnot z SQL výsledkové sady a jejich naplnění do instance požadované třídy. Výhodný je tento přístup zejména tehdy, když máme více metod pro načítání téhož typu objektů – např. jednou vracíme kolekci všech záznamů, jindy jen jeden konkrétní nebo podmnožinu – potom máme mapovací kód pěkně na jednom místě a když třeba přidáme do tabulky nový sloupeček, změnu v datové vrstvě děláme jen na jednom místě. Pro každou třídu/tabulku potřebujeme jeden RowMapper.
Jedná se vlastně o takový předstupeň ORM (objektově-relačního mapování), ovšem funguje jen pro načítání dat a ne jejich ukládání.
Pozor na nekontrolované výjimky
Další věc, které si nelze nevšimnout, je absence odchytávání výjimek. Spring totiž převádí kontrolované SQL výjimky na běhové (nekontrolované). Běhové výjimky nemusíme odchytávat (resp. kompilátor nás k tomu nedonutí), a tak chyba vyletí tak vysoko, kam až ji pustíme.
Pokud tedy nejsme dostatečně svědomití a nedoplníme dobrovolně kód pro ošetření chyb, odchytí výjimku až aplikační server a k uživateli se dostane v podobě standardní 500 HTTP chybové stránky. Už ve druhém díle jsme se naučili psát vlastní chybové stránky – pokud si je tedy nezapomeneme nastavit, k uživateli se až tak ošklivá chybová hláška nedostane. Přesto bychom na odchytávání výjimek neměli úplně rezignovat a ušetřené try { … } catch ( … ) { … } se nám přesunou jen do jiné části aplikace (ale mohou být centralizované a nemusí se tolik opakovat).
Velikost aplikace
Jak už to u frameworků bývá, zvyšují datovou velikost naší aplikace. V tomto konkrétním případě vzrostla velikost souboru nekurak.net-web.war (zkompilovaná aplikace) z 32 kilobajtů na úctyhodné 3 megabajty. Spring nabízí opravdu mnohem víc než jen JdbcTemplate a když už si ho do své aplikace zavlečete, bylo by škoda využívat z jeho potenciálu jen tak málo.
Zaujaly vás možnosti Javy a chcete se dozvědět o tomto jazyce víc? Akademie Root nabízí školení Základy programovacího jazyka Java a Pokročilejší kurz jazyka Java, na nichž se naučíte, jak tento multiplatformní objektově orientovaný jazyk používat.
Hibernate ORM
Hibernate je middleware pro objektově-relační mapování a persistenci dat. Použití ORM nám může ušetřit spoustu duplicitního a nudného kódu, ale i přidělat starosti, je to horké téma nejen do internetových diskusí. V článku se této polemice raději vyhnu (můžeme diskutovat pod ním) a podíváme se na praktický příklad – jednoduchou ukázku použití Hibernatu.
Nejprve si doinstalujeme podporu Hibernate do našeho Glassfishe. Pomocí webového rozhraní a nástroje Update Tool:
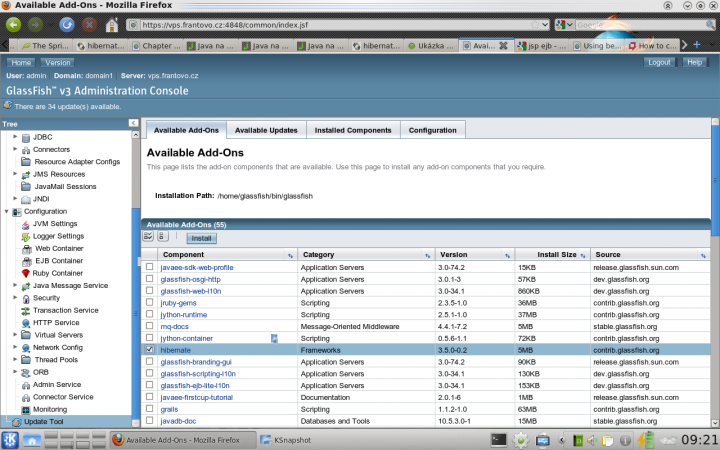
Glassfish si potřebné knihovny sám stáhne a potom je potřeba aplikační server restartovat.
S Hibernatem nebudeme pracovat přímo, ale pomocí tzv. Java Persistence API (JPA), což je abstraktní vrstva a Hibernate je jen jednou z několika implementací ORM, které v JPA můžeme používat (další jsou třeba TopLink nebo OpenJPA).
