
SpiderMonkey: zpracování JavaScriptu ve Firefoxu

Tímto dílem seriálu o interpretech JavaScriptu zahajujeme část věnovanou interpretu SpiderMonkey. Dnes si ho představíme a popíšeme si, jak v něm probíhá zpracování javascriptového kódu. Pozastavíme se také nad jeho reprezentací hodnot a optimalizacemi, které umožňují efektivní práci s řetězci a poli.
Seriál: Do hlubin implementací JavaScriptu (14 dílů)
- Do hlubin implementací JavaScriptu: 1. díl – úvod 30. 10. 2008
- Do hlubin implementací JavaScriptu: 2. díl – dynamičnost a výkon 6. 11. 2008
- Do hlubin implementací JavaScriptu: 3. díl – výkonnostně nepříjemné konstrukce 13. 11. 2008
- Do hlubin implementací JavaScriptu: 4. díl – implementace v prohlížečích 20. 11. 2008
- Do hlubin implementací JavaScriptu: 5. díl – implementace mimo prohlížeče 27. 11. 2008
- SquirrelFish: reprezentace hodnot JavaScriptu a virtuální stroj 4. 12. 2008
- SquirrelFish: optimalizace vykonávání instrukcí a nativní kód 11. 12. 2008
- SquirrelFish: regulární výrazy, vlastnosti objektů a budoucnost 18. 12. 2008
- SpiderMonkey: zpracování JavaScriptu ve Firefoxu 8. 1. 2009
- SpiderMonkey: rychlá kompilace JavaScriptu do nativního kódu 15. 1. 2009
- V8: JavaScript uvnitř Google Chrome 22. 1. 2009
- Rhino: na rozhraní JavaScriptu a Javy 29. 1. 2009
- Velký test rychlosti JavaScriptu v prohlížečích 5. 2. 2009
- Javascriptové novinky: souboj o nejrychlejší engine pokračuje 19. 3. 2009
Připomenutí a stručná historie
Jak jsme si říkali již ve čtvrtém dílu seriálu, SpiderMonkey je přímým potomkem úplně prvního interpretu JavaScriptu. Ten se objevil v prohlížeči Netscape Navigator 2 v roce 1995 a jeho autorem byl samotný tvůrce JavaScriptu Brendan Eich. Kód interpretu byl později z Navigatoru převzat do projektu Mozilla a zveřejněn jako open source. Dnes SpiderMonkey najdeme ve Firefoxu a ve všech dalších prohlížečích založených na renderovacím jádru Gecko.
Vývoj interpretu byl zpočátku poměrně bouřlivý a v době válek prohlížečů přibývaly s každou verzí mnohé nové funkce (ono není divu, když například ještě JavaScript 1.2 neměl příkazy do…while a switch). Po ukončení vývoje klasického Netscape Navigatoru se situace poněkud uklidnila, ale i tak vývojáři implementovali různé menší novinky, z nichž asi nejvýznamnější je podpora E4X.
Postupem času se webové aplikace začaly stávat stále závislejší na JavaScriptu a začínala jim vadit jeho pomalost. Vývoj SpiderMonkey proto v poslední době opět ožil. Vývojáři zapracovali na různých optimalizacích a hlavně na kompilaci do nativního kódu, která bude mít svou premiéru ve Firefoxu 3.1.
Historické verze
Zajímavostí SpiderMonkey je, že při jeho kompilaci lze přesně zvolit, s jakou verzí JavaScriptu má být kompatibilní. Podle zvolené verze se nastaví různá makra jazyka C, což ovlivní na mnoha místech chování kódu interpretu a (ne)podporu funkcí přidaných v novějších verzích jazyka.
V dřívějších verzích SpiderMonkey bylo možné emulovat i archaické verze JavaScriptu jako je 1.1, dnes ale nejnižší podporovaná verze odpovídá 3. edici specifikace ECMA-262. Nejvyšší podporovaná verze JavaScriptu je 1.8, která je obsažena ve Firefoxu 3.