Poznámka: pro potřeby persistence jsem trochu přeuspořádal náš projek, nyní se skládá ze čtyř částí:
- nekurak.net-ear – zastřešující „enterprise“ projekt, který budeme nasazovat na server (obsahuje v sobě níže uvedené projekty)
- nekurak.net-war – původní webová vrstva: JSP a JavaBeany
- nekurak.net-ejb – EJB vrstva: zde budeme pracovat s Hibernatem
- nekurak.net-lib – společné knihovny – DTO a rozhraní
Konfigurace a mapování
Nejdůležitějším konfiguračním souborem je persistence.xml, ve kterém definujeme tzv. persistentní jednotku (PU) a JNDI jméno datového zdroje, který bude používat:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="nekurak.net-PU" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/nekurak</jta-data-source>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="validate"/>
<property name="hibernate.max_fetch_depth " value="3"/>
<property name="hibernate.default_batch_fetch_size" value="16"/>
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.show_sql" value="false"/>
</properties>
</persistence-unit>
</persistence>
Dále musíme provést vlastní mapování tabulek relační databáze na objekty. K tomu se používají buď anotace uvnitř javových tříd, nebo XML soubory. Mapování pomocí XML vypadá následovně – soubor Podnik.hbm.xml:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cz.frantovo.nekurak.dto.Podnik" table="podnik">
<id name="id" column="id" type="integer"/>
<property name="nazev" column="nazev"/>
</class>
</hibernate-mapping>
Datová vrstva realizovaná pomocí JPA
S daty pracujeme pomocí „entitního manažera“ – použití vidíte ve třídě PodnikHibernateDAO:
@Stateless
public class PodnikHibernateDAO implements PodnikHibernateDAORemote {
@PersistenceContext(unitName = "nekurak.net-PU")
private EntityManager em;
public Collection<Podnik> getPodniky() {
Query dotaz = em.createQuery("FROM " + t(Podnik.class) + " o ORDER BY nazev");
return dotaz.getResultList();
}
private static String t(Class trida) {
return trida.getSimpleName();
}
}
K dotazování používáme jiný jazyk než SQL – EJB-QL resp. JPQL. Tento jazyk má daleko blíže k javovým objektům než k relačním tabulkám, proto není až tak užitečné vyčleňovat ho do samostatných souborů, jako jsme to dělali s SQL. Dotazy můžeme psát jako obyčejné textové řetězce, ale můžeme je i poskládat z názvů tříd – viz metoda t() – díky tomu můžeme na dotazy používat refaktoring. Pokud bychom se např. rozhodli přejmenovat třídu Podnik na Hospoda, stačí ji refaktorovat a nemusíme ručně procházet všechny dotazy. Přehlednější a užitečnější zápis nechť si vybere každý sám.
Stejně jako v případě Springu se jedná o velmi rozsáhlou problematiku a každé z těchto témat by vydalo na samostatný seriál. Proto tento díl berte hlavně jako nástin možností a inspiraci k dalšímu studiu.
Závěr
Volba frameworku je vždy obtížné rozhodnutí a pokud situaci řešíte týmově, vstupují do hry navíc i rozdílné osobní preference jednotlivých kolegů. Neexistuje univerzální řešení a tohle rozhodnutí za vás nikdo neudělá – musíte vycházet ze svých zkušeností, z požadavků konkrétního projektu a znalostí vývojářů. Věřím, že čtyři možnosti nastíněné v tomto a předchozím díle vám s rozhodováním pomůžou.
V komentářích se prosím vyjádřete, jaká další témata by vás zajímala – v plánu jsou např. autorizace/autentizace, lokalizace, výstupní formátování, EJB.
Odkazy
- Spring Framework – Reference Documentation – dokumentace ke Springu 2.5.
- Spring Framework – Reference Documentation – dokumentace ke Springu 3.0.
- Hibernate Documentation Overview – přehled dokumentace k Hibernatu.
- EJB-QL examples – příklady dotazovacího jazyka EJB-QL (budete potřebovat místo SQL).
- Java Persistence API – základní informace o JPA.
František Kučera
Franta Kučera působí jako Java vývojář na volné noze. Programování je jeho koníčkem už od dětství. Kromě toho má rád Linux, relační SŘBD a XML.


jen je toho pro cechy skoda. Napsat anglicky a dat treba na dzone, precte si to vice lidi.
Neni lepsi mapovat pomoci anotaci primo v Entity tridach nez v xml?
Take si myslim. Prace s anotacemi mi pripada mnohem pohodlnejsi a logictejsi, kdyz jsou metadata i kod na jednom miste. Definice entit v XML je v Hibernate tusim historicky jeste z dob pred 1.5, kdy Java anotace nemela.