Volba verze JavaScriptu při kompilaci interpretu je doplněna ještě volbou verze jazyka konkrétního skriptu při jeho interpretaci. Tato funkce se využívá při implementaci atributu type HTML elementu <script>, kde může být verze JavaScriptu explicitně uvedena:
<script type="application/javascript;version=1.8"> V současnosti číslo verze skriptu ovlivňuje prakticky jen to, zda budou identifikátory yield a let (zavedené v JavaScriptu 1.7) chápány jako klíčová slova s odpovídajícím významem, nebo nikoliv.
Zdrojový kód
Většina SpiderMonkey je napsána v jazyce C, některé menší části (především kompilace do nativního kódu) v C++. Novější interprety jako SquirrelFish nebo V8 volí jako implementační jazyk čisté C++, ale použití klasického C ve SpiderMonkey dle mého názoru vůbec nevadí. Jazyk C naopak díky větší explicitnosti usnadňuje porozumění zdrojovému kódu. Ten je mimochodem poměrně přehledný a (na rozdíl od ostatních javascriptových interpretů, které jsem zkoumal) velmi kvalitně zdokumentovaný. Zkrátka radost číst.
Zpracování JavaScriptu interpretem
Samotné zpracování zdrojového kódu v JavaScriptu ve SpiderMonkey začíná vygenerováním abstraktního syntaktického stromu (AST) pomocí ručně napsaného lexikálního analyzátoru a parseru (klíčové slovo pro znalce: rekurzivní sestup). Nejsou tedy použity žádné nástroje typu lex/yacc, což pravděpodobně souvisí s poněkud nepravidelnou gramatikou jazyka a výkonem.
Po sestavení stromu je na něm aplikován constant folding a vyhodnotí se výrazy, jejichž hodnoty je možné určit už při kompilaci. Následně je z AST jednoduchým průchodem vygenerován bajtkód.
Bajtkód
Bajtkód SpiderMonkey je poměrně vysokoúrovňový – jeho instrukce přibližně odpovídají jednotlivým operacím jazyka. Délka instrukcí je proměnlivá. První bajt instrukce obsahuje opkód (kód instrukce), za ním následují nejvýše čtyři bajty operandů. Výjimkou jsou instrukce implementující příkaz switch, které mohou mít operandů libovolné množství.
Oproti bajtkódu SquirrelFish, který jsme popisovali dříve je bajtkód SpiderMonkey kompaktnější a vzhledem ke krátkým opkódům na něj nelze aplikovat techniku direct threading, používanou u SquirrelFish (ta vyžaduje, aby byly opkódy instrukcí stejně dlouhé jako ukazatele na dané platformě, což u SpiderMonkey neplatí).
Zajímavé je, že bajtkód obsahuje kromě instrukcí dodatečné informace, které umožňují poměrně věrnou dekompilaci bajtkódu do podoby původního zdrojového kódu. Například u instrukcí JSOP_IFEQ a JSOP_IFEQX, které znamenají podmínku, je poznamenáno, jestli daná instrukce vznikla kompilací příkazu if nebo ternárního operátoru. Těchto dodatečných informací se hojně využívá především při volání metody Function.prototype.toSource.
Interpretace
Instrukce bajtkódu jsou interpretovány zásobníkovým virtuálním strojem. K dispatchingu instrukcí je využíván příkaz switch, který větví kód podle jednotlivých opkódů instrukcí – viz dřívější obecný popis.
Na podporovaných kompilátorech (gcc 3+, IBM C, SunPro C) je k urychlení dispatchingu použita technika indirect threading (neplést s direct threadingem, který používá SquirrelFish). Spočívá v přidání skoku přímo na kód zpracovávající další instrukci na konec každé větve příkazu switch. Větvení se tak vykoná pouze jednou, dál se skáče podle speciální tabulky mapující opkód instrukce na zpracovávající kód. Nejdůležitější výhodou je to, že skok na kód zpracovávající následující instrukci se nachází na více místech, což dává procesoru šanci skoky lépe predikovat. Výsledkem je urychlení vykonávání kódu o 10–20 %.