Otázka anotace vs. XML se řešila třeba v tomhle podcastu.
Mapování v XML je mi sympatické z důvodu, že DTO třídy (přepravky) zůstávají „čisté“ – je to prostá struktura, která neví nic o tom, jak má být uložena do databáze (resp. že se vůbec bude do nějaké databáze ukládat) a to mapování se řeší mimo ni, je zcela řízeno z venčí. V distribuovaném prostředí můžu klidně takové objekty posílat na klienta a přitom spolu s nimi nešířím informaci, do jakých tabulek na serveru se entity ukládají (tuhle informaci klient nepotřebuje).
Na druhou stranu musím uznat, že mapování pomocí anotací v praxi často zvítězí a je pohodlnější – i za cenu toho, že nám trochu prosakuje abstrakce a máme závislost na JavaEE i tam, kde by být nemusela.
Posilat objekt z db vrstvy na klienta je mirne receno nestastne.
Proč?
resp. nikde není psáno, že bude s datovou vrstvou komunikovat přímo klient, mezi nimi bude typicky nějaká vrstva s obchodní logikou. To ale neznamená, že by se nesměly používat stejné třídy v datové vrstvě a na straně klienta. Když např. načtu z DB fakturu jako instanci nějaké třídy, tenhle objekt projde skrz obchodní logiku a klidně se dostane až do tlustého klienta. Bylo by naopak nesmyslné tyhle objekty „přebalovat“ do jiných objektů (instancí jiných tříd), které jsou ale vlastně stejné (jen neobsahují JPA anotace).
Samozřejmě existují případy, kdy se objekt má chovat v různých vrstvách aplikace jinak, tudíž se na různých vrstvách používají různé třídy (pro +/- stejná data), ale není to pravidlem. A minimálně se dá najít nějaké rozhraní nebo předek společný všem vrstvám.
Ak ta faktura, ktoru ste nacital z DB je model obchodnej logiky, tak ho prebalovat nemusite. V opacnom pripade vam nezostava nic ine len prebalovat. A to sme sa s datami nedostali k prezentacnej vrstve, kde mozu data faktury byt reprezeentovane uplne inak ako vyliezli z obchodnej logiky.
Ak mate aplikaciu, v ktorej z DB vrstvy az po klienta lieta jeden model (teda jeho objekty) asi vasa aplikacia nebude 3-vstvova ale s velkou pravdepodobnostou 2-vrstvova. Model specifikuje data ktore sa prenasaju medzi vrstvami.
DTO = Data transfer object je pattern, ktorý je zvyčajne používaný k tomu aby sa dáta s rôznych entít poskladali a presýpali do podoby v akej sa s nimi bude pracovať napríklad v prezentačnej vrstve. To o čom vravíte že má ostať čisté a nezanesené metainformáciami sú samotné Entity. Mýlite si dojmy a pojmy. V článku máte ukážku s persistence.xml, ktorá je súčasťou JPA, hneď nato ukážka z hibernate specific XML mapováku a hneď na to ich použitie s využitím entity managera, ktorý je opäť súčasť JPA. Seriál obsahuje kopu priveľmi zhustených informácii. Začiatočníka vyľaká a skúsenejší developer si to nájde v user guidoch.
Dobrý den, děkuji za pěkný článek. Považuji ho za důkaz toho, proč je Java kritizována: suma znalostí, kterou programátor musí nasát před napsáním jednoho řádku kódu je zbytečně veliká. Např. u .NET je to trochu lepší i když v posledních letech Microsoft dělá co může, aby Javu v tomto dohnal nebo dokonce předehnal. Ještě, že existuje třeba Python.
Zajímalo by mne, jaký dopad na rychlost chodu aplikace má použít Springu.
„Zajímalo by mne, jaký dopad na rychlost chodu aplikace má použít Springu.“
IMO v podstatě žádný, spíš má dopad na rychlost vývoje a kód se lépe udržuje.
ja napriklad neleziem do kvantovej fyziky lebo by ma to stalo vela namahy a mozno by som ju aj tak nepochopil, preto musim pouzivat na pochopenie sveta ine sposoby…
kritizovat nieco preto, ze sa nedajboze musim nieco naucit je podla mna uplne irelevantne…
k rychlosti: spring ako IOC kontainer vplyv na rychlost nema, lebo vsetku svoju robotu urobi pri inicializacii aplikacie a dalej uz nema co robit, pokial samozrejme nepouzivame nejake proxy alebo aop ale tam sa uz zucastnuju vacsinou tretie kniznice
jdbc template ma na rychlost urcite minimalny vply, kedze je to iba jednoduche template, teda presunutie logiky ktoru by pouzivatel napisal niekam inam
> k rychlosti: spring ako IOC kontainer vplyv na rychlost nema, lebo vsetku svoju robotu urobi pri inicializacii aplikacie a dalej uz nema co robit,
http://stackoverflow.com/questions/260618/orm-solutions-jpa-hibernate-vs-jdbc
Kto klame a kto ma pravdu?
Tam se ale porovnává JPA (Hibernate) s JDBC. Vliv Springu jakožto IOC kontejneru tam nijak analyzován není. Takže pravdu mohou mít oba.
A k porovnání Hibernate vs. JDBC: kdyby tamten onen původní tazatel nebyl líný a pustil si to v profileru, hned by zjistil, odkud vítr vane, a ještě by se ledacos přiučil (když už se dostal tak daleko, že testuje na výkon…)
Ano a program psaný v assembleru by běžel ještě rychleji :-)
Vždy je potřeba trefit vhodný poměr mezi rychlostí běhu a rychlostí vývoje (a udržovatelností, rozšiřitelností).
Presne tak. On hlavne Spring predstavuje lepidlo, ktere vam spoji ruzne frameworky – nic vic, nic min. A merit rychlost lepidla je blbost. Pekne je to popsano treba na http://blog.krecan.net/2007/10/19/je-spring-pomaly/
Naco mi je lepidlo, ked nechcem lepit.
Rychlost lepidla je blbost a teda sa nad meranim jeho rychlosti normalny clovek nepozastavy a presunie pozornost k tomu, preco sme do aplikacie dotiahli lepidlo.
Ak lepit chceme, potom riesime (v kontexte clanku tohoto seialu) otazku:
Spring/Hibernate/JPA alebo pure JDBC?
Jednu skusenost uz mame:
„I have done some comparison performance testing between Spring/Hibernate/JPA and pure JDBC. I have found a significant difference in performance using HSQL.. With Spring/Hib/JPA, I can insert 3000–4000 of my 1.5 KB objects (with a One-Many and a Many-Many relationship) in 5 seconds, while with direct JDBC calls I can insert 10,000–12,000 of those same objects.“
Ako pouzit JDBC, alebo Hibernate si citatel najde kdekolvek. Co ale urcite tak lahko nenajde je to, kedy a za akych okolnosti pouzit Spring/Hibernate/JPA a kedy pure JDBC. A toto mi prave v tejto casti serialu chybalo (nie kvoli sebe ale tym zaciatocnikom).
Tiez sa pridavam k nazoru ze tento serial urcite nie je vhodny pre zaciatocnikov.
Vzhladom na to, ze nas relacny model ma jednu tabulku o 3 stlpcoch je v java kode uz vazne riadny chaos.
tomáš (http://zdrojak.root.cz/clanky/java-na-webovem-serveru-prace-s-databazi-ii/nazory/7176/) ma asi pravdu.
> Jednu skusenost uz mame:
„I have done some comparison performance testing between Spring/Hibernate/JPA and pure JDBC. I have found a significant difference in performance using HSQL.. With Spring/Hib/JPA, I can insert 3000–4000 of my 1.5 KB objects (with a One-Many and a Many-Many relationship) in 5 seconds, while with direct JDBC calls I can insert 10,000–12,000 of those same objects.“
Neni nic receno jakym zpusobem byly objekty pres ORM vkladany. Zajimalo jestli to bylo pres NativeQuery.
BTW ani u ORM nejde o rychlost, ale zkuste si udrzovat bussines code pro mapovani tabulek na objekty kdyz jich mate desitky. Navic JPA ma v sobe cache ktera sice vsechno spomaluje, ale take omezuje zbytecne nacitani zaznamu z DB.
Zajimave ze kazdeho zajima jen rychlost a nic jineho.
Omlouvam se poranu pisu strasne :-)
Ad „Vzhladom na to, ze nas relacny model ma jednu tabulku o 3 stlpcoch je v java kode uz vazne riadny chaos.“
Ten „chaos“ je tu jednak proto, že v ukázce používáme 4 způsoby přístupu k databázi, které by se v reálné aplikaci vedle sebe nikdy neobjevily. A jednak proto, že se tenhle seriál tak trochu nese ve znamení „overengineeringu“ jelikož ukazuje, co se všechno lze použít, nikoli, co všechno se musí použít. V současné verzi je to hlavně technologická ukázka, i když to později hodlám dotáhnout do skutečné aplikace…
Nicméně je pravda, že Java trochu vyniká oproti ostatním platformám v možnostech volby – nic není nalajnované dopředu, vždy je na výběr X frameworků nebo postupů, neexistuje jediná správná cesta předurčená platformou. Vývojář je prostě častěji postaven před nutnost se rozhodovat a vybírat z více variant… ale nemyslím si, že by to bylo špatně.