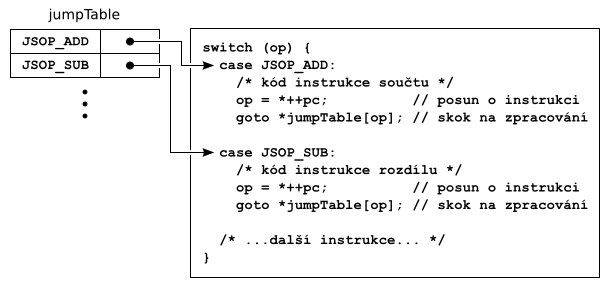
Smyčka interpretu využívající indirect threading.
Od února 2008 interpret podporuje polymorfní inline cache urychlující přístup k vlastnostem objektů, a tedy i volání metod. Principy jejího fungování jsme si popsali v minulém dílu seriálu.
Reprezentace hodnot
Jak jsme si říkali již u popisu interpretu SquirrelFish, jedno z důležitých rozhodnutí při návrhu interpretu je, jak reprezentovat hodnoty interpretovaného jazyka v jazyce implementačním.
SpiderMonkey ukládá javascriptové hodnoty jako céčkový typ jsval, což je celé číslo stejně velké jako ukazatel na dané platformě. Typ uložené hodnoty je určen nejnižším bitem tohoto čísla. Pokud je nejnižší bit nenulový, ve zbývajících bitech jsvalu je uloženo celé číslo reprezentující hodnotu javascriptového typu Number. V opačném případě (nejnižší bit je nulový) se typ uložený v jsvalu pozná podle druhého a třetího nejnižšího bitu.
Hodnoty typů Undefined, Null a Boolean jsou uloženy přímo v jsvalu. Hodnoty typu Number, které nejsou dostatečně malá celá čísla, a hodnoty typu String a Object jsou uloženy jako ukazatele na složitější struktury. Snaha uložit hodnoty často používaných typů přímo do jsvalu je motivována rychlostí – šetří se tak dereference ukazatelů.
Přesnou reprezentaci všech typů jazyka JavaScript přehledně znázorňuje následující obrázek.
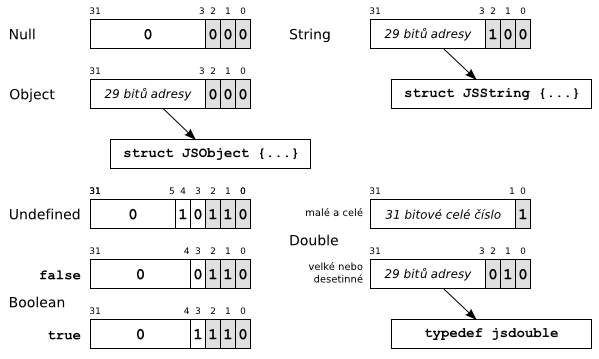
Reprezentace typů JavaScriptu ve SpiderMonkey (na 32bitovém stroji).
Pozorní čtenáři předchozích dílů našeho seriálu si možná povšimli, že až na bitové signatury je ukládání hodnot ve SpiderMonkey vyřešeno prakticky stejně jako ve SquirrelFish. Nevím, zda zde od sebe interprety opisovaly, ale pokud ano, opisujícím byl určitě novější SquirrelFish.
Optimalizace některých typů
SpiderMonkey poměrně důkladně optimalizuje operace s některými datovými typy – konkrétně s řetězci a s poli.
Ukládání řetězců
U řetězců se interpret snaží zamezit zbytečnému kopírování. Dociluje toho tak, že buffer s jejich znaky může ve skutečnosti sdílet několik řetězců. Jeden z nich je vlastník bufferu a obsahuje ukazatel na něj (spolu s dalšími údaji jako délka a různé příznaky). Další řetězce jsou na vlastníkovi závislé a místo ukazatele na buffer obsahují pouze odkaz na vlastníka.
Závislý řetězec může využívat celý buffer (např. pokud vznikne kopií vlastníka) nebo jeho část (např. pokud vznikne z vlastníka voláním metody substring). Vzhledem k tomu, že řetězce jsou v JavaScriptu neměnné (immutable), není třeba řešit, co se stane, když jeden z řetězců sdílejících společný buffer bude chtít modifikovat jeho obsah. Sdílení bufferů tak pouze mírně komplikuje rozhodování, kdy je možné buffer uvolnit.