Dovolim si poukazat na zlu koncepciu serialu.
Serial je maximalne povrchny a nepedagogicky napisany!
Este sa citatel nedozvedel poriadne ako riesit webove vstupy a vystupy, validaciu vstupov, ako riesit obchodnu logiku, a uz ho serial previedol (v jednej cast) dokonca viacerymi sposobmi ako nacitat data s primitivnej databazovej tabulky niekolkymi sposobmi. Ja uz tie sposoby trochu poznam a vazne sa musim sustredit a domyslat si aby som pochopil, co autor chce asi povedat. Zaciatocnik javu asi po tomto databazovom java masakri uz davno vzdal. :(
LENIN ma iny nazor, ale to je OK, lebo je to LENIN. On sa uz chvalil, ze si kupil super duper namakany procesor najal zopar expertov co spravia pracu za neho a tak ho vykon a kvalita aplikacie nezaujima. :)
Podla mojho skromneho nazoru som cakal nieco taketo:
– vysvetlit si ako sa riesi web komunikacia v jave – web kontajner, druhy, instalacia, sposob nasadenia, ukazka na referencnej implementacii (tomcat), ant (maven este asi nie, mozno neskor aby sme citatela neznechutili)
– lahky uvod o tom ze REST definuje sadu principov ako sa ma spravat dobre navrhnuta webova aplikacia, aby sme plynule prisli k servletu a pochopili preco je taky aky je
– servlet ako rozhranie, jeho mapovanie, vstupy a vystupy, validacia vstupov a vystupov
– JSP a reprezentacia dat, tag libraries
– teraz to iste ale v nejakom GUI nastroji, ktory nam ma pracu urychlit.
– zakladny prehlad frameworkov (aj z historickeho hladiska), ktore nam ulahcuju tvorbu web aplikacie (zatial iba webovej casti)
– ako riesit obchodnu logiku, model, vrstvenie aplikacie rozhrania obchodnej logiky a jej implementacia
– perzistencia dat, najskor si to spravime v nejakej in memmory forme ako struktury objektov modelu v pamati
– perzistencia dat, relacne databazy ako jedna z foriem storage pre perzistentne ukladanie dat (tu vymenime implementaciu in-memmory za DAO JDBC implementaciu)
– az teraz si mozeme povedat preco je tu ORM, na co je dobre a na co nie; jedno po druhom aby citatel vedel, kedy sa akemu venujeme
– a AZ TERAZ si mozeme nieco zlahka povedat o JavaEE
– co je to aplikacny kontajner a na co nam je, aky je jeho vztah ku servletovemu kontajneru, ake su jeho slabosti. Instalacia a konfiguracia glassfish ako serveru a nie obskurne ako sucast netbeans!
– …
Mozno som to nespisal vsetko a nieco som zabudol, ale hlavnu liniu serialu som snad naznacil.
Tento prispevok v ziadnom pripade nema za ciel spochybnit profesionalitu autora, ale serial zial naznacuje opak.
Aj napriek mojim vyhradam priznavam, ze som sa zo serialu dozvedel veci, ktore som si doposial poriadne neuvedomil.
Napiseme spolocne takyto serial? Kostru to ma dobru!
Pravdupovediac, netrufam si. Je to na celu knihu. Cudujem sa, ze s takym obsahom este nikto nic nenapisal, alebo som sa k nej nedostal.
Napisat taky serial nie je sranda, aj ked si to autor tohoto serialu asi nemysli. :(
Zial serial aj prispevky k nemu (ale i napriklad k serialu o Flexe) su odrazom realneho a zalostneho stavu nepochopenia IT.
Moja predstava vyvoja web aplikacii je nejaka takato: http://prest.sourceforge.net/
Ano souhlasim s Vami. Mam pocit ze serial je napsany Javistou pro ostatni Javisty, tak aby si mohli o necem povidat. Me cloveku, ktery by rad vyzkousel Javu a rad by na ni presel z PHP je uplne k nicemu. Je to jako bych navstivil jednu z prednasek fyziky na CVUT a prednasejci se mi snazil vnutit nazor ze takto se o probirane latce dovim nejvice.
Chce to znat zaklady Javy SE, umet ten jazyk – serial te nauci tu EE nadstavbu, ale opakovat tu zaklady jazyka, to bychom se daleko nedostali
> serial te nauci tu EE nadstavbu
To myslite vazne? Ved serial nam este ani nepovedal co to vlastne ta JavaEE je a ako sa lisi od JavaSE.
Serial sa vola „Java na webovém serveru“, Vy tam vidite „Java na EE kontajneri? :)
Hovorite si Javista. Skutocne nim aj ste?
Pripominate mi jedneho byvaleho kolegu, on nevedel programovat ani v tej Jave, ale pracoval na pozicii Senior Java Developer. Teraz asi prisiel aj novy zamestanvatel na to, ze Jave nerozumie tak ho prerobili na Senior Business Analyst. :)
Ked prisli na to, ze vazne programovat nedokaze, jeho vyhovorkou bolo: „Teoreticky informatik nemusi vediet programovat!“ :-)
Samozrejme, tato moznost volby je nejvetsi devizou Javy. Sice klade na vyvojare/architekta vice naroku, ale proto se dle mych zkusenosti na enterprise aplikace pouziva prave Java – prave diky prizpusobitelnosti pomoci ruznych frameworku, ktere spolu diky JSR specifikaci nebo Springu funguji. Kdyz investujete do IT balik $$$, tak vas zatracene zajima, jake jsou moznosti budouciho smerovani vyvoje. Jinak kdo chce delat v nalinkovanem technology stacku, necht sahne bud po cistem JEE 5 nebo po .NET, kde moznost volby prakticky neexistuje.
Ono je to dost relativni – jasne, na zacatku se musite neco terorie naucit, ale dalsi vyvoj je uzasne rychly. Je to proste opak PHP nebo C/C++, kde vam staci pochopit zakladni syntax a pripadne pointery, zato kvuli kazde blbosti popisete stovky radek kodu. Navic s pouzitim treba takovych NetBeans, Eclipse nebo InteliJ IDEA je to fakt hracka, nebot tato IDE vas v podstate navadeji a zobrazuji primo klikatelny JavaDoc jako kontextovou napovedu.
Domnívám se, že tohle pohádka. Myslím to o rychlosti programování po nasátí teorie u Javy. Ty opravdu úspěšné aplikace na webu jsou postaveny v naprosté většině na technologiích jako PHP, Python a dříve Perl. Určitě existují výjimky. Moc jich ale nebude. Myslím, že Java bude rekordmanem v počtu nedokončených projektů, které se nepodařilo ufinancovat, protože aplikace se nikdy nedostaly na světlo světa.
Java má podle mne jednu výhodu: aby jste ji zvládl, musíte být dobrý programátor. Tedy pro zaměstnavatele dobrý filtr.
Vedl jsem jako architekt projekty v Javě a .NET. Java byla na dokončení nejsložitější. Kupodivu i na údržbu, protože bylo složité sehnat někoho, kdo by všem potřebným knihovnám rozuměl a mohl na tom pracovat. Dnes dělám architekta na projektu v Pythonu. Jako jazyk se mi více líbí C#, ale Microsoft směřuje do složitosti Javy. Java a pomalu i .NET jsou možná dobré pro velké týmy, kde nějaká koruna a měsíc nehraje roli. To není náš případ.
To by chcelo
a) nejaké štatistiky
b) nejaké štatistiky :-)
Zohnať dobrého Pythonistu je imho rovnako netriviálne ako zohnať dobrého Javáka. Javistov je opticky viac, koľko je dobrých, netrúfam povedať.
Suhlasim s vami.
Ono ta zlozitost Javy nie je velka, pokial robite web aplikaciu normalne a nie sposobom, ze si do aplikacie dotiahnete cely EE stack (vid tento serial) a potom aby sa nepovedalo sa ho snazite vyuzit.
V podnikovej sfere su architekti s mozgami vymytimi na seminaroch Oracle a im podobnych. A ako im natlacili do hlavy ze EE produkty im nahradia nutnost riesit architekturu, co je samozrejme blbost, tak aj robia. Ale ked to zakaznikovi dojde ze to nie je pravda, je uz poriadne loknuty a o to predsa islo. :)
No a manageri predsa nepriznaju, ze spravili chybu. Oni chyby nerobia. :)
Java ma na serveri vyborny vykon, samozrejme v pripade ze plati co som napisal vyssie o tom stacku.