Přístup k položkám pole
Pole v JavaScriptu se sémanticky téměř neliší od obyčejných objektů. Jediným rozdílem je přítomnost vlastnosti length, která obsahuje délku pole. Vlastnost length je automaticky aktualizována při nastavení vlastnosti s číselným indexem větším než je doposud nejvyšší použitý index v poli. Ruční zmenšení hodnoty length pak způsobí smazání vlastností s číselným indexem větším nebo rovným nové hodnotě length. Do pole je stále možné ukládat vlastnosti indexované nečíselnými hodnotami – ty hodnotu length nijak neovlivňují.
a = ["a", "b", "c"];
alert(a.length); // vypíše "3"
a[5] = "d"; // vlastnost s číselným indexem ovlivní délku pole
alert(a.length); // vypíše "6"
a["str"] = "e"; // vlastnost s nečíselným indexem neovlivní délku pole
alert(a.length); // stále vypíše "6"
a.length = 2;
alert(a[2]); // vypíše "undefined" Otázkou je, jak položky pole ukládat. Pro vlastnosti indexované nečíselnými hodnotami je zřejmě nutné použít hash tabulku, co ale s vlastnostmi indexovanými čísly? Pokud bychom i pro ně použili hash tabulku, byla by práce s polem pomalá. Pokud bychom ale použili céčkové pole, může nastat problém s jeho velikostí – pole „a“ v následujícím příkladu, které obsahuje jen dvě položky, by například na 32bitovém stroji zabralo přes 4 MB prostoru:
a = [];
a[0] = 1;
a[1024 * 1024] = 2; SpiderMonkey nastíněné problémy řeší tak, že pole ukládá dvěma různými způsoby. V prvním režimu, zvaném dense array, jsou podporovány jen vlastnosti indexované čísly, které jsou ukládány do céčkového pole. Ve druhém režimu, zvaném slow array, jsou podporovány i vlastnosti indexované nečíselnými hodnotami a všechny jsou ukládány do hash tabulky.
Každé pole začne svůj život v prvním režimu (ukládání v poli) a zůstane v něm, dokud jsou do pole přidávány pouze číselné vlastnosti tvořící „dostatečně souvislou řadu“. Jakmile je přidána vlastnost indexovaná nečíselnou hodnotou, nebo při přidání vlastnosti indexované číslem počet neobsazených číselných vlastností v poli přesáhne 75 % alokované kapacity, pole se přepne do druhého režimu (ukládání v hash tabulce) a zůstane v něm už navždy. (Pravidlo pro přepnutí je ve skutečnosti malinko složitější, podrobnosti lze najít ve zdrojovém kódu.)
Sečteno a podtrženo: dokud je pole používáno jako opravdové pole, bude přístup k jeho položkám rychlý. Jakmile začneme využívat toho, že v něm lze indexovat i nečíselnými hodnotami, nebo budeme používat příliš nesouvislé číselné indexy, začne fungovat pomaleji.
Ostatní implementace
Nutno dodat, že optimalizace ukládání řetězců i polí nejsou nijak specifické pro SpiderMonkey. Variace na ně jsou implementovány minimálně ještě v interpretech SquirrelFish a V8. Dvojí způsob ukládání polí používají i interprety některých dalších jazyků, kde asociativní pole slouží zároveň jako pole klasické (například Lua).
Co nás čeká příště
V příštím dílu se budeme ještě stále věnovat SpiderMonkey. Podíváme se na jeho aktuální vývojovou verzi TraceMonkey a představíme si trace trees – poměrně zajímavou techniku selektivní kompilace do nativního kódu.
Zdroje
- SpiderMonkey – domovská stránka dokumentace interpretu
- SpiderMonkey Internals – popis architektury a vnitřností
- JSAPI User Guide – popis API a vkládání do aplikací
- The Implementation of Lua 5.0 – popis implementace jazyka Lua, obsahuje mj. popis hybridního ukládání položek polí
David Majda
Autor je vývojář se zájmem o programovací jazyky, webové aplikace a problémy programování jako takového. Vystudoval informatiku na MFF UK a během studií zde i trochu učil. Aktuálně pracuje v SUSE.



Přikládám obligátní poděkování za technicky zdatný článek který se jen neklouže po povrchu.