Zazitok z praxe:
Architekt od SUNu nam predvadzal novu BPM sprasenimu. Ked som sa spytal, ci si uvedomuje, ze jeho Hello World aplikacia je perzistentna voci SQL injection, otvoril usta dokoran a povedal: „Neviem o com hovorite“. Potom som sa ho spytal aky ma postoj k RESTu, otvoril este vacsie usta a znova: „Co je to REST, neviem o com hovorite“. Tak sa to zopakovalo este par krat. Skratka SUN poslal zleho cloveka.
Architekt od IBM povedal ze REST je cutting edge technologia a ze to oni nerobia. To bolo tak rok dozadu.
Ad REST: je to dobrá věc – ale jako vždy platí: pokud se používá na správném místě – někdy se totiž setkávám s opačným extrémem – lidi si řeknou: „REST teď frčí, tak ho budeme používat všude“ a snaží se ho napasovat i na úlohy, kde se fakticky volají vzdálené procedury, ale aplikace se přiohne, aby z toho bylo CRUD :-) Ono to funguje, což o to, ale takový návrh postrádá logiku.
Ad BPM sprasenina: to je taková chiméra některých analytiků, představa, jak se nakliká proces a ten pak ožije nad BPM serverem a pod tím bude ta SOA a nebude potřeba nic programovat a až si člověk z byznysu usmyslí, že proces bude vypadat jinak, jen přetahá myší ty spojnice jinak a proces bude žít zase jiným způsobem. Mluví se o tom už dlouho, prezentace na toto téma na konferencích jsou opravdu vypilované… ale jestli je to k užitku, to uvidíme tak za deset let :-)
> lidi si řeknou: „REST teď frčí, tak ho budeme používat všude“ a snaží se ho napasovat i na úlohy, kde se fakticky volají vzdálené procedury, ale aplikace se přiohne, aby z toho bylo CRUD :-) Ono to funguje, což o to, ale takový návrh postrádá logiku.
Pokial sa jedna o webove aplikacie a webove sluzby, REST definuje cisty a jediny sposob. Vznikol koli tomu, ze Enterprise ludia pouzivali HTTP ako sa nema, ako transportny protokol (vid SOAP). Da sa robit aj RPC over HTTP, co je vdy lepsie a cistejsie a hlavne jednoduchsie ako napr. SOAP.
> Mluví se o tom už dlouho, prezentace na toto téma na konferencích jsou opravdu vypilované… ale jestli je to k užitku, to uvidíme tak za deset let :-)
Ti sikovnejsi vidia uz dnes. Za tych par rokov BPM uz ukazalo coho je schopne. :)
„pouzivali HTTP ako sa nema, ako transportny protokol“
Souhlas, ale za to můžou administrátoři, kteří na síti zakazují* kde co – a vývojářům pak nezbude než tunelovat skrz HTTP, pokud chtějí, aby jejich aplikace fungovala všude (což je potřeba, má-li být obchodně úspěšná).
Lidi z „enterprise“ světa si WS nevymysleli jen tak pro nic za nic – měli k tomu racionální důvod – jinak to prostě nešlo – když je Internet všude kolem (mezi firmou a jejími zákazníky/partnery) zatarasený nesmyslnými zákazy (mnohdy nic jiného než HTTP/HTTPS přes síť neprojde). Třeba taková CORBA/IIOP by byla moc fajn, ale bohužel dnešní svět tomu nepřeje a musí se všechno** hnát přes HTTP. Jak z toho ven?
Co se týče „RPC over HTTP“
jedná se o úplně stejné překroucení (zneužití) HTTP protokolu jako třeba u webových služeb (WS). Protokol se tu nepoužívá k přístupu ke zdrojům (natož k hypertextu, což je původní smysl), ale v volání vzdálených procedur.
*) ve výsledku se tam Internet smrskává (aspoň v očích uživatelů) z té pestré škály protokolů na pouhý web (a přes něj tunelované další věci).
**) což vlastně popírá smysl těch původních zákazů (nastavení firewallu), které umožňují jen HTTP provoz.
Co sa tyka zakazovania portov sietovimi administratormi, skusme hladat dovod, ktory ich k tomu nezmyselnemu spravaniu vedie.
Zacalo to kdysi davno, ked som sa zabaval s pingom smrti ako kopa mne podobnych. Na vine je MS Windows a ich pristup k bezpecnosti – totalny firewall. Tiez man vo firme nariadili vsetko zahatat, aby sa nasim ubohym produktom MS podarilo aspon prezit nejaky ten cas bez preinstalovania. :(
A ked ostal jediny port otvoreny na FW, tak MS vymyslel XML-RPC a este v tom istom roku SOAP (simple object access protocol), ktory neskor neuveritelne napuchol, stal sa protocol agnostic a museli ho premenovat na SOAP (service oriented architecture protocol). Je cas vycuvet z tejto slepej SOAP ulice, minimalne co sa tyka webovych sluzieb.
No ta CORBA je predsa len prilis akademicka a zlozita a to bolo asi jej dalsie minus.
Na newebove sluzby by sa mi celkom pacil sposob akym funguje D-Bus. Akurat keby bol rozsiremy o komunikaciu medzi hostami, nie len lokalne. Je oproti CORBA jednoduchsi, ma navyse nejake veci, ktore CORBA nema, je to binarny prenos dat a teda je efektivny.
perzistentna voci SQL injection? Tak tejto jazykovej konštrukcii nerozumiem ani ja.
Mea culpa. Hlboko sa ospravedlnujem, ze som napisal tak nemoznu frazu.
Je tak nemozna, ze dokonca ani Mayo ju nedokazal pochopit, nieto este normalni ludia. :)
Myslel som: „zranitelna voci utoku typu SQL injection“.
Treba sa spýtať Igigiho čo tá konštrukcia znamená, veď na SQL Injection spravil kariéru :)
…suma znalostí, kterou programátor musí nasát před napsáním jednoho řádku kódu je zbytečně veliká. …
100% s Vami souhlasim, je nadherne zjistit, ze jeste existuji rozumni lide na tomto svete …
+1
Ako by to vyzeralo v Pythone? Zrejme by sa použil nejaký existujúci framework, nie?
Použitie Springu má minimálny dopad, Spring-JDBC je len lepšie API k pôvodnému JDBC. Ako už ktosi povedal vyššie, Spring len sprehľadňuje kód a uľahčuje testovanie.
Hlavně je potřeba rozlišovat mezi Springem jakožto frameworkem a tím JdbcTemplatem, který jsme použili v tomto příkladě – to je jen malý kousíček Springu a nevytváříme při tom ani springový kontext.
Hej, to je pravda, v prvom čítaní som bol v šoku, ako sa dá natlačiť Spring a Hibernate do jedného článku, ale JdbcTemplate je pohodlne použiteľný aj bez aplikačných kontextov, beanov a podobne.
Predstavte si hypotetickou situaci. Uz mate cely projekt hotovy a nasazeny a zjistite ze je to cele desne pomale. Z databaze vytahnete nejake statistiky, ktere vam reknou, ze: vase aplikace spousti hlavne SQL statementy x, y a z. Ze x casto ceka na y. Ze z se pousti vice nez 100000× za hodinu a ze se v prumeru 30% transakci rollbackuje. Ja z techle informaci zjistite kam do zdrojaku sahnout a co tam mate zmenit? Cim dal casteji se setkavam s „vymluvou“ je programatori vlastne nic nedalaji, ze to vsechno za ne udelala nejaka mezivrsta, a tudiz neni mozne na strane aplikace neco menit nebo investigovat.
Medzivrstva = Hibernate / JPA?
Filozofická otázka. Přidávání dalších vrstev je proces, kterému se asi není dobré bránit. Vadí dnes někomu, že pořádně neví, jak FS ukládá data? Nebo jak DB ukládá data? (v některých případech přes FS, i když to není ideální.) Brání to nějak zásadně výkonu? Asi ne.
Podobně věřím, že v budoucnu nebude problém přidat další vrstvy. Samozřejmě, vrstva by měla být nějak dobře odladěná a nabízet dostatečně dobrou dokumentaci výkonu, tak to těžko může pořádně vadit. To je IMHO i důvod prosazení RDBMS.
K tématu: http://blog.krecan.net/2010/02/02/slava-abstrakci/
Proc jsi vlastne vubec pouzil Hibernate? GF v3 ma vlastni implementaci JPA a to dokonce tu referencni (EclipseLink). Konfigurace treba napriklad Spring aplikace se sestava z malinkeho persistence.xml, jednoho <jee:jndi-lookup /> tagu (nebo dvou, v pripade potreby UserTransaction) v kontextu a podedeni DAOcek z JpaDaoSupport. Tot vse.
V clanku pro zacatecniky je uz tak dost informaci na vstrebani, Hibernate bych do toho vubec netahal ;)
Jeste detail: JpaDaoSupport je deprecated, ale alternativni reseni Spring ma.